The calculation script of time series data must have strong orderly computing ability , This article carefully selects three of these tools , From development efficiency 、 The ability of grammatical expression 、 Structural function library and other aspects of in-depth comparison , The calculation of the serial number of each script is examined 、 Relative position calculation 、 The performance of key operations such as the calculation of ordered sets ,esProc The best performance of these tools . Click on Calculation script suitable for time series data Learn more .
Time series data here refers to daily business data sorted by time . When calculating time series data , It's not just about the quarter 、 month 、 Working day 、 Weekend and other routine calculations , We often encounter more complex ordered operations , This requires that the script language should have the corresponding computing power . Commonly used to process time series data calculation scripts are SQL、Python Pandas、esProc, Let's take a closer look at these scripts , Look at the differences in their abilities .
SQL
SQL It has a long history and many users , Within the framework of its model, it has developed to the limit , Almost every simple operation can find the corresponding SQL solution , This includes ordered operations .
For example, compared with the example in the previous issue : surface stock1001 Store trading information about a stock , The main fields are transaction date transDate、 Closing price price, Please calculate the growth rate of the closing price of each trading day compared with the previous trading day .
This example belongs to relative position calculation , If you use the window function ,SQL It's relatively easy to write :

But some of the SQL Window functions are not supported , The realization will be much more troublesome than the previous period :
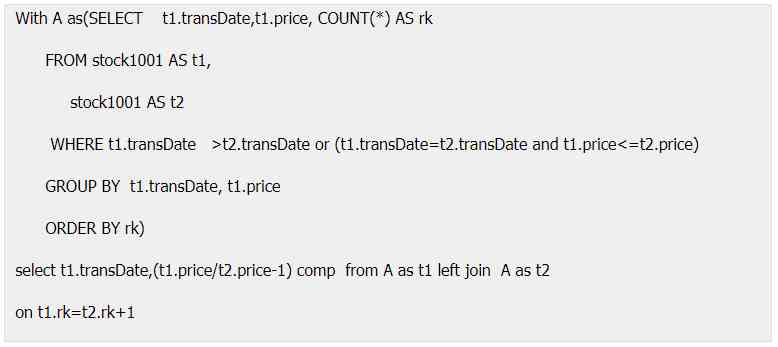
The trouble with the above code , First of all, because SQL It's based on unordered sets , It has no serial number , It is not convenient to carry out ordered operations , In order to implement ordered operations , We're going to have to make a sequence number column for an unordered set , This process requires self correlation and grouping , The code is more complex . secondly , Compared with the previous period, it belongs to the calculation of relative position , If SQL There is a relative serial number , This calculation will be much simpler , but SQL There is no relative serial number , Only the previous line can be associated with this line , Realize adjacent position calculation in disguise , So the code becomes complicated .
Based on unordered sets SQL It is not convenient to realize ordered operation , Window function can alleviate this situation , But if the operation is more complicated , It's still troublesome .
For example, in the case of the median :scores Tables store student grades , The main field has student number studentdid、 Math scores math, Please calculate the median of your math scores . The median is defined as : If you record the total number L For the even , Return the mean value of the middle two values ( The serial numbers are L/2 and L/2+1); If L It's odd , The unique intermediate value is returned ( Serial number is (L+1)/2).
SQL The code for calculating the median :

You can see , Although the function window has been used , but SQL It's still complicated . The process of generating sequence numbers is redundant for ordered sets , But yes SQL It's an essential step , Especially in this case where the serial number has to be explicitly used , This makes the code complex .SQL It is also troublesome to realize branch judgment , So for L When dealing with odd numbers , It doesn't return a unique intermediate value , It's about averaging two identical intermediate values , This technique can simplify branch judgment , But it's a little bit difficult to understand .
If you use the rounding function , You can skilfully skip the judgment process , Simplify the code and calculate the median . But this technique is different from the original definition of the median , It's going to make it difficult to understand , There is no use of .
Let's take a more complicated example : Days of continuous rise . Library table AAPL Store stock price information of a stock , The main fields are transaction date transDate、 Closing price price, Please calculate the longest continuous rise days of the stock .SQL as follows :

When you do this in a natural way , Stock records with orderly dates should be rotated , If this record is higher than the previous record , It will continue to rise for days ( For the initial 0) Add 1, If it's down , Then it will continue to rise days and the current maximum continuous rise days ( For the initial 0) comparison , Select the new current maximum continuous rise days , Then clear the days of continuous rise 0. So the cycle ends , The current maximum continuous rise days is the final maximum continuous rise days .
but SQL Not good at ordered Computing , Can't be realized with the above natural ideas , You can only use some difficult skills . Divide the stock records in chronological order into groups , The record of consecutive gains is divided into the same group , in other words , The stock price of one day is higher than that of the previous day , They were assigned to the same group as the previous day's records , If it goes down , Start a new group . Finally, look at the maximum number of members in all groups , That is, the maximum number of consecutive days of increase .
For these two slightly more complex examples of ordered operations ,SQL It's very difficult to implement , Once you encounter more complex operations ,SQL Almost impossible to complete . The reason for this result , Because SQL The theoretical basis of the theory is the disordered set , This natural defect, however patched , Can't fundamentally solve the problem .
Python Pandas
Pandas yes Python Structured Computing Library of , It is often used as a calculation script for time series data .
As a library of structured computing functions ,Pandas You can easily implement simple ordered Computing . such as , The same calculation compared with the previous issue ,Pandas The code looks like this :

The first two sentences above are for reading data from a file , The core code has only one sentence . It should be noted that ,Pandas It doesn't mean the previous line , So as to realize the relative position calculation directly , But you can use shift(1) Function moves the whole column down one line , Thus the relative position calculation can be realized in disguise . Lines and columns in the code 、 The previous line and the next line look like , Beginners are easy to confuse .
As a modern programming language ,Pandas It's better than in ordered computing SQL advanced , Mainly reflected in Pandas Building on ordered sets ,dataFrame Data types are inherently ordinal , It's suitable for sequential computation . The earlier, more complex, ordered calculations , use SQL It will be very difficult , use Pandas It's relatively easy .
Also calculate the median ,Pandas The core code is as follows :

In the above code ,Pandas It can be used directly \[N\] Indicates the serial number , Instead of making additional serial numbers , The code is thus simplified . secondly ,Pandas It's procedural language , Branch judgment ratio SQL Easy to understand , It doesn't take a trick to simplify the code .
In the case of the same more complicated case, the longest consecutive rise days ,Pandas Is better than SQL Easy to implement . The core code is as follows :

In this case ,Pandas It can be realized in a natural way , You don't have to use difficult techniques , Code is more efficient than SQL Much higher .
It's a pity , Ordered computation often involves the calculation of relative position , but Pandas Can't express relative position directly , You can only move the column down one row to disguise the line above the line , It's a little difficult to understand .
Pandas In terms of ordered computing, it's really better than SQL It's easier , But in more complicated situations ,Pandas And it's going to be cumbersome , Here are two examples .
For example, the example of filtering cumulative values : surface sales Store customer sales data , The main fields are customers client、 sales amount, Please find out the top half of the total sales n A big client , And sort by sales in descending order .Pandas The code is as follows :

Another example is to calculate the highest stock price 3 Day's increase : surface stock1001 Store the daily share price of a stock , The main fields are transaction date transDate、 Closing price price, Please rank the top three days in reverse order , Calculate the increase of each day over the previous day .Pandas The code is as follows :

These more complex examples also require some difficult techniques to implement , Not only is it difficult to write , And it's hard to read , I won't explain it in detail here .
esProc
And Pandas similar ,esProc It also has rich structured computing functions , And Pandas The difference is ,esProc In addition to being based on ordered sets and supporting ordinal mechanisms , It also provides a convenient adjacency reference mechanism , And a wealth of location functions , So as to realize orderly computing quickly and conveniently .
For simple ordered calculations ,esProc Like any other computing script , Can be easily realized . For example, it's also better than the last one esProc Code :
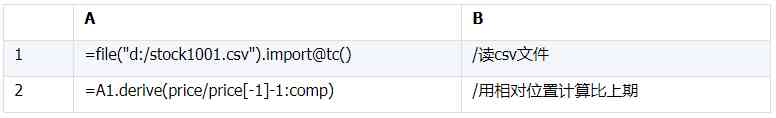
Above code A1 from csv File access ,A2 It's the core code .esProc You can use intuitive and understandable \[-1\] It means the line before the opposite line , This is a Pandas and SQL None of the features , It's also esProc More professional performance .
Also calculate the median ,esProc The core code is as follows :
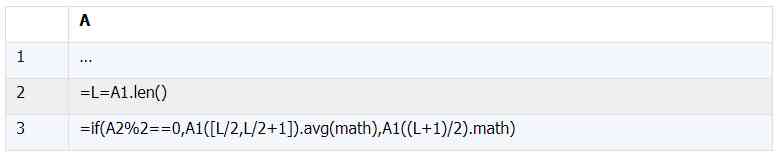
In the above code ,esProc It can be used directly \[N\] Indicates the serial number , Instead of making additional serial numbers , More concise code .esProc It's also procedural grammar , You can use if/else Statement to achieve the branching of large segments , It can also be like this example , use if Function implementation concise judgment .
In the case of the same more complicated case, the longest consecutive rise days ,esProc Is better than SQL/Pandas Easy to implement . The core code is as follows :

In this case ,esProc It can be realized in a natural way , And you don't have to use special techniques , Code expression is more efficient than SQL Higher . In addition , esProc You can use loop statements to achieve large segments of the loop , It can also be like this example , With the loop function max Implement simple cyclic aggregation .
esProc Is a more professional structured computing language , Even with more complex ordered computation , It can also be realized more easily .
For example, the example of filtering cumulative values ,esProc Just use the following code :

This example realizes according to the natural thought , First in A2 Calculate the cumulative value from the largest customer to each customer , And then A3 Work out half of the maximum cumulative value , stay A4 The cumulative value is greater than A3 The location of , Finally, getting data by location is the desired result . Here's the expression esProc Two features of professionalism , The first is A3 Medium m function , This function can retrieve data in reverse order ,-1 It means the last one ; The second is A4 Medium pselect, You can return the sequence number by condition . Both of these functions can effectively simplify the ordered calculation .
Another example is to calculate the highest share price 3 Day's increase ,esProc Just use the following code :

In the above code ,A2 Medium ptop Before presentation N The position of the bar , And the one in front pselect similar , It's not a collection of records , It's a collection of numbers , Functions like this are in esProc There are many more , The aim is to simplify ordered computation .A4 Medium # It's also esProc The characteristics of , Directly represents the serial number field , It is very convenient to use , It doesn't have to be like SQL That makes extra , or Pandas Set that index.
By comparison, we can find that ,esProc With rich structured functions , Is a professional structured computing language , You can easily implement the usual ordered Computing , Even more complex calculations can simplify , Is a more ideal time series data calculation script .