当前位置:网站首页>Large CSV split and merge
Large CSV split and merge
2022-07-03 15:32:00 【ASKCOS】
import pandas as pd
import os
import warnings
warnings.filterwarnings('ignore')
class PyCSV:
def merge_csv(self, save_name, file_dir, csv_encoding='utf-8'):
""" :param save_name: The name of the file saved after merging , User input required :param file_dir: Need to merge csv File folder :param csv_encoding: csv File encoding , Default utf-8 :return: None """
# File path saved after merging = You need to merge the folder where the file is located + The name of the merged file
self.save_path = os.path.join(file_dir, save_name)
self.__check_name()
# Specified encoding
self.encoding = csv_encoding
# Need to merge csv File folder
self.file_dir = file_dir
self.__check_dir_exist(self.file_dir)
# File path list
self.file_list = [os.path.join(self.file_dir, i) for i in os.listdir(self.file_dir)]
self.__check_singal_dir(self.file_list)
# Merge into the specified file
print(" Began to merge csv file !")
for file in self.file_list:
df = pd.read_csv(file, encoding=self.encoding)
df.to_csv(self.save_path, index=False, quoting=1, header=not os.path.exists(self.save_path), mode='a')
print(f"{
file} Has been merged into {
self.save_path} !")
print(" All files have been merged !")
def split_csv(self, csv_path, save_dir, split_line=100000, csv_encoding='utf-8'):
""" Split the file and get csv file information . :param csv_path: csv File path :param save_dir: Save path of segmentation file :param split_line: Divide according to the number of lines , The default is 10 ten thousand :param csv_encoding: csv File encoding format :return: None """
# Pass in csv File path and small after segmentation csv Save path of file
self.csv_path = csv_path
self.save_dir = save_dir
# testing csv Whether the file path and save path conform to the specification
self.__check_dir_exist(self.save_dir)
self.__check_file_exist(self.csv_path)
# Set the encoding format
self.encoding = csv_encoding
# according to split_line That's ok , Segmentation
self.split_line = split_line
print(" Splitting files ... ")
# Get file size
self.file_size = round(os.path.getsize(self.csv_path) / 1024 / 1024, 2)
# Get the number of data rows
self.line_numbers = 0
# The suffix of the file after segmentation
i = 0
# df generator , Each element is a df,df The number of lines is split_line, Default 100000 That's ok
df_iter = pd.read_csv(self.csv_path,
chunksize=self.split_line,
encoding=self.encoding)
# Generate one at a time df, Until all the data is retrieved
for df in df_iter:
# Suffix from 1 Start
i += 1
# Total rows of statistical data
self.line_numbers += df.shape[0]
# Set the save path of the file after segmentation
save_filename = os.path.join(self.save_dir, self.filename + "_" + str(i) + self.extension)
# Print and save information
print(f"{
save_filename} Generated !")
# Save the number after segmentation
df.to_csv(save_filename, index=False, encoding='utf-8', quoting=1)
# Get data column name
self.column_names = pd.read_csv(self.csv_path, nrows=10).columns.tolist()
print(" The segmentation is finished !")
return None
def __check_dir_exist(self, dirpath):
""" test save_dir Whether there is , If it does not exist, create the folder . :return: None """
if not os.path.exists(dirpath):
raise FileNotFoundError(f'{
dirpath} directory does not exist , Please check !')
if not os.path.isdir(dirpath):
raise TypeError(f'{
dirpath} The destination path is not a folder , Please check !')
def __check_file_exist(self, csv_path):
""" test csv_path Whether it is CSV file . :return: None """
if not os.path.exists(csv_path):
raise FileNotFoundError(f'{
csv_path} file does not exist , Please check the file path !')
if not os.path.isfile(csv_path):
raise TypeError(f'{
csv_path} The path is not in file format , Please check !')
# File existence path
self.file_path_root = os.path.split(csv_path)[0]
# File name
self.filename = os.path.split(csv_path)[1].replace('.csv', '').replace('.CSV', '')
# file extension
self.extension = os.path.splitext(csv_path)[1]
if self.extension.upper() != '.CSV':
raise TypeError(f'{
csv_path} Wrong file type , Not CSV file type , Please check !')
def __check_name(self):
""" Check whether the file name .csv ending :return: """
if not self.save_path.upper().endswith('.CSV'):
raise TypeError(' File name setting error ')
def __check_singal_dir(self, file_list):
""" Check what needs to be merged csv Whether the folder where the file is located meets the requirements . 1. There should be no division csv Documents other than documents 2. There should be no folder . :return: """
for file in file_list:
if os.path.isdir(file):
raise EnvironmentError(f' Found folder {
file}, There are other folders in the current folder , Please check !')
if not file.upper().endswith('.CSV'):
raise EnvironmentError(f' Non discovery CSV file :{
file}, Please make sure that the current folder only stores csv file !')
if __name__ == '__main__':
# Test segmentation
csv_path = r'E:\simple.csv'
save_dir = r'E:\simple_splited_files'
PyCSV().split_csv(csv_path, save_dir, split_line=10000)
# Test merge
files_dir = r'E:\simple_splited_files'
save_name = r'merge_simple.csv'
PyCSV().merge_csv(save_name, files_dir)
https://zhuanlan.zhihu.com/p/431104537
边栏推荐
- Introduction, use and principle of synchronized
- Creation and destruction of function stack frames
- Location of software installation information and system services in the registry
- Problems of CString in multithreading
- Concurrency-01-create thread, sleep, yield, wait, join, interrupt, thread state, synchronized, park, reentrantlock
- Solve the problem that pushgateway data will be overwritten by multiple push
- Kubernetes - yaml file interpretation
- Halcon and WinForm study section 1
- Wechat payment -jsapi: code implementation (payment asynchronous callback, Chinese parameter solution)
- 视觉上位系统设计开发(halcon-winform)-6.节点与宫格
猜你喜欢
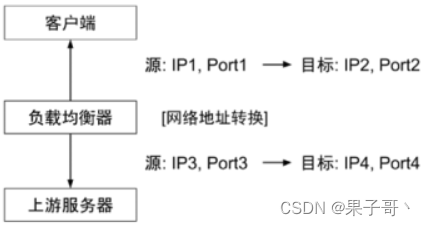
【云原生训练营】模块八 Kubernetes 生命周期管理和服务发现

Characteristics of MySQL InnoDB storage engine -- Analysis of row lock
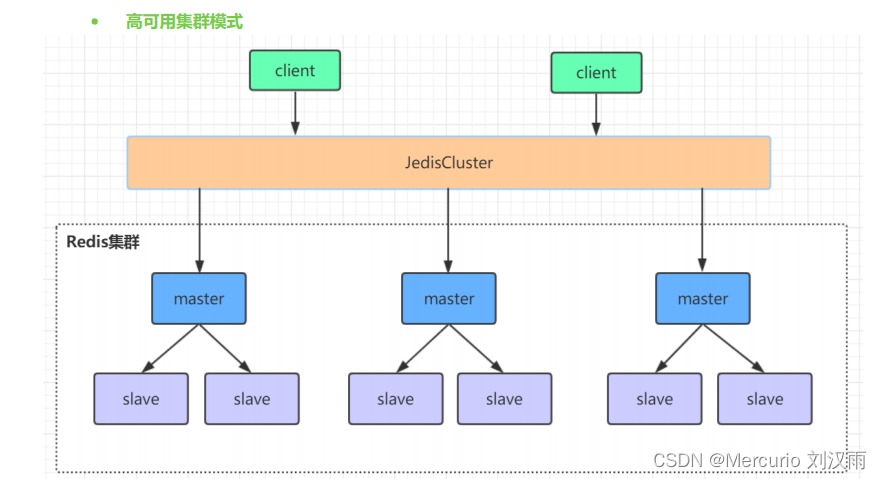
Redis主从、哨兵、集群模式介绍

Solve the problem that pushgateway data will be overwritten by multiple push
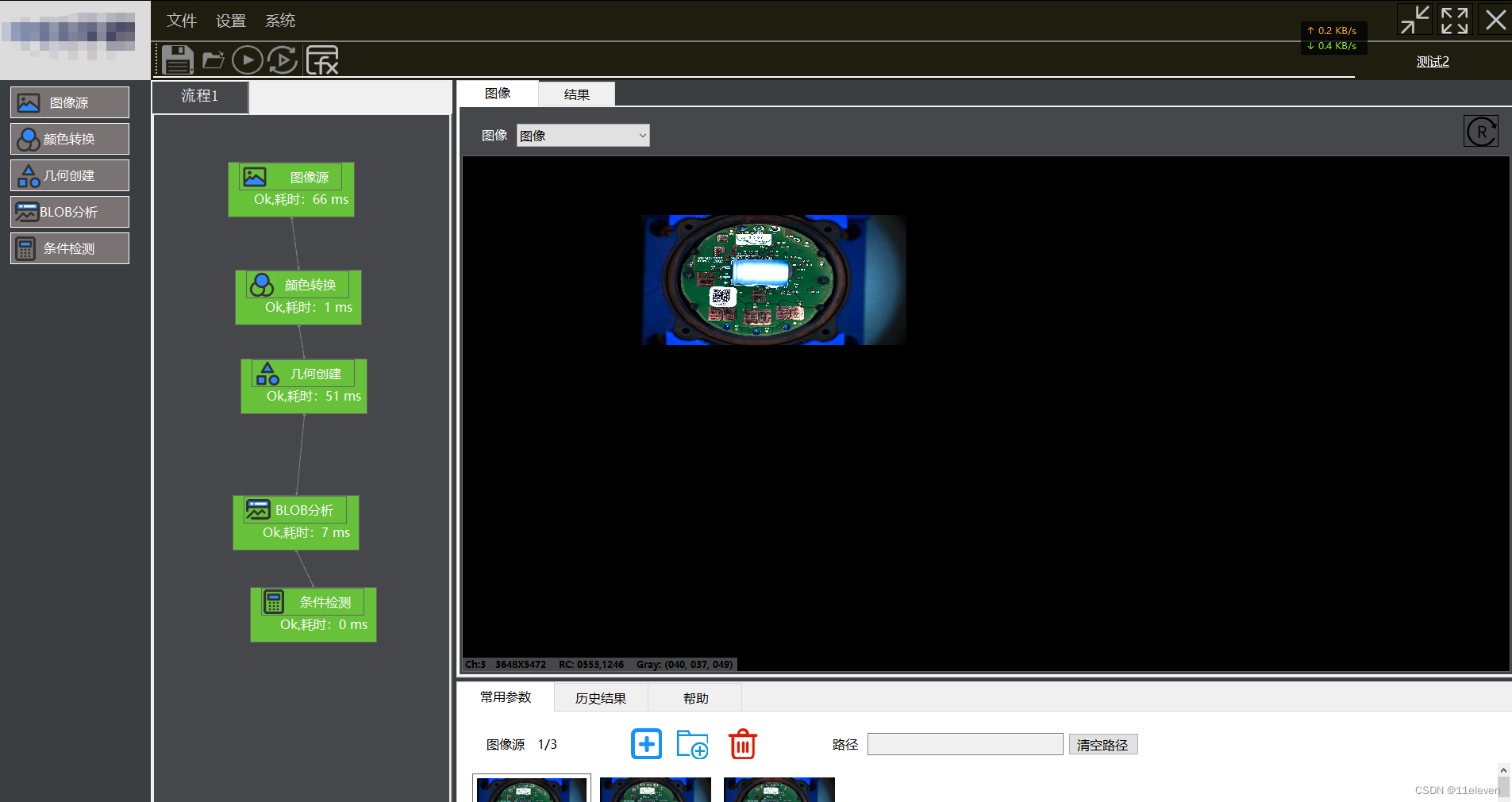
Halcon与Winform学习第二节

从 flask 服务端代码自动生成客户端代码 -- flask-native-stubs 库介绍

qt使用QZxing生成二维码

Reentrantlock usage and source code analysis
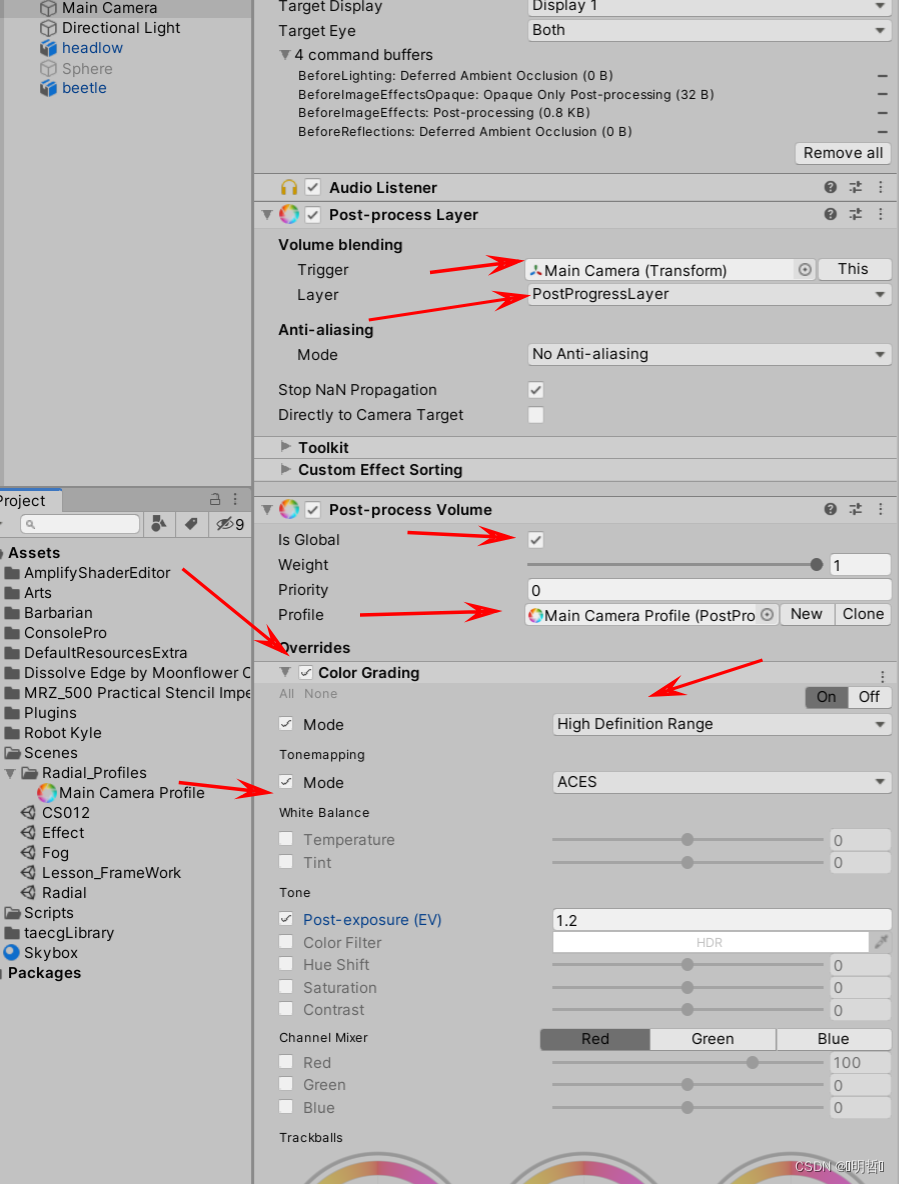
Unityshader - materialcapture material capture effect (Emerald axe)

如何使用 @NotNull等注解校验 并全局异常处理
随机推荐
阿特拉斯atlas扭矩枪 USB通讯教程基于MTCOM
Atlas atlas torque gun USB communication tutorial based on mtcom
Popular understanding of decision tree ID3
Jvm-05-object, direct memory, string constant pool
Reentrantlock usage and source code analysis
Concurrency-02-visibility, atomicity, orderliness, volatile, CAS, atomic class, unsafe
北京共有产权房出租新规实施的租赁案例
【云原生训练营】模块七 Kubernetes 控制平面组件:调度器与控制器
Halcon与Winform学习第二节
Detailed comments on MapReduce instance code on the official website
socket. IO build distributed web push server
Chapter 04_ Logical architecture
Popular understanding of gradient descent
How are integer and floating-point types stored in memory
How to use annotations such as @notnull to verify and handle global exceptions
秒杀系统2-Redis解决分布式Session问题
视觉上位系统设计开发(halcon-winform)-4.通信管理
[combinatorial mathematics] binomial theorem and combinatorial identity (binomial theorem | three combinatorial identities | recursive formula 1 | recursive formula 2 | recursive formula 3 Pascal / Ya
Idea does not specify an output path for the module
PyTorch crop images differentiablly