当前位置:网站首页>Go language learning summary (7) -- Dachang go programming specification summary
Go language learning summary (7) -- Dachang go programming specification summary
2022-06-12 01:13:00 【Technology d life】
One 、 Interface to use
1、 If you want the interface method to modify the underlying data , Must be passed with a pointer
type F interface {
f()
}
type S1 struct{}
func (s S1) f() {}
type S2 struct{}
func (s *S2) f() {}
var f1 F = S1{}
var f2 F = &S2{}
// f1.f() Cannot modify underlying data
// f2.f() You can modify the underlying data , Give interface variables f2 The object pointer is used in assignment Only the receiver of the method is a pointer , To modify the underlying data . Whether or not the caller of the method is a pointer , Whether the underlying data can be modified depends on “ Recipient of method ” Is it a pointer . above S2 Method recipients are pointers , So you can modify the data .
2、 The method receiver is the value , The caller can be a value or a pointer , But if the receiver is a pointer , Can only be called by pointer
type F interface {
f()
}
type S1 struct{}
func (s S1) f() {}
type S2 struct{}
func (s *S2) f() {}
s1Val := S1{}
s1Ptr := &S1{}
s2Val := S2{}
s2Ptr := &S2{}
var i F
i = s1Val
i = s1Ptr
i = s2Ptr
// The following code cannot be compiled . because s2Val It's a value , and S2 Of f Method does not use a value sink
// i = s2ValThe above code , because S2 The receiver of a function is a pointer , Can only be called through a pointer . This is actually very easy to understand , For value recipients , Value expected , If you transfer values directly, there is no problem , If the passed pointer , Get the corresponding value through implicit conversion of pointer , Then call again .
3、 Interface compilation detection
This is a good habit , First look at the following bad case.
// If Handler It didn't come true http.Handler, There will be errors in the operation
type Handler struct {
// ...
}
func (h *Handler) ServeHTTP(
w http.ResponseWriter,
r *http.Request,
) {
...
}If we judge in advance , You can find problems in advance during compilation .
type Handler struct {
// ...
}
// The rationality check mechanism used to trigger the interface at compile time
// If Handler It didn't come true http.Handler, Errors will be reported during compilation
var _ http.Handler = (*Handler)(nil)
func (h *Handler) ServeHTTP(
w http.ResponseWriter,
r *http.Request,
) {
// ...
}Transform through the interface , You can check whether the corresponding interface is implemented . If the receiver is a value , You can use the “{}” Initializes an object to detect .
var _ http.Handler = LogHandler{}
func (h LogHandler) ServeHTTP(
w http.ResponseWriter,
r *http.Request,
) {
// ...
}Two 、mutex
mutex yes golang The mutex of , It can ensure that in the case of multiple processes , Security of data access .
1、 Zero is valid
We don't need mutex The pointer
mu := new(sync.Mutex)
mu.Lock()Directly available mutex Zero value of .
var mu sync.Mutex
mu.Lock()2、mutex visibility
go Of map Non-thread safety , So we often pass mutex to map Add a lock , Let's take a look at the first way :
type SMap struct {
sync.Mutex
data map[string]string
}
func (m *SMap) Get(k string) string {
m.Lock()
defer m.Unlock()
return m.data[k]
}
Then let's look at the second way
type SMap struct {
mu sync.Mutex
data map[string]string
}
func (m *SMap) Get(k string) string {
m.mu.Lock()
defer m.mu.Unlock()
return m.data[k]
}It doesn't feel very different , What's the difference ? From the point of view of encapsulation , The second method is better . Because the first way ,SMap Medium mutex It's in capital letters , signify , External can directly call lock and unlock Method , The internal encapsulation principle is broken , So method two is better .
3、defer More secure
Although we can use the following code , According to the demand unlock
p.Lock()
if p.count < 10 {
p.Unlock()
return p.count
}
p.count++
newCount := p.count
p.Unlock()
return newCountBut the above code has two problems , First, if there are too many branches, it is easy to cause unlock , Second, the readability is poor , It's everywhere unlock. Therefore, the following wording is more recommended
p.Lock()
defer p.Unlock()
if p.count < 10 {
return p.count
}
p.count++
return p.countdefer Very little loss , You don't have to worry about it .
3、 ... and 、Slices and Maps
slice and map Principle type of . We see first slice Definition
type SliceHeader struct {
Pointer uintptr
Len int
Cap int
}Contains a pointer to the data and slice The length of (len) And capacity (capacity).

So we're going to slice When passing as a parameter , The bottom layer shares the same data . Consider the following code , Let's define a SetTrips Method , Pass in a slice to driver.
func (d *Driver) SetTrips(trips []Trip) {
d.trips = trips
}
trips := ...
d1.SetTrips(trips)
// You are going to modify d1.trips Do you ?
trips[0] = ...Then we modify it externally trips, that driver Inside trips It's going to change , This is what we don't want to see . So the safer way is , Create a new... In the method slice, Then copy the native data one by one , In this way, external data changes will not affect driver 了 . as follows :
func (d *Driver) SetTrips(trips []Trip) {
d.trips = make([]Trip, len(trips))
copy(d.trips, trips)
}
trips := ...
d1.SetTrips(trips)
// Here we modify trips[0], But it won't affect d1.trips
trips[0] = ..Look back at the last article that passed mutex Create thread safe map The article , If you want to return the whole map The content of , You can do this in the following ways .
func (s *Stats) Snapshot() map[string]int {
s.mu.Lock()
defer s.mu.Unlock()
return s.counters
}But this goes straight back map The way , This will cause the caller to obtain an insecure map Of . If you modify this at the place you call map, There will be data conflicts . It is safer to
func (s *Stats) Snapshot() map[string]int {
s.mu.Lock()
defer s.mu.Unlock()
result := make(map[string]int, len(s.counters))
for k, v := range s.counters {
result[k] = v
}
return result
}Create a new map return , This just returns this map Snapshot at this time , Follow up on result Modification of , It doesn't affect stats in map The content of .
Four 、 Time processing
1、time
go time Is based on int So we can compare them directly int The size determines the time
func isActive(now, start, stop int) bool {
return start <= now && now < stop
}But the comparison of time , Best use time, as follows
func isActive(now, start, stop time.Time) bool {
return (start.Before(now) || start.Equal(now)) && now.Before(stop)
}Better readability . in addition ,encoding/json Through its UnmarshalJSON method Method support will time.Time Encoded as RFC 3339 character string .
2、Duration
The time period processing is similar , The following code poll Methods the incoming 10
func poll(delay int) {
for {
// ...
time.Sleep(time.Duration(delay) * time.Millisecond)
}
}
poll(10) But who knows the incoming 10 It stands for 10s and 10ms , Therefore, the more recommended method is to directly transfer Duration
func poll(delay time.Duration) {
for {
// ...
time.Sleep(delay)
}
}
poll(10*time.Second)So the method caller , You can import the corresponding time period according to your own needs . and flag adopt time.ParseDuration Has supported time.Duration type . Last , If the external system does not support time When it comes to type , For example, you need to duration json When , This naming makes it difficult for users to understand interval The unit of .
type Config struct {
Interval int `json:"interval"`
}Therefore, it is more recommended to write in this way
// {"intervalMillis": 2000}
type Config struct {
IntervalMillis int `json:"intervalMillis"`
}In this way, the caller can clearly understand that the unit is milliseconds .
5、 ... and 、 Error handling
In error handling , We often do fmt.Errorf perhaps errors.New Define errors at will , But this will lead to very troublesome error management . as follows :
func Open() error {
return errors.New("could not open")
}
if err := foo.Open(); err != nil {
// There is no special treatment for different errors
panic("unknown error")
}Or this one below bad case
func Open(file string) error {
return fmt.Errorf("file %q not found", file)
}
if err := foo.Open("testfile.txt"); err != nil {
// There is no special treatment for different errors
panic("unknown error")
}Therefore, it is more recommended that we define errors in advance , Unified error handling , For the above two bad case, Look at the following two elegant approaches
var ErrCouldNotOpen = errors.New("could not open")
func Open() error {
return ErrCouldNotOpen
}
if err := foo.Open();err != nil {
if errors.Is(err, foo.ErrCouldNotOpen) {
// Handle scenarios where the file does not exist
} else {
panic("unknown error")
}
}If you want to return more information , You can define a error Structure , Realization Error Method . as follows
var ErrCouldNotOpen = errors.New("could not open")
func Open() error {
return ErrCouldNotOpen
}
if err := foo.Open(); err != nil {
if errors.Is(err, foo.ErrCouldNotOpen) {
// Handle scenarios where the file does not exist
} else {
panic("unknown error")
}
}The purpose of the errors checked above is to , Handle different errors gracefully , Not to catch it . This is with us Java There are all kinds of catch It's one thing ,(Exception e) Just for the bottom . About err There is a small detail to the order of , above New Of error Usually, the Err perhaps err start , as follows :
ErrBrokenLink = errors.New("link is broken")
ErrCouldNotOpen = errors.New("could not open")If it is a custom error type , With Error ending .
type NotFoundError struct {
File string
}6、 ... and 、 Nested Types
Go allow Type embedding As a compromise between inheritance and composition . But the implicit nested leak implementation details 、 Prohibit type evolution . See the following example , Let's first define a list
type AbstractList struct {}
// Add adds an entity to the list .
func (l *AbstractList) Add(e Entity) {
// ...
}
// Remove removes an entity from the list .
func (l *AbstractList) Remove(e Entity) {
// ...
}When expanding this structure face to face , Using direct nesting
type ConcreteList struct {
*AbstractList
}Will lead to the previous introduction mutex The question in that article , The internal encapsulation is broken , And if there are subclasses that want to extend later ConcreteList Add one Add Method time , You can't call AbstractList Of Add The method , It affects the subsequent expansion . Even if we embed an interface (interface), It is not recommended to embed directly
type AbstractList interface {
Add(Entity)
Remove(Entity)
}
// ConcreteList Is a list of entities .
type ConcreteList struct {
AbstractList
}Instead, it should be done in the following way :
type ConcreteList struct {
list AbstractList
}
// Add adds an entity to the list .
func (l *ConcreteList) Add(e Entity) {
l.list.Add(e)
}
// Remove removes an entity from the list .
func (l *ConcreteList) Remove(e Entity) {
l.list.Remove(e)
}To sum up , Do not embed anonymously !
7、 ... and 、 performance
1、 initialization slice Capacity
contrast
for n := 0; n < b.N; n++ {
data := make([]int, 0)
for k := 0; k < size; k++{
data = append(data, k)
}
}
BenchmarkBad-4 100000000 2.48sand
for n := 0; n < b.N; n++ {
data := make([]int, 0, size)
for k := 0; k < size; k++{
data = append(data, k)
}
}
BenchmarkGood-4 100000000 0.21sWe can find out , Try to initialize slice Determine the capacity when , Avoid frequently requesting memory and copying data .map The creation of is similar , As far as possible in make Determine the capacity when .
2、 Array to character use strconv Replace fmt
contrast
for i := 0; i < b.N; i++ {
s := fmt.Sprint(rand.Int())
}
BenchmarkFmtSprint-4 143 ns/op 2 allocs/opand
for i := 0; i < b.N; i++ {
s := strconv.Itoa(rand.Int())
}
BenchmarkStrconv-4 64.2 ns/op 1 allocs/opstrconv The performance is obviously better than fmt.
3、 Avoid repeated byte conversions
Compare each execution write Perform a string conversion
for i := 0; i < b.N; i++ {
w.Write([]byte("Hello world"))
}
BenchmarkBad-4 50000000 22.2 ns/opUse the following one-time conversion
data := []byte("Hello world")
for i := 0; i < b.N; i++ {
w.Write(data)
}
BenchmarkGood-4 500000000 3.25 ns/opGood performance is much better .
8、 ... and 、 Code specification
1、 Use goimport grouping
such import Can be grouped , It looks neat .
import (
"fmt"
"os"
"go.uber.org/atomic"
"golang.org/x/sync/errgroup"
)2、 Put the same type into a group
const (
a = 1
b = 2
)
var (
a = 1
b = 2
)
type (
Area float64
Volume float64
)3、 Package name
When naming a package , Please select a name according to the following rules :
- All lowercase . No capitals or underscores .
- In most cases where named imports are used , No need to rename .
- Short and concise . please remember , The name is fully identified in every place of use .
- Don't use the plural . for example net/url, instead of net/urls.
- Do not use “common”,“util”,“shared” or “lib”. These are not good , Names with insufficient information .
4、 Do not use aliases
Aliases are required only in case of package name conflicts , Don't abuse aliases
import (
"fmt"
"os"
"runtime/trace"
nettrace "golang.net/x/trace"
)5、 Reduce the nested
This should be the norm that all languages should follow , Avoid multiple layers if else nesting . The following code should be
for _, v := range data {
if v.F1 == 1 {
v = process(v)
if err := v.Call(); err == nil {
v.Send()
} else {
return err
}
} else {
log.Printf("Invalid v: %v", v)
}
}Transform into the following way
for _, v := range data {
if v.F1 != 1 {
log.Printf("Invalid v: %v", v)
continue
}
v = process(v)
if err := v.Call(); err != nil {
return err
}
v.Send()
}6、 Reduce unnecessary else
The following code should be
var a int
if b {
a = 100
} else {
a = 10
}Transform into
a := 10
if b {
a = 100
}7、 Initialize the structure with the field name
Don't try to save time
k := User{"John", "Doe", true}Instead, it should be written in full
k := User{
FirstName: "John",
LastName: "Doe",
Admin: true,
}8、 empty slice
Check for empty slice Should not be used
func isEmpty(s []string) bool {
return s == nil
}And it should go through len Method .
func isEmpty(s []string) bool {
return len(s) == 0
}9、 Narrow the scope of variables
Write as follows err The return is the entire function
err := ioutil.WriteFile(name, data, 0644)
if err != nil {
return err
}It can be controlled in if Within the function .
if err := ioutil.WriteFile(name, data, 0644); err != nil {
return err
}边栏推荐
- Explain asynchronous tasks in detail: the task of function calculation triggers de duplication
- Before applying data warehouse ODBC, you need to understand these problems first
- Global and Chinese lutetium oxide powder industry investigation and analysis and Investment Strategy Research Report 2022-2028
- Recurrent+Transformer 视频恢复领域的‘德艺双馨’
- Lambda中间操作skip
- Is interface automation difficult? Take you from 0 to 1 to get started with interface automation test [0 basic can also understand series]
- New knowledge: monkey improved app crawler
- Common assertions for JMeter interface testing
- Flowable workflow
- [path of system analysts] summary of real problems of system analysts over the years
猜你喜欢

Set up NFT blind box mall system | customized development of NFT mall software

Equipment encryption of industrial control security
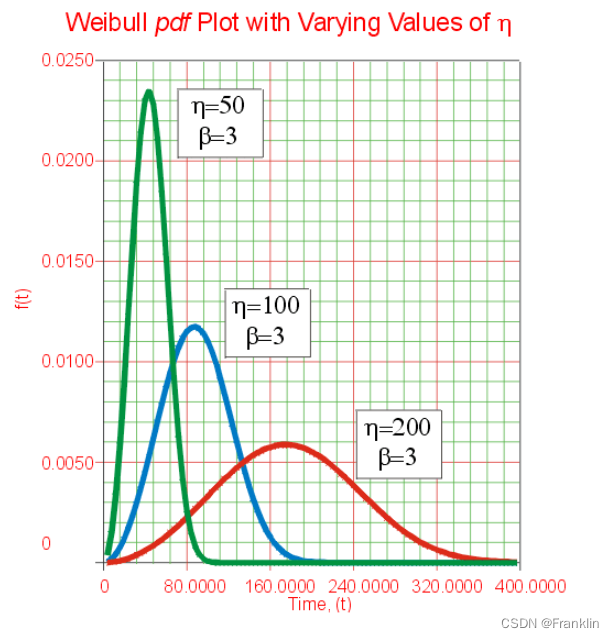
In depth description of Weibull distribution (2) meaning of parameters and formulas
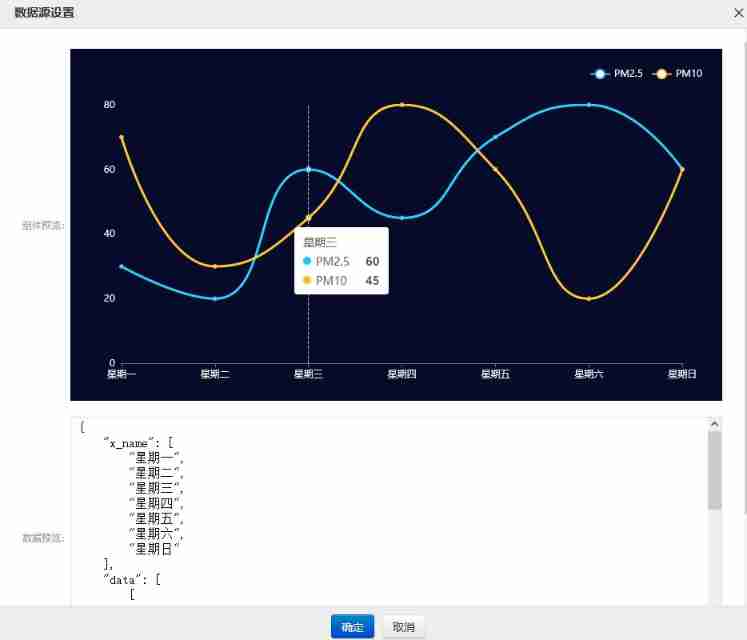
Component introduction - large screen cloud minimalist user manual
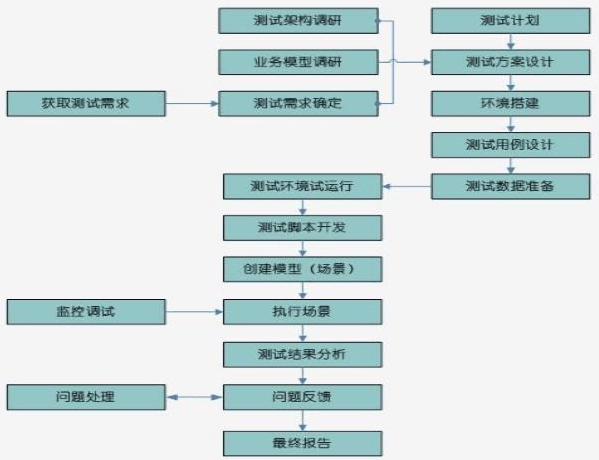
Given a project, how will you conduct performance testing?

Module 8 - Design message queue MySQL table for storing message data

Vscode - the problem of saving a file and automatically formatting the single quotation mark 'into a double quotation mark'

马尔可夫网络 与 条件随机场

Inventory: more than 20 typical safety incidents occurred in February, with a loss of nearly $400million

Go out with a stream
随机推荐
写代码复现论文的几点建议!
Argodb 3.2 of star ring technology was officially released to comprehensively upgrade ease of use, performance and security
Is interface automation difficult? Take you from 0 to 1 to get started with interface automation test [0 basic can also understand series]
Lambda quick start
Kill, pkill, killall, next, what I brought to you in the last issue is how to end the process number and rush!
Lambda中间操作skip
C language structure - learning 27
In depth description of Weibull distribution (1) principle and formula
中创专利|中国5G标准必要专利达1.8万项,尊重知识产权,共建知识产权强国
C language preprocessing instructions - learning 21
How can functional tests be quickly advanced in one month? It is not a problem to clarify these two steps
Lambda intermediate operation limit
Henan Zhongchuang - from cloud to edge, how edge computing enables data centers
Data visualization big screen - big screen cloud minimalist user manual
Lambda中间操作flatMap
Verification code is the natural enemy of automation? Let's see how Ali P7 solved it
What is the digital twin of Yixin Huachen and what is its application value?
C language string and pointer - learning 25
Matlab 基础应用02 wind 股票数据介绍和使用案例:
[answer] business use cases and system use cases are mixed together