当前位置:网站首页>Mobile heterogeneous computing technology - GPU OpenCL programming (basic)
Mobile heterogeneous computing technology - GPU OpenCL programming (basic)
2022-06-28 23:22:00 【A female programmer who can't write code】
One 、 Preface
With the continuous improvement of mobile terminal chip performance , Real time computer graphics on the mobile terminal 、 Deep learning, model reasoning and other computing intensive tasks are no longer a luxury . On mobile devices ,GPU With its excellent floating-point performance , And good API Compatibility , Become a very important computing unit in mobile heterogeneous computing . At this stage , stay Android Equipment market , qualcomm Adreno And Huawei Mali Has occupied the mobile phone GPU The main share of chips , Both provide strong GPU Computing power .OpenCL, As Android System library of , It is well supported on both chips .
at present , Baidu APP Have already put GPU Computational acceleration means , It is applied to deep model reasoning and some computing intensive businesses , This article will introduce OpenCL Basic concepts and simple OpenCL Programming .
( notes :Apple about GPU The recommended way of use is Metal, Expansion is not done here )
Two 、 Basic concepts
2.1 Heterogeneous computing
Heterogeneous computing (Heterogeneous Computing), It mainly refers to the computing mode of the system composed of computing units with different types of instruction sets and architectures . Common cell categories include CPU、GPU And so on 、DSP、ASIC、FPGA etc. .
2.2 GPU
GPU(Graphics Processing Unit), Graphics processor , Also known as display core 、 The graphics card 、 Visual processor 、 Display chip or drawing chip , It's a special kind of PC 、 The workstation 、 Game consoles and some mobile devices ( Like a tablet 、 Smart phones and so on ) A microprocessor that performs drawing operations on . Improve... In traditional ways CPU The way to improve computing power based on clock frequency and the number of cores has encountered the bottleneck of heat dissipation and energy consumption . although GPU The working frequency of a single computing unit is low , But it has more cores and parallel computing power . Compared with CPU,GPU The overall performance of - Chip area ratio , performance - The power consumption is higher than that of the .
3、 ... and 、OpenCL
OpenCL(Open Computing Language) Is a non-profit technology organization Khronos Group In charge of the heterogeneous platform programming framework , The supported heterogeneous platforms cover CPU、GPU、DSP、FPGA And other types of processors and hardware accelerators .OpenCL It mainly consists of two parts , Part is based on C99 The standard language used to write the kernel , The other part is to define and control the platform API.
OpenCL Similar to two other open industrial standards OpenGL and OpenAL , They are used in three-dimensional graphics and computer audio respectively .OpenCL Mainly expanded GPU Computing power beyond graphics generation .
3.1 OpenCL Programming model
Use OpenCL Programming needs to know OpenCL Three core models of programming ,OpenCL platform 、 Execution and memory models .
Platform model (Platform Model)
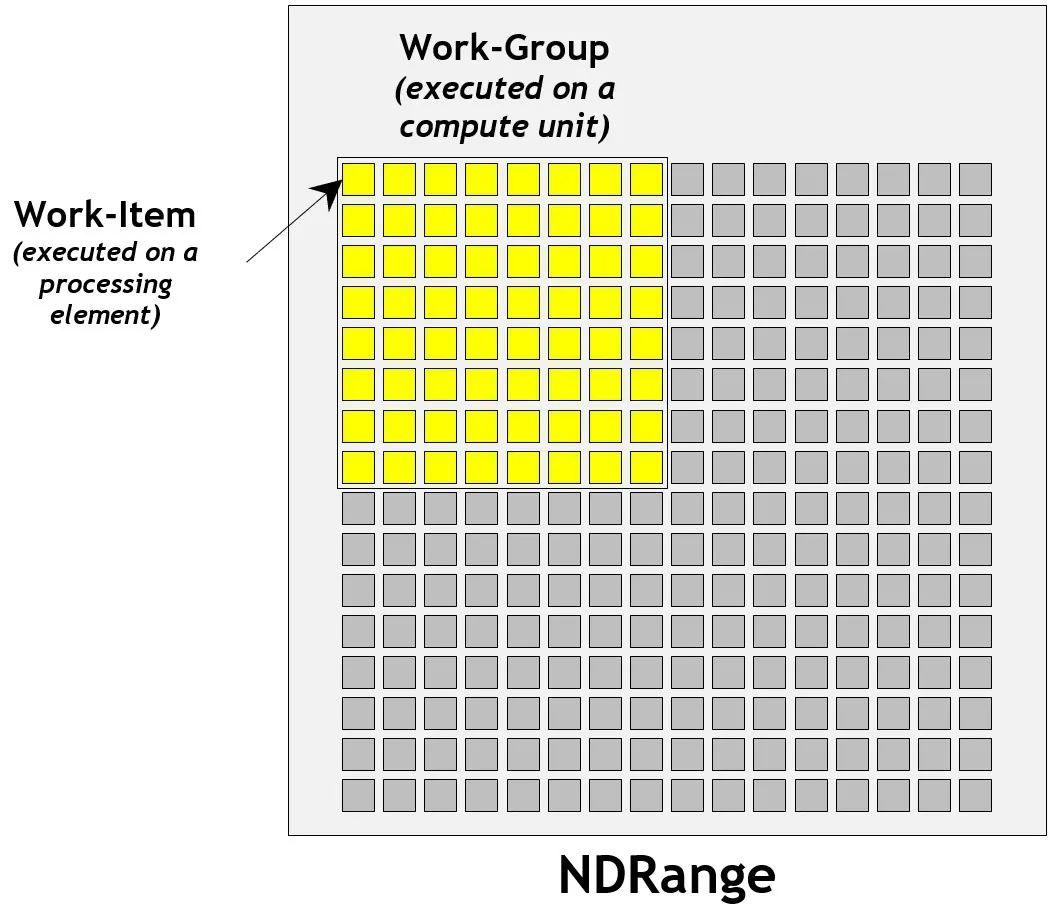
Platform representative OpenCL The topological relationship between computing resources in the system from the perspective of . about Android equipment ,Host That is CPU. Every GPU Computing equipment (Compute Device) Both contain multiple computing units (Compute Unit), Each cell contains multiple processing elements (Processing Element). about GPU for , Computing units and processing elements are GPU Streaming multiprocessor in .

Execution model (Execution Model)
adopt OpenCL Of clEnqueueNDRangeKernel command , You can start precompiled OpenCL kernel ,OpenCL The architecture can support N Dimensional data parallel processing . Take a two-dimensional picture as an example , If you take the width and height of the picture as NDRange, stay OpenCL The kernel of can put each pixel of the picture on a processing element to execute , Thus, the goal of parallel execution can be achieved .
From the platform model above, we can know , In order to improve the efficiency of execution , Processors usually allocate processing elements to execution units . We can do it in clEnqueueNDRangeKernel Specify workgroup size in . Work items in the same workgroup can share local memory , Barriers can be used (Barriers) To synchronize , You can also use specific workgroup functions ( such as async_work_group_copy) To collaborate .

Memory model (Memory Model)
The following figure describes OpenCL Memory structure :
Host memory (Host Memory): host CPU Directly accessible memory .
overall situation / Constant memory (Global/Constant Memory): It can be used for all computing units in the computing device .
Local memory (Local Memory): Available for all processing elements in the computing unit .
Private memory (Private Memory): For a single processing element .

3.2 OpenCL Programming
OpenCL Some engineering encapsulation is needed in the practical application of programming , This article only takes the addition of two arrays as an example , And provide a simple example code as a reference ARRAY_ADD_SAMPLE (https://github.com/xiebaiyuan/opencl_cook/blob/master/array_add/array_add.cpp).
This article will use this as an example , To illustrate OpenCL workflow .
OpenCL The overall process is mainly divided into the following steps :
initialization OpenCL Related to the environment , Such as cl_device、cl_context、cl_command_queue etc.
cl_int status;
// init device
runtime.device = init_device();
// create context
runtime.context = clCreateContext(nullptr, 1, &runtime.device, nullptr, nullptr, &status);
// create queue
runtime.queue = clCreateCommandQueue(runtime.context, runtime.device, 0, &status);
Initialization program to execute program、kernel
cl_int status;
// init program
runtime.program = build_program(runtime.context, runtime.device, PROGRAM_FILE);
// create kernel
runtime.kernel = clCreateKernel(runtime.program, KERNEL_FUNC, &status);
Prepare input and output , Set to CLKernel
// init datas
float input_data[ARRAY_SIZE];
float bias_data[ARRAY_SIZE];
float output_data[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
input_data[i] = 1.f * (float) i;
bias_data[i] = 10000.f;
}
// create buffers
runtime.input_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), input_data, &status);
runtime.bias_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), bias_data, &status);
runtime.output_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), output_data, &status);
// config cl args
status = clSetKernelArg(runtime.kernel, 0, sizeof(cl_mem), &runtime.input_buffer);
status |= clSetKernelArg(runtime.kernel, 1, sizeof(cl_mem), &runtime.bias_buffer);
status |= clSetKernelArg(runtime.kernel, 2, sizeof(cl_mem), &runtime.output_buffer);
Execute get results
// clEnqueueNDRangeKernel
status = clEnqueueNDRangeKernel(runtime.queue, runtime.kernel, 1, nullptr, &ARRAY_SIZE,
nullptr, 0, nullptr, nullptr);
// read from output
status = clEnqueueReadBuffer(runtime.queue, runtime.output_buffer, CL_TRUE, 0,
sizeof(output_data), output_data, 0, nullptr, nullptr);
// do with output_data
...
Four 、 summary
With CPU The arrival of the bottleneck ,GPU Or the programming of other special computing devices will be an important technical direction in the future .
边栏推荐
- Puma joins hands with 10ktf shop to launch its Web3 cooperation project with the largest scale so far
- [flutter issues Series title 71] Mutual Conversion between uint8list and Image in flutter
- Cmake tutorial (I)
- Use conditional breakpoints in vscode (based on GDB)
- CMake教程(一)
- Leetcode 324 swing sort ii[sort double pointer] the leetcode path of heroding
- LeetCode 324 摆动排序 II[排序 双指针] HERODING的LeetCode之路
- I can't sleep
- Junior, it's not easy!
- 第四章 存储器管理练习
猜你喜欢

机器学习4-降维技术

Cs5463 code module analysis (including download link)
![[数学建模]Matlab非线性规划之fmincon()函数](/img/fc/46949679859b1369fcc83d0d8b637c.png)
[数学建模]Matlab非线性规划之fmincon()函数
【Word 教程系列第 2 篇】Word 中如何设置每页的表格都有表头
![[stm32 HAL库] RTC和BKP驱动](/img/72/c2c46377d0a2a5a032802640ca0201.png)
[stm32 HAL库] RTC和BKP驱动

Encounter with avita 11: long lost freshness under strong product power
移动端异构运算技术 - GPU OpenCL 编程(基础篇)

ERROR 1067 (42000): Invalid default value for ‘end_time‘ Mysql

Finally, someone explained the cloud native architecture
LINQ linked table query
随机推荐
移动端异构运算技术 - GPU OpenCL 编程(基础篇)
老家出资,俞敏洪设立两支基金
【状态机设计】Moore、Mealy状态机、三段式、二段式、一段式状态机书写规范
Is it safe to open a stock account on the Internet?
C interview questions_ 20220627 record
[stm32 Hal library] RTC and BKP drives
pymysql.Error 获取错误码与具体错误信息
图片64base转码与解码
Chapter IV memory management exercise
keil工程,程序写多后,RTT不能打印
国盛证券开户是真的安全可靠吗
SqlServer复习
Prometeus 2.36.0 new features
Small sample sharp weapon 2 Text confrontation + semi supervised FGSM & VAT & FGM code implementation
Is it safe and reliable to open a securities account in changtou school?
TDD and automated testing
网上注册股票开户很困难么?在线开户是安全么?
Mathematical knowledge: finding combinatorial number I - finding combinatorial number
华为22级专家十年心血终成云原生服务网格进阶实战文档,是真的6
[sword finger offer] 50 First character that appears only once