当前位置:网站首页>Regular expressions and text processors for shell programming
Regular expressions and text processors for shell programming
2022-07-03 23:52:00 【Official certification】
Preface
Regular expressions , Also known as regular expression .( English :Regular Expression), In code it is often abbreviated as regex、regexp or RE), A concept of computer science . Regular expressions are often used for retrieval 、 Replace those that match a pattern ( The rules ) The text of , There is more than one regular expression , and Linux Different programs in may use different regular expressions , Such as : Supported tools :grep sed awk egrep
One 、 summary
It is usually used to judge , Used to check a Whether the string meets a certain format
Regular expressions are composed of ordinary characters and metacharacters
Ordinary characters include upper and lower case letters 、 Numbers 、 Punctuation and some other symbols
Metacharacters are special characters with special meaning in regular expressions , It can be used to specify its leading characters ( The character before the metacharacter ) The occurrence pattern in the target object
Linux There are two regular expression engines commonly used in
Basic regular expressions :BRE
Extended regular expression : ERE
Two 、 Common metacharacters in basic regular expressions
- Supported tools : grep、egrep、sed、awk


3、 ... and 、 Extended regular expression metacharacter
- In general, it's enough to use basic regular expressions , But sometimes in order to simplify the whole instruction , Need to use A wider range of extended regular expressions . for example , Use the basic regular expression to query the blank line in the file and the first line is “#”
- Supported tools :egerp、awk

+ egrep -n 'wo+d' test.txt # Inquire about "wood" "woood" "woooooood" Etc
? egrep -n 'bes?t' test.txt # Inquire about “bet”“best” These two strings
| egrep -n 'of|is|on' test.tx # Inquire about "of" perhaps "if" perhaps "on" character string
() egrep -n 't(a|e)st' test.txt # Inquire about "tast" perhaps "test" character string
()+ egrep -n 'A(xyz)+C' test.txt # At the beginning of the query "A" It ends with "C", More than one in the middle "xyz" Meaning of string
- 1.
- 2.
- 3.
- 4.
- 5.
Four 、grep
-a | take binary Document to text Searching data by file |
-c | Calculate find ‘ Search string ’ The number of times |
-n | Output line number by the way |
-v | Reverse selection , That is to say, no ‘ Search string ’ Content line ! |
–color=auto | You can add color to the key words you find |
grep -c "the" web.sh # Statistics the Total number of characters ;
grep -i "the" web.sh # Case insensitive lookup the All of the line
grep -v "the" web.sh
- 1.
- 2.
- 3.
1. Find specific characters
grep -ni 'the' test.txt
# Finding specific characters is very simple , If you execute this command, you can start from test.txt Find specific characters in the file “the” The position of . among “-n” Indicates display line number 、“-i” Indicates case insensitive . After the execution of the command , Matching characters , The font color changes to red ( All in this chapter are shown in bold instead of )
grep -vn 'the' test.txt
# If reverse selection , If the search does not contain “the” Lines of characters , You have to go through grep Ordered “-v” Option implementation , And cooperate with “-n” Use together to display line numbers
- 1.
- 2.
- 3.
- 4.
2. Using brackets “[]” To find set characters
grep -n 'sh[io]rt' test.txt
# Want to find “shirt” And “short” When these two strings , You can find that both strings contain “sh” And “rt”. At this time, execute this command to find “shirt” And “short” These two strings , among “[]” No matter how many characters there are , All represent only one character , in other words “[io]” Represents a match “i” perhaps “o”
grep -n 'oo' test.txt
# To find a single character that contains duplicates “oo” when , Just execute this command
grep -n '[^w]oo' test.txt
# Find out if “oo” The front is not “w” String , Only through the reverse selection of set characters “[^]” To achieve that goal . For example, to perform “grep -n‘[^w]oo’test.txt” The command indicates in test.txt Find... In the text “oo” The front is not “w” String
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
3. Find the beginning of a line “^” And end of line characters “$”
[[email protected] ~]# grep -n '^the' test.txt
4:the tongue is boneless but it breaks bones.12!
# The base regular expression contains two positioning metacharacters :“^”( Head of line ) And “$”( At the end of the line ), If you want to query with “the” The line with the string at the beginning of the line , You can use the “^” Metacharacters .
[[email protected] ~]# grep -n '^$' test.txt
10:
# Query blank lines
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
“^” The symbol is in the metacharacter set “[]” The functions inside and outside the symbol are different , stay “[]” The symbol indicates reverse selection , stay “[]” Outside the symbol stands for positioning the beginning of the line . conversely , If you want to find a line that ends with a particular character, you can use “$” Locator . for example , Execute the following command to implement the query with decimal point (.) The line at the end . Because of the decimal point (.) It's also a metacharacter in regular expressions , So here we need to use escape characters “\” Convert characters with special meaning into ordinary characters .
4. Find any character “.” And repeating characters “*”
In regular expressions, the decimal point (.) It's also a metacharacter , Represents any character . For example, execute the following command to find “w??d” String , Four characters in total , With w start d ending .
[[email protected] ~]# grep -n 'w..d' test.txt
5:google is the best tools for search keyword.
8:a wood cross!
9:Actions speak louder than words
- 1.
- 2.
- 3.
- 4.
- 5.
5. Find range of consecutive characters
If you want to limit a range of repeated strings, how to achieve it ? for example , Find three to five o Continuous characters of , At this time, you need to use the limited range of characters in the basic regular expression “{}”. because “{}” stay Shell Has special significance in , So it's using “{}” Character time , Escape character required “\”, take “{}” Character to normal .“{}” The use of characters is as follows .
① Check two o The characters of
[[email protected] ~]# grep -n 'o\{2\}' test.txt
3:The home of Football on BBC Sport online.
5:google is the best tools for search keyword.
8:a wood cross!
11:#woood # 12:#woooooood #
14:I bet this place is really spooky late at night!
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
② Query to w Begin with d ending , The middle contains 2~5 individual o String
[[email protected] ~]# grep -n 'wo\{2,5\}d' test.txt
8:a wood cross! 11:#woood #
- 1.
- 2.
③ Query to w Begin with d ending , The middle contains 2 Or 2 More than o String
- 1.
- 2.
- 3.
- 4.
One 、sed Editor
sed Is a flow editor , The stream editor will edit the data stream based on a set of rules provided in advance before the editor processes the data .
1、sed Editor workflow
sed The editor can process the data in the data stream according to the command , These commands are either entered from the command line , Or stored in a command text file .
sed The workflow of mainly includes reading 、 Perform and display three processes :
● Read : sed From the input stream ( file 、 The Conduit 、 The standard input ) Read a line in and store it in a temporary buffer ( Also called pattern space ,pattern space)
● perform : By default , be-all sed Commands are executed sequentially in pattern space , Unless the address of the line is specified , otherwise sed The command will be executed on all lines in turn .
● Show : Send the modified content to the output stream . After sending the data , Mode space will be cleared . Before all the contents of the file are processed , The above process will be repeated , Until all content is processed .
Before all the contents of the file are processed , The above process will be repeated , Until all content is processed .
Be careful : By default, all sed Commands are executed in pattern space , So the input file doesn't change , Unless you're using redirection to store output .
2、sed Command format
Command format :
sed -e ' Format ' file 1 file 2 ...
sed -n -e ‘ operation ’ file 1 file 2 ...
sed -f Script files file 1 file 2 ...
sed -i -e ' operation ' file 1 file 2 ...
- 1.
- 2.
- 3.
- 4.
sed -e ' n {
operation 1
operation 2
...
} ' file 1 file 2
- 1.
- 2.
- 3.
- 4.
- 5.
3、 Common options
-e or - -expression=: Indicates that the input text file is processed with the specified command , Only one operation command can be omitted , One It is generally used when executing multiple operation commands
f or - -file=: Indicates that the input text file is processed with the specified script file .
h or - -help: Display help .
-n、- -quiet or silent: prohibit sed Editor output , But you can p Command to complete the output .
-i: Modify the target text file directly .


4、 Common operations
s: Replace , Replace specified characters .
d: Delete , Delete selected rows .
a: increase , Add a line below the current line to specify .
i: Insert , In the selected line , Insert a specified line above .
c: Replace , Replace the selected row with the specified content .
y: Character conversion , The character length before and after conversion must be the same .
p: Print , If you also specify a row , Indicates to print the specified line ; If no line is specified , It means printing everything ; If there are non printing characters , with ASCII Code output . It is usually associated with “-n” Use options together
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
=: Print line number .
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
l ( A lowercase letter L): Print text in the data stream and unprintable ASCII character ( Like the terminator $、 tabs \t)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
5、 Use address to find
sed The editor has 2 Address mode :
1、 Represent row intervals in numerical form
2、 Use text mode to filter travel

sed -n '1p' abc.txt # Print the first line
- 1.

sed -n '$p' abc.txt # Print the last line
- 1.
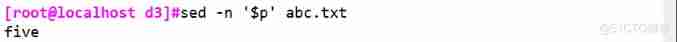
sed -n '1,3p' abc.txt # Print one to three lines
- 1.

sed -n '3,$p' abc.txt # Print three to the last line
- 1.

sed -n '1, +3p' abc.txt # Print 1 And then the continuity 3 That's ok , namely 1-4 That's ok
- 1.

sed '3q' abc.txt # Before printing 3 Exit after line information ,q Exit
- 1.

sed -n 'p;n' abc.txt # Print odd lines ; n Move to the next line
- 1.

sed -n 'n;p' abc.txt # Print even lines
- 1.

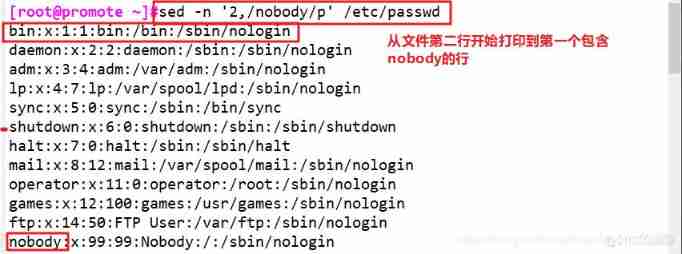
sed -n '2,${n;p}' abc.txt # Start with the second line ,n Move the next line ,p Print , Means to print odd lines
- 1.

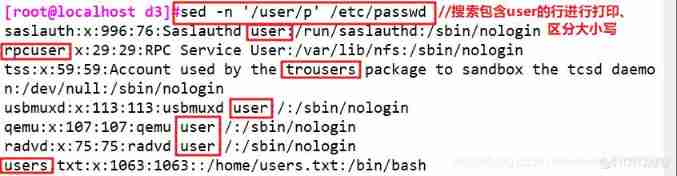
sed -n ' /user/p' /etc/passwd #// Search contains user Print the lines of , Case sensitive
- 1.
sed -n ' /^a/p' /etc/passwd # Search for a Print the first line
- 1.

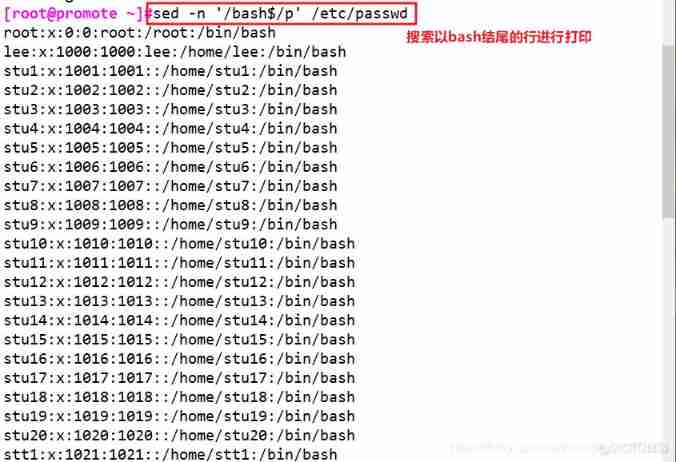
sed -n '/bash$/p' /etc/passwd # Print to bash The line at the end
- 1.
sed -n '/ftp\|root/p' /etc/passwd # Search contains ftp perhaps root Print the lines of
- 1.
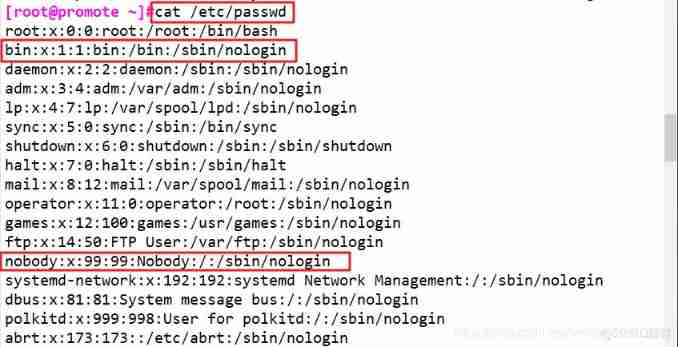
sed -nr '/ro{1,}t/p' /etc/passwd #-r Indicates support for regular expressions
- 1.
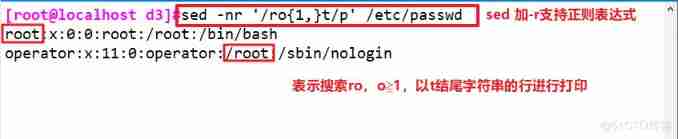
6、 Delete row
sed 'd' abc.txt # Do not specify line number , Delete all
- 1.

sed '3d' abc.txt # Delete the third line
- 1.

sed '2,4d' abc.txt # Delete 2-4 That's ok
- 1.

sed '$d' abc.txt # Delete last line
- 1.

sed '/^$/d' abc.txt # Delete blank lines
- 1.
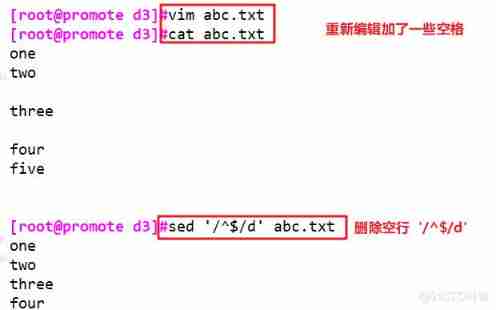

sed '/nologin$/d' /etc/passwd # Delete include nologin Lines of characters
- 1.
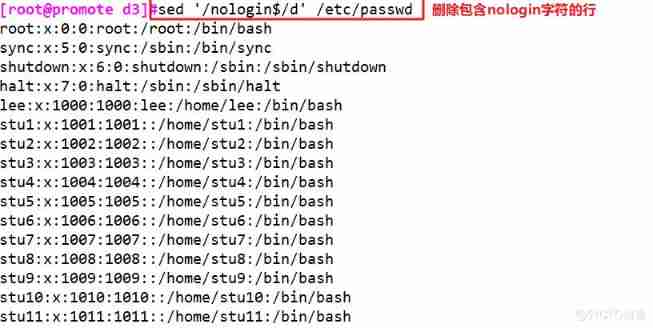
sed '/nologin$/!d' /etc/passwd # Do not delete contains nologin The line of
- 1.
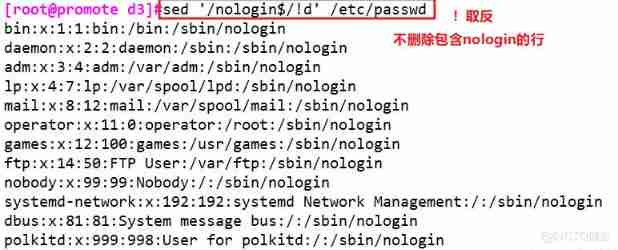
sed '/2/,/3/d' abc.txt
- 1.

sed '/1/,/3/d' abc.txt
- 1.

7、 Replace
Line scope s/ Old characters / New character / Replace mark
- 1.
4 Two alternative markers
Numbers : Indicates where the new string will replace the match
g: Indicates that the new character will replace all matches
p: Print the line that matches the replace command , And -n Use it together
w file : Write the result of the replacement to a file
sed -n 's/root/admin/p' /etc/passwd # Will match the first of the lines root Change to admin
- 1.

sed -n 's/root/admin/2p' /etc/passwd # The second... Of the line will be matched root Change to admin
- 1.

sed -n 's/root/admin/gp' /etc/passwd # Will match all of the root Change to admin
- 1.

sed '1,20 s/^/#/' /etc/passwd #1-20 Add... At the beginning of the line # Number
- 1.
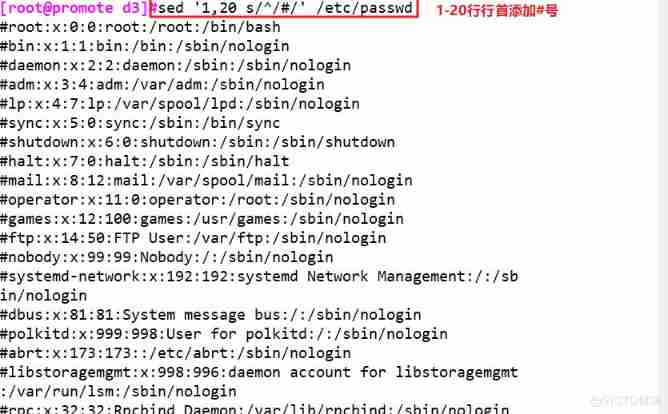
sed '^root/ s/$/#' /etc/passwd # In order to root Beginning line , Add at end of line # Number
- 1.

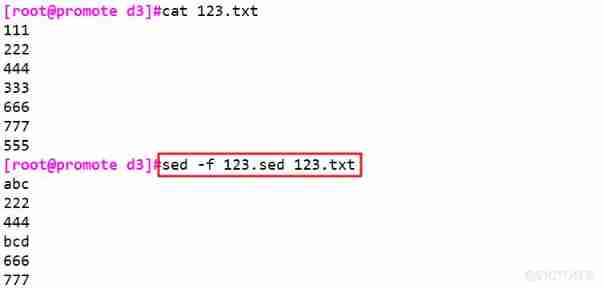
sed -f 123.sed 123.txt #-f Process the input file with the specified script file
- 1.

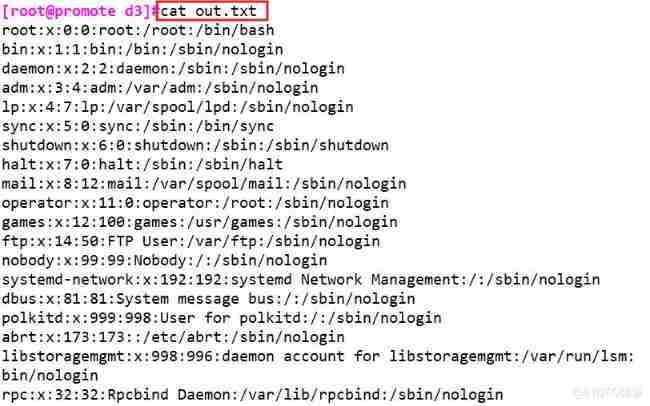
sed '1,20w out.txt' /etc/passwd
- 1.
sed -n 's/\bin\/bash\/bin\/csh/p' /etc/passwd
- 1.

8、 Insert
sed '/55/c ABC' 123.txt # Will contain 55 The line of , Replace with ABC
- 1.

sed '1,3a ABC' 123.txt # In the first line to the third line , Insert... Under the line ABC
- 1.

sed '1i ABC' 123.txt # In the first line , Insert... On line ABC
- 1.

sed '5r /etc/resolv.conf' 123.txt # Import the file after the fifth line
- 1.

One 、sort command
Sort the contents of the file in behavioral units , It can also be sorted according to different data types
Grammar format :
sort Options Parameters
cat file | sort Options
- 1.
- 2.
Common options :
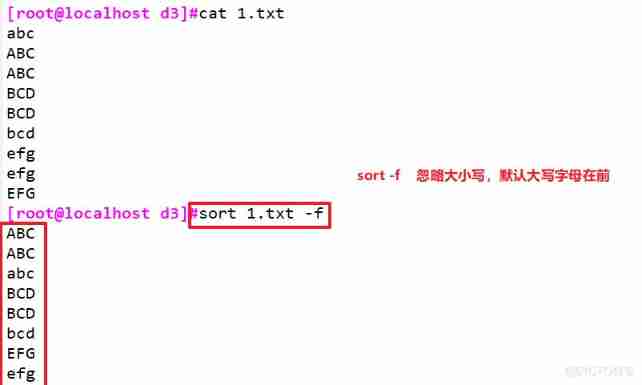
① -f: Ignore case , By default, uppercase letters come first
② -b: Ignore spaces before each line
③ -n: Sort by number
④ -r: Reverse sorting
⑤ -u: equivalent uniq, Indicates that only one row of the same data is displayed , duplicate removal
⑥ -t: Specifies the field separator , By default tab The key to separate
⑦ -k: Specify sort fields
⑧ -o < The output file >: Transfer the sorted results to the specified file


Two 、uniq command
Used to report or ignore consecutive duplicate lines in the file , Often with sort Command in combination with
Grammar format :
uniq Options Parameters
cat file | uniq Options
- 1.
- 2.
Common options :
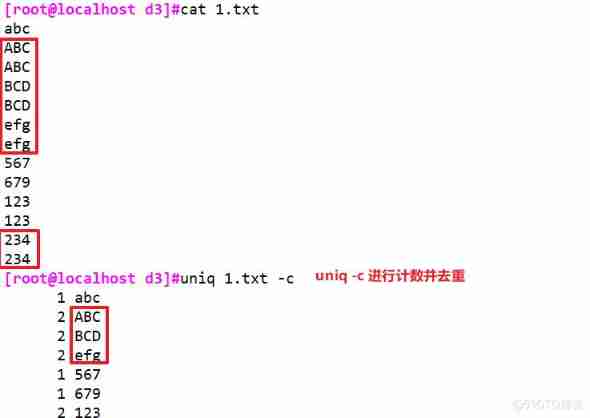
① -c: Count , And delete the repeated lines in the file
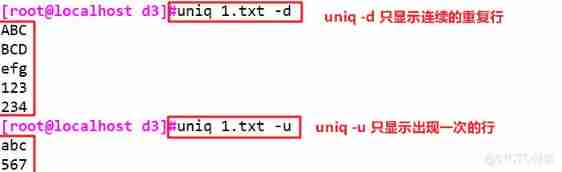
② -d: Show only consecutive repeating lines
③ -u: Show only rows that appear once
3、 ... and 、tr command
It is often used to replace characters from standard input 、 Compress and delete
Grammar format :
tr Options Parameters
- 1.
Common options :
① -c: Preserve the character set 1 The characters of , Other characters ( Include line breaks \n) With the character set 2 Replace
② -d: Delete all characters that belong to the character set 1 The characters of
③ -s: Compress the repeated string into a string , With the character set 2 Replace Character set 1
④ -t: Character set 2 Replace Character set 1, Without options, it is the same as the result
Parameters :
Character set 1:
Specifies the original character set to convert or delete . When performing a transformation operation , Parameters must be used ” Character set 2“ When specifying the conversion operation , Parameters must be used ” Character set 2“ Specifies the target character set of the transformation . But when you delete , No parameters required ” Character set 2“
Character set 2:
Specifies the target character set to convert to
echo "abc" | tr 'a-z' 'A-Z'
echo -e "abc\ncabcdab" | tr -C "ab\n" "0"
echo -e "abc\ncabcdab" | tr -c "ab" "0"
echo 'hello world' | tr -d 'od'
echo "thissss is a text 1 innnnnnne." | tr -s 'sn'
Delete blank lines
echo -e "aa\n\n\n\n\nbb" | tr -s "\n"
cat testfile4| tr -s "\n"
Put the colon in the path variable ":", Replace with a newline "\n"
echo $PATH | tr -s ":" "\n"
echo -e "aa\n\n\n\n\nbb" | tr -s "\n" ":"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
One 、awk
1、 working principle :
Read the text line by line , The default is space or tab Key to separate the separator , Save the separated fields to the built-in variables , And execute the edit command according to the mode or condition .
sed Commands are often used for a whole line of processing , and awk They tend to divide a line into multiple “ Field ” And then deal with it .awk Information is also read line by line , The execution result can be obtained through print To print and display field data . In the use of awk In the course of the order , You can use logical operators “&&” Express “ And ”、“||” Express “ or ”、“!” Express “ Not ”; You can also do simple mathematical operations , Such as +、-、*、/、%、^ Respectively means plus 、 reduce 、 ride 、 except 、 The remainder and the power .
2、 Command format :
awk Options ' Mode or condition { operation }' file 1 file 2 …
awk -f Script files file 1 file 2 …
- 1.
- 2.
3、awk Common built-in variables ( Can be directly used ) As shown below :
FS: Column separator . Specify the field separator for each line of text , Default to space or tab stop . And "-F" The same effect
NF: Number of fields in the row currently processed .
NR: Line number of the currently processed line ( Ordinal number ).
$0: The entire contents of the currently processed row .
$n: Of the current processing line n A field ( The first n Column ).
FILENAME: File name processed .
RS: Line separator .awk When reading from a file , Based on the RS The definition of cut data into many records , and awk Read only one record at a time , To deal with . The default is ’\n’
4、 Output text by line :
awk '{print}' 1.txt # Output everything
awk '{print $0}' 1.txt # Output everything
- 1.
- 2.


awk 'NR==1,NR==3{print}' 1.txt # Output No 1~3 Row content
awk '(NR>=1)&&(NR<=3){print}' 1.txt # Output No 1~3 Row content
- 1.
- 2.

awk 'NR==1||NR==3{print}' testfile2 # Output No 1 That's ok 、 The first 3 Row content
- 1.

awk '(NR%2)==1{print}' testfile2 # Output the contents of all odd lines
awk '(NR%2)==0{print}' testfile2 # Output the contents of all even lines
- 1.
- 2.

awk '/^root/{print}' /etc/passwd # Output to root Beginning line
- 1.

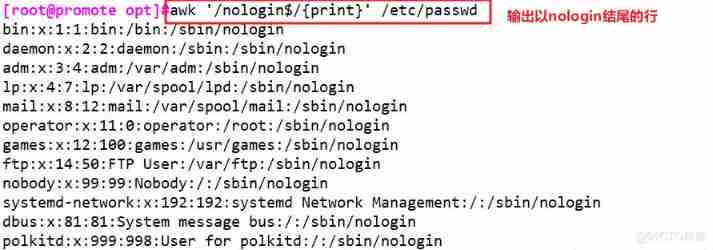
awk '/nologin$/{print}' /etc/passwd # Output to nologin The line at the end
- 1.
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd # Statistics to /bin/bash Number of lines at the end , Equate to grep -c "/bin/bash$" /etc/passwd
- 1.


5、 Output text by field :
awk -F ":" '{print $3}' /etc/passwd # Output in each line ( Separated by spaces or tab stops ) Of the 3 A field
- 1.
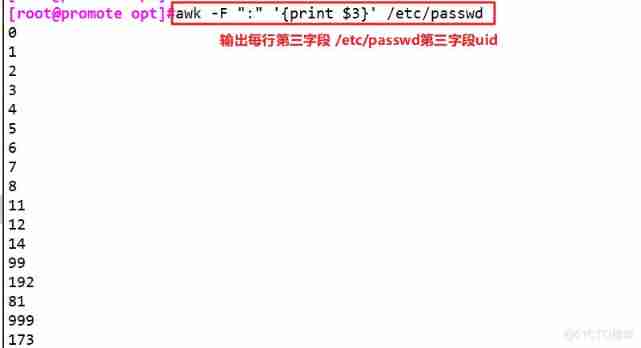
awk -F ":" '{print $1,$3}' /etc/passwd # Output the 1、3 A field
- 1.

awk -F ":" '$3<5{print $1,$3}' /etc/passwd # Output No 3 Field values are less than 5 Of the 1、3 Field contents
- 1.

awk -F ":" '!($3<200){print}' /etc/passwd # Output No 3 The value of each field is not less than 200 The line of
- 1.
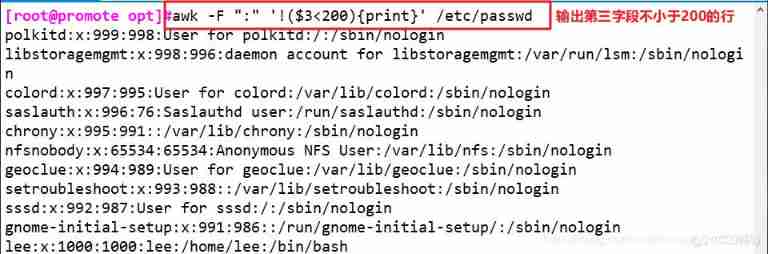
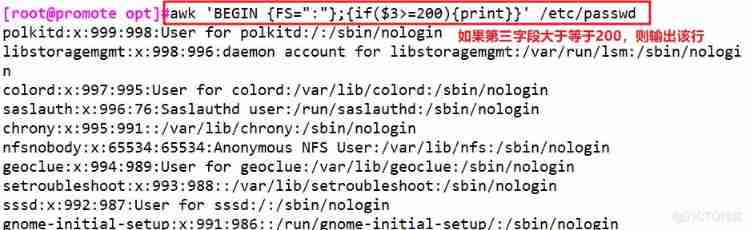
awk 'BEGIN {FS=":"};{if($3>=200){print}}' /etc/passwd # I'll finish it first BEGIN The content of , And print out the contents of the text
- 1.
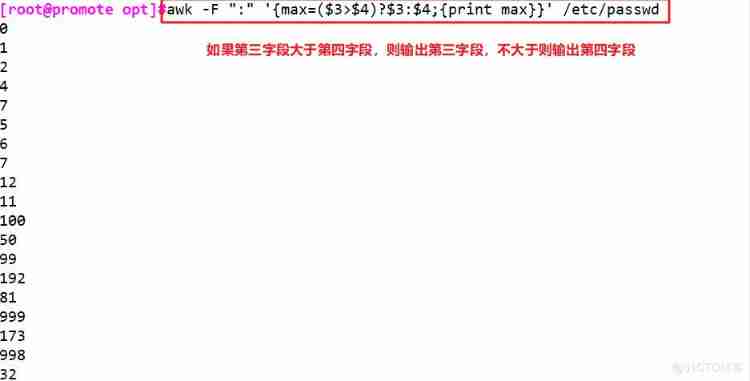
awk -F ":" '{max=($3>$4)?$3:$4;{print max}}' /etc/passwd #($3>$4)?$3:$4 Ternary operator , If the first 3 The value of field is greater than 4 Values for fields , Then put the 3 The value of a field is assigned to max, Otherwise, No 4 The value of a field is assigned to max
- 1.
awk -F ":" '{print NR,$0}' /etc/passwd # Output each line content and line number , Every time a record is processed ,NR It's worth adding 1
- 1.
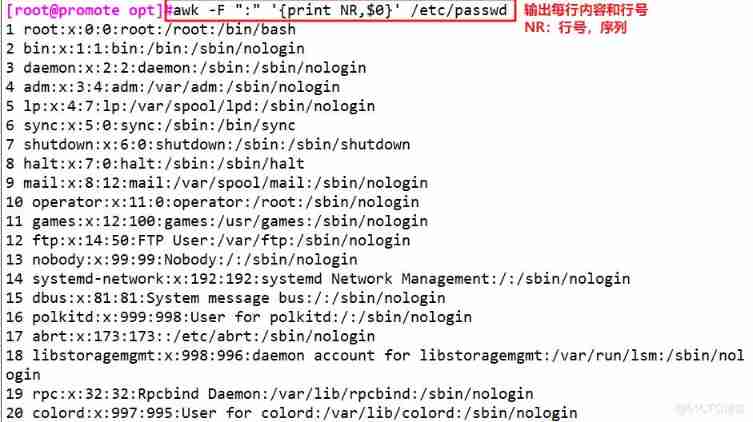
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd # The output is colon delimited and the 7 Field (s) /bash Of the lines 1 A field
- 1.

awk -F ":" '($1~"root")&&(NF==7){print $1,$2}' /etc/passwd # Output No 1 Field (s) root And there are 7 The number of fields in the row 1、2 A field
- 1.

awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd # Output No 7 Fields are neither /bin/bash, Not for /sbin/nologin All of the line
- 1.

6、 Through pipes 、 Double quotes call Shell command :
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}' # Count the number of colon separated text paragraphs ,END{} In the block , Often put in the print results and other statements
- 1.

awk -F: '/bash$/{print | "wc -l"}' /etc/passwd # call wc -l Command statistics usage bash Number of users , Equate to grep -c "bash$" /etc/passwd
- 1.

free -m | awk '/Mem:/ {print int($3/($3+$4)*100)}' # View the current memory usage percentage
- 1.

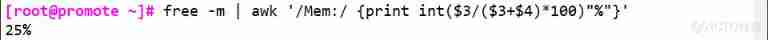
top -b -n 1 | grep Cpu | awk -F ',' '{print $4}' | awk '{print $1}' # View the current CPU Idle rate ,(-b -n 1 It means that you only need 1 The output of times )
- 1.

date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S" # Display the last system restart time , Equate to uptime;second ago To show how many seconds ago ,+"%F %H:%M:%S" Equate to +"%Y-%m-%d %H:%M:%S" Time format of
- 1.

awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}"%"}' # call w command , And used to count the number of online users
- 1.

awk 'BEGIN {"hostname" | getline ; {print $0}}' # call hostname, And output the current host name
- 1.

When getline There is no redirection between left and right “<” or “|” when ,getline Applies to the current file , Read in the first line of the current file and give it the following variable var or $0; It should be noted that , because awk Processing getline I've read in a line before , therefore getline The returned result is interlaced .
When getline There are redirections on the left and right “<” or “|” when ,getline Then it acts on the directed input file , Since the file is just opened , Not by awk Read in a line , It's just getline Read in , that getline What is returned is the first line of the file , Instead of interlacing .
seq 10 | awk '{print $0; getline}'
seq 10 | awk '{getline; print $0}'
- 1.
- 2.

边栏推荐
- Correlation analysis summary
- [BSP video tutorial] stm32h7 video tutorial phase 5: MDK topic, system introduction to MDK debugging, AC5, AC6 compilers, RTE development environment and the role of various configuration items (2022-
- 2/14 (regular expression, sed streaming editor)
- Fluent learning (4) listview
- Report on prospects and future investment recommendations of China's assisted reproductive industry, 2022-2028 Edition
- Les sociétés de valeurs mobilières dont la Commission d'ouverture d'un compte d'actions est la plus faible ont ce que tout le monde recommande.
- What is the Valentine's Day gift given by the operator to the product?
- Gorilla/mux framework (RK boot): add tracing Middleware
- The difference between single power amplifier and dual power amplifier
- Idea a method for starting multiple instances of a service
猜你喜欢

Double efficiency. Six easy-to-use pychar plug-ins are recommended

SPI based on firmware library

Report on prospects and future investment recommendations of China's assisted reproductive industry, 2022-2028 Edition
![[MySQL] classification of multi table queries](/img/96/2e51ae8d52ea8184945e0540ce18f5.jpg)
[MySQL] classification of multi table queries

Idea a method for starting multiple instances of a service
Pytorch learning notes 5: model creation

Briefly understand the operation mode of developing NFT platform
Private project practice sharing populate joint query in mongoose makes the template unable to render - solve the error message: syntaxerror: unexpected token r in JSON at

Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?

I wrote a chat software with timeout connect function
随机推荐
Tencent interview: can you find the number of 1 in binary?
EPF: a fuzzy testing framework for network protocols based on evolution, protocol awareness and coverage guidance
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Fudan 961 review
Gossip about redis source code 74
NPM script
NLP pre training technology development
[Happy Valentine's day] "I still like you very much, like sin ² a+cos ² A consistent "(white code in the attached table)
Collation of the most complete Chinese naturallanguageprocessing data sets, platforms and tools
Gossip about redis source code 78
Deep learning ----- using NN, CNN, RNN neural network to realize MNIST data set processing
P1339 [USACO09OCT]Heat Wave G
Subgraph isomorphism -subgraph isomorphism
I would like to ask how the top ten securities firms open accounts? Is it safe to open an account online?
leetcode-43. String multiplication
What is the difference between NFT, SFT and dnft? How to build NFT platform applications?
Investment demand and income forecast report of China's building ceramics industry, 2022-2028
Idea integrates Microsoft TFs plug-in
[BSP video tutorial] stm32h7 video tutorial phase 5: MDK topic, system introduction to MDK debugging, AC5, AC6 compilers, RTE development environment and the role of various configuration items (2022-
Gossip about redis source code 83