A lot of technicians have high requirements for themselves in their profession , Work hard , Take on more and more responsibility , Finally get trust , Promoted to a management position . But often lack of professional management knowledge , You can't optimize the workflow from the overall scope in your work , Still “ Personal contributor ” How it works , When you encounter problems, you should do it yourself , Often delayed their own work . So I read a lot of books , Read a lot of articles , Learned a lot “ The art of being human ” and “ Enterprise development strategy ”, Finally, I became the director of R & D department , Technology is becoming obsolete . What is management , Are technology and management two different directions ?
No, it isn't . Both technology and management should do quantitative analysis , Global optimization , There are many similar approaches . Here is a system performance optimization scenario as an example , You can experience :
There's a program in the company , Running on the 10 On a cluster of servers . Now the volume of business has increased , The request can't be processed . Come to the boss , I want you to optimize this program . Get this headache task , You get people from all departments of development, testing, operation and maintenance to have a meeting to find a way , Some people say the database needs to be upgraded , Some people say that the code is too bad to optimize , Some people say that there are too few machines to add 5 platform , Others say we need to change the architecture to the cloud , After going to the cloud, there is no such problem again . Who should you listen to ?
Don't worry about it . There is a saying called “ No metrics, no optimizations ”, First of all “ Measure ” This phenomenon . Get the designers first , Find out what this program does , What is the workflow like .
Application architecture : This program deals with the business of picture recognition , Receive pictures from the network port , Identify the information in the picture , And then compare it in the picture library , Finally, similar images are output . The process is like this :
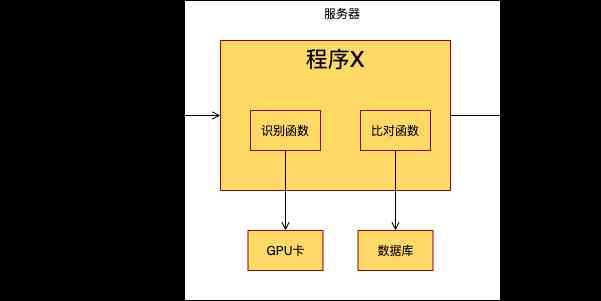
Figure out the program architecture , Next we need to measure the data . There's some data that's easy to get , There are still some data that no one seems to know . So you give the R & D team a task , Put them in the program , Collect some data as soon as possible . The developers changed a version of the program , Deploy it . Running on the production line all day , Get some data indicators :
- Input : It needs to be dealt with every day 100 Ten thousand pictures , This is from the upstream process
- Identification function : distinguish 1 The average time of a picture is 0.5 second
- Alignment function : comparison 1 The average time of pictures is 0.4 second
Now let's calculate : Handle 1 The time of the picture is 0.9 second (0.5 + 0.4),1 Taiwan machine 1 Days can process pictures 96000(86400 / 0.9),10 Taiwan machine 1 Days can process pictures 96 ten thousand (96000 * 10), To reach 100 ten thousand . To complete every day 100 Million processing capacity , Server required 10.4 platform (100 ten thousand / 96000), About equal to 11 platform .
You have to tell the boss if you want to buy a server :“ Need to buy 1 Servers , belt GPU Of !”. Don't worry .
Let's analyze the running process of the program : Identification and comparison functions are executed serially . Identify when the function is busy , The comparison function is idle , It's waiting for the result of recognition . alike , When the function is busy , There's nothing to do with identification functions . in other words , The resources of the server are not fully utilized ,GPU There's a lot of waste in card and database resources .
How to improve the utilization of resources ? You can change the architecture of the program , Adjust it to the following :
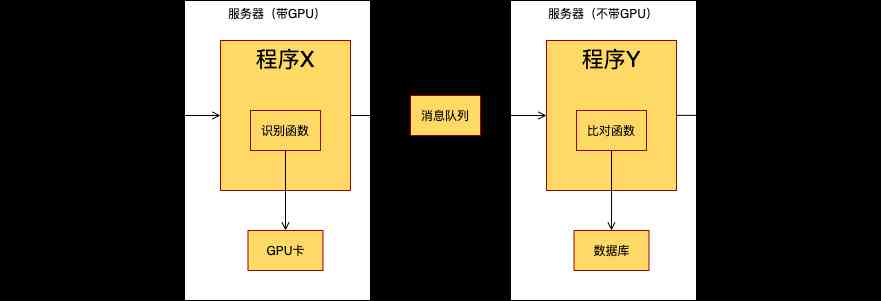
Split the original program in two , Deployed on two servers respectively , In the middle, a message queue is used to exchange data . Now both programs can make full use of the server's resources . Let's calculate throughput again :
- Program X: Processing an image requires 0.5 second ,1 Servers 1 Days processing pictures 172800(86400 / 0.5),100 Ten thousand pictures need a server 5.8 platform (100 ten thousand / 172800), About equal to 6 platform .
- Program Y: Processing an image requires 0.4 second ,1 Servers 1 Days processing pictures 216000(86400 / 0.4),100 Ten thousand pictures need a server 4.6 platform (100 ten thousand / 216000), About equal to 5 platform .
Still need servers 11 platform , There seems to be no improvement . Let's analyze it again : The original plan needs 11 Stage belt GPU Server for , Now it's just a matter of 6 platform , We saved 5 block GPU card , This is already a lot of expenses .
The architect provides another message : In the original plan , Identification function and comparison function are executed in serial , So it can only be executed with the same number of concurrent threads . The new program has been separated into two programs , So the comparison function can set a higher number of concurrent threads , Can be raised to the original 4 times .
This is good news , Program Y The throughput of can be improved 4 times , thus , It only needs 1.16 Servers can handle 100 All the data , About equal to 2 platform .
According to the improved architecture , It only needs 6 Stage belt GPU Server for , add 2 The stage doesn't bring GPU Server for , In total, we need 8 Servers . Not only can the processing task be completed , You can also reserve some GPU card , For future business development .
The example is over , The above is to optimize one IT The process of system efficiency . Actually , Business management is a similar process , It's just that the objects of optimization are no longer machines and programs , It's a human activity . In a software company , There is a need to collect 、 Product development 、 Project implementation and other processes , Sometimes these processes get stuck 、 The slow phenomenon , It looks like it's with a IT The problem with the system is the same . There is a famous question :“ In your team , How long does it take for a change involving only one line of code to go online ?” From demand to delivery , How far is it . We may have problems like this all the time : A site operation and maintenance feedback a defect , It looks like a small problem , It's not too much trouble to fix , It took a long time to solve . Looking back on the issue afterwards , People in every department have something to say :
- Operation and maintenance : As soon as I found out the problem , It's just Jira On the platform , At that time, there was no response from the development , I'm off work .
- Development : I was working on a new version of the functionality , Write a complex piece of code . When I see this problem , It's time to get off work . Operation and maintenance only describes the problem phenomenon , There is no description of the version of the field deployment . I don't know which version to fix this problem on , I had to change it in the latest release , Then send the package to the test . I am here Jira I've heard back from you , Ask the operation and maintenance department to send out the site version number ;
- test : I received the development package , I'm going to do a test . The entire integrated environment has been upgraded , I need to restore the test environment to the old version . I've been doing this all morning , I had a test in the afternoon , Several defects were found , Put the problem to the development .
- Development : I received the test from Bug, After the revision, another version was issued . There should be no problem this time .
- Operation and maintenance : The package on the environment has no version identifier , It took me a long time to check all versions of Md5 code , Just found the version number , stay Jira Last time . This is an urgent problem , I want to solve it as soon as possible , So I gave the latest version of the test to me , I want to try to install . I don't know if this package is compatible with the live environment , Just try . I spent a day in a pre release environment , I didn't put him on , It doesn't seem to work .
- Development : I see the live version number , This is a very old version , It's been more than a year . I've only been in this program for three months , On wechat AT Several people . I don't know where the code baseline is , It took a long time to find . It's late after the repair . It's still up to the test .
- test : The integrated environment still needs to be restored , I worked on it for three hours . The test confirmed that there was no problem , It's up to O & M .
- Operation and maintenance : I received the installation package , I tried it in a pre release environment , No problem . The production environment is a little more troublesome , I started by updating only one node , It is found that problems still appear intermittently . It was only later that I learned that there was to be 2 Nodes also need to be deployed . This time it took a day , The next time it happens , I knew what to do .
From everyone's point of view , I'm very busy , It took a lot of time to solve the problem . But from the perspective of defect resolution , Things are constantly stuck 、 wait for . In the course of these labors , Really effective 、 How much labor can produce value ? This is it. DevOps The problem of value flow that needs to be solved , There needs to be a system , Measure the process , Constantly optimize it .
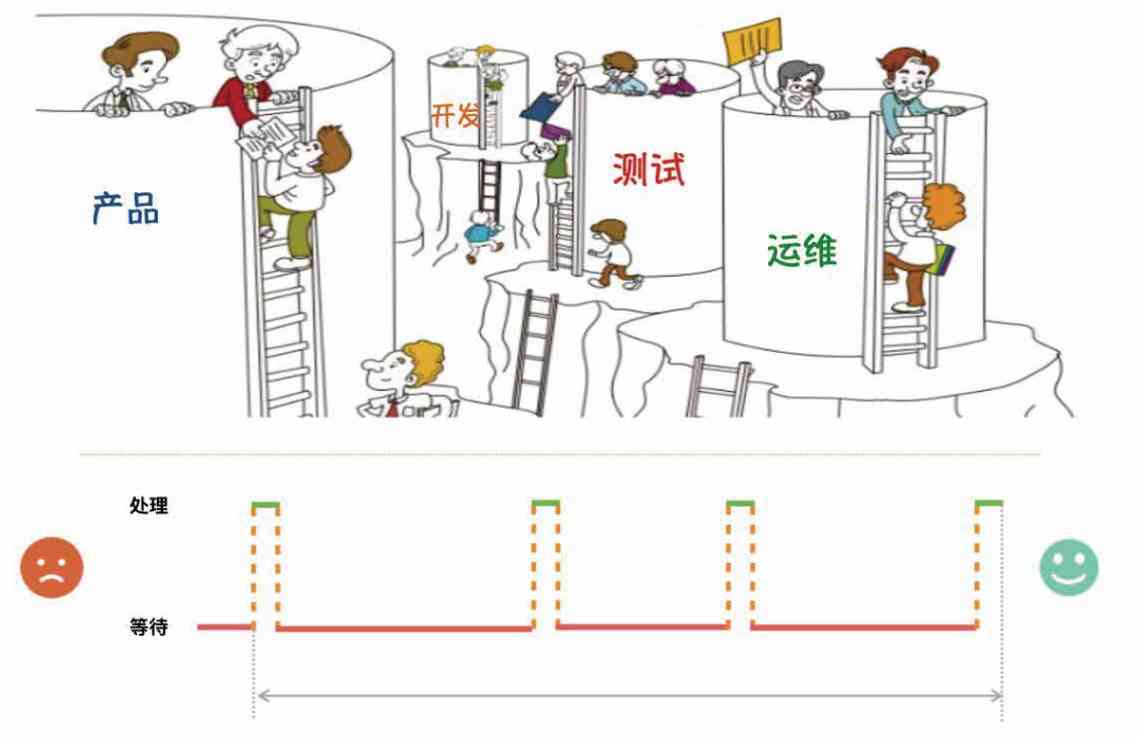
From the above defect solving process , There are a lot of problems in the technical department , Some of the problems are single point , such as :
- Code management : The code baseline is not clear , Version cannot be traced back
- Release management : The release document is not properly kept
- version management : The version number is not clearly marked , The number is not clear . Unable to determine the compatibility between the old and new versions
- Infrastructure management : There is no way for R & D personnel to get infrastructure quickly , It takes a long time to build a test environment
- Deployment management : Testers deploy manually , It takes a long time to complete a deployment
- Environmental management : Which processes are deployed on the server in the field , There is no set of management methods , You need to log in to see
See these problems , Can we start to improve ? Don't worry . Like optimizing a IT The system is the same , We need to figure out the workflow , And then measure the process , And then optimize it as a whole . When the overall situation is not clear , Local optimization is useless , Optimize the efficiency of a local , May backfire , Causing more waste .
Clarify the overall process , Of course, there are many difficulties . One big problem is : Enterprise workflow is not like IT The system flow is as clear as .IT The system generally has various documents , At least the source code can be viewed . Enterprise workflow often has some fuzzy place , The definition of department and post responsibilities is not very clear . People are not like programs “ obedient ”, In order to complete one's own work task , People are creative . So every enterprise has to sort out the position and workflow , Try to sort out these fuzzy processes , According to their own business characteristics to develop a set of process specifications , It's a very necessary job . People in technical positions are more familiar with the actual workflow , They go into management positions , There are advantages in this respect .
After the workflow is clear , We can measure the process nodes . We can use visualization technology to analyze the data , For example, Kanban 、 Resource input status 、 Mission burndown charts and so on , Looking for Caton , Identify bottleneck resources . There are some scientific ways to do this , The software industry is also learning the theory of lean production from the manufacturing industry . For a large-scale software enterprise , There has been improvement in management , The resulting efficiency gains are huge .