当前位置:网站首页>Using thread communication to solve the problem of cache penetrating database avalanche
Using thread communication to solve the problem of cache penetrating database avalanche
2020-11-07 18:55:00 【lis1314】
Business scenario :
There is one aspect C The query interface of the end , A lot of visits , Suppose we use caching technology for traditional optimization , The first time you query data , Check cache -> The cache does not -> Database search -> Write cache
But there may be a problem 、 There are many users at the same time ( hypothesis 1W) Query the same data ( Suppose the commodity ID Agreement )、 At this point, the data is not being cached 、 May cause database avalanche , The reason is that at this moment, the same data may be used for the database 1W Time of SQL Inquire about ( The write ahead caching scheme is not discussed here , At the same time, it's said here 1W This is an extreme situation ).
How do we optimize , This is the focus of this article :
Thought effect :
No matter how many users access the query 、 Let's say they query the product data for ID Agreement 、 So it only produces 1 Queries 、 Other user threads share the same query result , So it's from n(10000) Turned into 1.
This scheme is suitable for any scenario where multithreading works to remove duplication and improve performance , This is just one of the scenes .
The implementation is discussed below :
A、B、C 3 Three threads simultaneously query products ID by 1 The data of , Traditional cache optimization when there is no data in the cache , By the church 3 individual SQL Query access database , example sql:select * from products where id = 1;
So how do we use row level locks ( user ID dimension ) In order to achieve A、B、C,3 Each thread only queries the database once to get the corresponding result ?
Ideas : First, we need a communication dimension ( user ID Consensus is the same behavior ), If the user accessing the parameter ID equally , We can achieve the following effect :
The first thread that enters performs the query operation ( The assumption is A), that B、C Thread we put him in a waiting state , Wait for thread A Query results of , Finally, we can query the database only once .
Code inspiration from Alibaba open source cache framework jetcache, Here is the improved public implementation , Can be used in general
package com.xxx.utils.sync;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
import org.slf4j.Logger;
import com.alibaba.fastjson.JSON;
/**
* Synchronization tool class <br/>
* Cache optimization mainly prevents avalanches 、 Data avalanche </br>
* In the case of multithreading access 、 Think of it as a repetition of the same operation
*
*/
public class SyncUtil {
private static final Logger logger = org.slf4j.LoggerFactory.getLogger(SyncUtil.class);
private ConcurrentHashMap<Object, LoaderLock> loaderMap = new ConcurrentHashMap<>();
private Function<Object, Object> KeyConvertor;
public SyncUtil() {
this(null);
}
/**
* @param KeyConvertor Set up key Conversion rules <br/>
* Can be null , By default fastJson
*
*/
public SyncUtil(Function<Object, Object> KeyConvertor) {
if(KeyConvertor == null) {
this.KeyConvertor = new Function<Object, Object>() {
@Override
public Object apply(Object originalKey) {
if (originalKey == null) {
return null;
}
if (originalKey instanceof String) {
return originalKey;
}
return JSON.toJSONString(originalKey);
}
};
}else {
this.KeyConvertor = KeyConvertor;
}
}
/**
* Synchronous loading function <br/>
* for example :A、B、C Three threads query at the same time to perform an operation ( Query database, etc ), In fact, the query parameters are the same <br/>
* At this time, we can optimize the thread 、 Prevent data avalanche, cache penetration , Let one of the threads check the database , Other threads wait for the return result of the specific worker thread <br/>
* Such as :A The thread searches the database 、B、C The thread waits A The return result of the thread .
* @param <K>
* @param <V>
* @param timeout Waiting time ( millisecond )( hypothesis A Thread query exceeded waiting time 、 that B、C Threads give up waiting for themselves to execute business queries )
* @param key Identify whether it is the same operation key
* @param loader Function to load data <br/>
* Function<String, String> loader = new Function<String, String>() {
@Override
public String apply(String t) {
return "dbData";
}
};
*
* @return
*/
@SuppressWarnings("unchecked")
public <K, V> V synchronizedLoad(Integer timeout, K key, Function<K, V> loader) {
Object lockKey = buildLoaderLockKey(key);
while (true) {
// Whether there are threads to do specific logic to obtain business data
boolean create[] = new boolean[1];
LoaderLock ll = loaderMap.computeIfAbsent(lockKey, (unusedKey) -> {
create[0] = true;
LoaderLock loaderLock = new LoaderLock();
loaderLock.signal = new CountDownLatch(1);
loaderLock.loaderThread = Thread.currentThread();
return loaderLock;
});
if (create[0] || ll.loaderThread == Thread.currentThread()) {
try {
// The first incoming thread performs the actual access operation
V loadedValue = loader.apply(key);
ll.success = true;
ll.value = loadedValue;
return loadedValue;
} finally {
if (create[0]) {
ll.signal.countDown();
loaderMap.remove(lockKey);
}
}
} else {
// Other threads are waiting
try {
if (timeout == null) {
ll.signal.await();
} else {
boolean ok = ll.signal.await(timeout, TimeUnit.MILLISECONDS);
if (!ok) {
// If the wait times out , Give up waiting , The current thread accesses directly
logger.info("loader wait timeout:" + timeout);
return loader.apply(key);
}
}
} catch (InterruptedException e) {
logger.warn("loader wait interrupted");
return loader.apply(key);
}
// Share the same return result
if (ll.success) {
return (V) ll.value;
} else {
continue;
}
}
}
}
private Object buildLoaderLockKey(Object key) {
return KeyConvertor.apply(key);
}
static class LoaderLock {
CountDownLatch signal;
Thread loaderThread;
volatile boolean success;
volatile Object value;
}
}
Test code
package test;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.function.Function;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import com.xxx.MessageServiceApplication;
import com.xxx.mapper.ActivityInfoMapper;
import com.xxx.model.ActivityInfo;
import com.xxx.utils.sync.SyncUtil;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = { MessageServiceApplication.class })
public class QueryTest {
@Autowired
private ActivityInfoMapper activityInfoMapper;
SyncUtil syncUtil = new SyncUtil();
private AtomicInteger count = new AtomicInteger();
private CyclicBarrier barrier = new CyclicBarrier(100);
ExecutorService pool = Executors.newFixedThreadPool(100);
public void synSelect(Long id) throws Exception {
for (int i = 0; i < 100; i++) {
pool.execute(()->{
try {
barrier.await();// Thread waiting , The effect of triggering multithreading synchronization
// realSelect1(id);// Traditional query
realSelect2(id);// After optimization
} catch (Exception e) {
e.printStackTrace();
}
});
}
pool.shutdown();
while(!pool.isTerminated()){
}
System.out.println();
}
public ActivityInfo realSelect2(Long id) {
// Access to thread communication
Function<Long,ActivityInfo> loader = (param)->{
// Record the actual number of visits to the database (1)
count.incrementAndGet();
return activityInfoMapper.selectById(param);
};
return syncUtil.synchronizedLoad(3000, id, loader);
}
public ActivityInfo realSelect1(Long id) {
// Record the actual number of visits to the database (100)
count.incrementAndGet();
return activityInfoMapper.selectById(id);
}
@Test
public void testSelect() throws Exception {
synSelect(1L);
System.out.println(" The actual number of calls ="+count.get());
}
}
Traditional query results
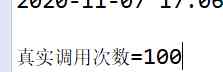
Optimized query results , Only execution 1 Time SQL
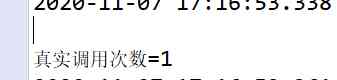
版权声明
本文为[lis1314]所创,转载请带上原文链接,感谢
边栏推荐
- How to solve the problem of blank page in Google Chrome browser
- Talk about sharing before paying
- Using LWA and lync to simulate external test edge free single front end environment
- Key points of C language -- index article (let you fully understand indicators) | understand indicators from memory | complete analysis of indicators
- Andque.
- jenkins pipline stage 设置超时
- 7.Swarm搭建集群
- Design pattern of facade and mediator
- Exception calling 'downloadstring' with '1' arguments: 'operation timed out'
- 你真的会使用搜索引擎吗?
猜你喜欢

【笔记】Error while loading PyV8 binary: exit code 1解决方法
git 提交规范
失眠一个整晚上
Mate 40系列发布 搭载华为运动健康服务带来健康数字生活
2020-11-06:go中,谈一下调度器。
如何解决谷歌Chrome浏览器空白页的问题
JS array the usage of array is all here (array method reconstruction, array traversal, array de duplication, array judgment and conversion)
VARCHART XGantt入门教程
Knowledge competition of garbage classification
深入浅出大前端框架Angular6实战教程(Angular6、node.js、keystonejs、
随机推荐
Logo design company, Nanjing
Kubernetes (1): introduction to kubernetes
Mobile pixel adaptation scheme
LEADTOOLS如何检测,读取和写入条形码
10000! Ideal car recalls all defective cars: 97 accidents have occurred and losses will be expanded
yum [Errno 256] No more mirrors to try 解决方法
使用LWA和Lync模拟外部测试无边缘单前端环境
失眠一个整晚上
confd
A kind of super parameter optimization technology hyperopt
Mac新手必备小技巧
ImageMagick - add watermark
In 2020, how can wechat seal numbers be quickly lifted?
Tips for Mac novices
抽絲剝繭——門面和調停者設計模式
Three steps to understand Kerberos Protocol easily
Python3 operating gitlab
课堂练习
2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
Using rabbitmq to implement distributed transaction