当前位置:网站首页>Transformer variants (spark transformer, longformer, switch transformer)
Transformer variants (spark transformer, longformer, switch transformer)
2022-07-25 12:02:00 【Shangshanxianger】

Before you know it Transformer It has gradually penetrated into all fields , On its own, it has also produced a considerable number of variants , Pictured above . The previous blog post of the blogger was updated Transformer variant (Star-Transformer,Transformer-XL), This article wants to sort out these two very important Transformer variant , Namely Sparse Transformer and Switch Transformer.

Explicit Sparse Transformer: : Concentrated Attention Through Explicit Selection
standard Transformer The complexity of is O(n^2), But is it necessary to pay attention to all the elements in the sequence , Is there a way to simplify this mechanism ? So this article's “Sparse” The point is that there are only a few token Participate in attention Calculation of distribution , To improve the concentration of attention mechanism . That is, originally, a word is only related to a few words , But standard self attention will assign weight to all words and then aggregate , A natural idea is through explicit selection , Just let the model focus on a few elements .
The model diagram is shown in the figure above , On the far left is the standard route for calculating attention , The middle is Sparse The implementation of the , You can see the difference is that there is a manually selected one in the middle Sparsification, On the far right is its execution diagram . Simply put, it's calculating softmax Score before top-k Select a few important elements . Specifically, first calculate the inner product : P = Q K T d P=\frac{QK^T}{\sqrt{d}} P=dQKT Then filter manually according to the inner product score top-k Elements , That is, in the following formula M operation , Other P Then set it directly to negative infinity , Such coercion only makes k Elements are concerned . A = s o f t m a x ( M ( P , k ) ) A=softmax(M(P,k)) A=softmax(M(P,k)) Finally, multiply the score back to V: C = A V C=AV C=AV Through this operation , It can make you pay more attention . This operation to reduce the amount of computation also makes GPT-3 When the model can be bigger and more violent, it has also achieved good results, but it doesn't work ...
- paper:https://arxiv.org/abs/1912.11637
- code:https://github.com/lancopku/Explicit-Sparse-Transformer

Longformer: The Long-Document Transformer
Longformer It is also a kind of classic Sparse The method of . A total of 3 Strategies :
Sliding Window: Pictured above (b) Shown , Follow CNN It's like , Given a fixed window size w, There is one on both sides w/2 individual token Instead of doing attention. The computational complexity is reduced to O(n x w), That is, the complexity is linear with the length of the sequence . And if you set different windows for each layer size It can well balance the efficiency and presentation ability of the model .
Dilated sliding window: As shown in the figure above , Similar expansion CNN, The receiving domain can be further expanded without changing the computational complexity . alike , If you set different expansion configurations on each head of the multi head attention mechanism , You can pay attention to different local contexts of the article , Especially through this Dilated Can expand even far away .
Global Attention : Pictured (d) Shown , Calculate the global token It may represent the overall characteristics of the sequence . such as BERT Medium [CLS] This function , The complexity is reduced to O(n)
The complete content can be seen in the original :
- paper:https://arxiv.org/pdf/2004.05150.pdf
- code:https://github.com/allenai/longformer
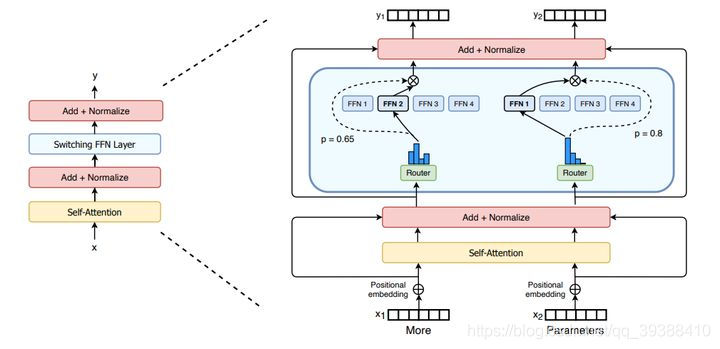
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Compared with Sparse Attention It is difficult to use sparse operators GPU、TPU Hardware performance problems .Switch Transformer Sparse operators are not required , Can better adapt to GPU、TPU And other dense hardware . The main idea is to simplify sparse routing . In natural language MoE (Mixture of experts) Layer , Only will token The performance will be better if the characterization is sent to a single expert instead of multiple . The model architecture is shown in the figure above , The blue part in the middle is the key part of price comparison , You can see every time router They only send information to scores p The largest single FFN. And this operation can greatly reduce the amount of calculation .
Then on the other hand , The reason for its success is that it has a very good parallel strategy , It also combines data parallelism + Model parallel +expert parallel . The details are as follows: :
In fact, according to the model architecture ,experts Parallelism is the parallelism between operators , Their corresponding FFN There is operator level model parallelism inside , And the whole experts On the computational graph, it is a multi parallel FFN Branch , This is inter operator model parallelism , So we can get lower communication overhead , Improve the efficiency of parallelism .
- paper:https://arxiv.org/abs/2101.03961
- code:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
The next article will continue to sort out the relevant content :
边栏推荐
- 【GCN-RS】Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for RS (SIGIR‘22)
- 【GCN-RS】Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for RS (SIGIR‘22)
- Risks in software testing phase
- [GCN multimodal RS] pre training representations of multi modal multi query e-commerce search KDD 2022
- Meta-learning(元学习与少样本学习)
- 【IMX6ULL笔记】--内核底层驱动初步探究
- [imx6ull notes] - a preliminary exploration of the underlying driver of the kernel
- 剑指 Offer 22. 链表中倒数第k个节点
- 对比学习的应用(LCGNN,VideoMoCo,GraphCL,XMC-GAN)
- [MySQL learning 08]
猜你喜欢

【GCN】《Adaptive Propagation Graph Convolutional Network》(TNNLS 2020)

Return and finally? Everyone, please look over here,

brpc源码解析(六)—— 基础类socket详解

剑指 Offer 22. 链表中倒数第k个节点

Brpc source code analysis (V) -- detailed explanation of basic resource pool

OSPF综合实验

GPT plus money (OpenAI CLIP,DALL-E)

Pycharm connects to the remote server SSH -u reports an error: no such file or directory

W5500 upload temperature and humidity to onenet platform

JVM performance tuning methods
随机推荐
Similarity matrix, diagonalization condition
The applet image cannot display Base64 pictures. The solution is valid
微星主板前面板耳机插孔无声音输出问题【已解决】
【云驻共创】AI在数学界有哪些作用?未来对数学界会有哪些颠覆性影响?
【高并发】高并发场景下一种比读写锁更快的锁,看完我彻底折服了!!(建议收藏)
Classification parameter stack of JS common built-in object data types
Onenet platform control w5500 development board LED light
JS interview question: handwriting throttle function
【GCN多模态RS】《Pre-training Representations of Multi-modal Multi-query E-commerce Search》 KDD 2022
How to solve the problem that "w5500 chip cannot connect to the server immediately after power failure and restart in tcp_client mode"
Video Caption(跨模态视频摘要/字幕生成)
任何时间,任何地点,超级侦探,认真办案!
油猴脚本链接
brpc源码解析(七)—— worker基于ParkingLot的bthread调度
Varest blueprint settings JSON
php 一台服务器传图片到另一台上 curl post file_get_contents保存图片
[cloud co creation] what is the role of AI in mathematics? What will be the disruptive impact on the mathematical world in the future?
brpc源码解析(一)—— rpc服务添加以及服务器启动主要过程
winddows 计划任务执行bat 执行PHP文件 失败的解决办法
擎创科技加入龙蜥社区,共建智能运维平台新生态