当前位置:网站首页>CPM:A large-scale generative chinese pre-trained lanuage model
CPM:A large-scale generative chinese pre-trained lanuage model
2022-07-30 22:51:00 【Kun Li】
GitHub - yangjianxin1/CPM: Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成)Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成) - GitHub - yangjianxin1/CPM: Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成) https://github.com/yangjianxin1/CPM论文《CPM: A Large-scale Generative Chinese Pre-trained Language Model》_陈欢伯的博客-CSDN博客1. IntroductionGPT-3含有175B参数使用了570GB的数据进行训练。但大多数语料是基于英文(93%),并且GPT-3的参数没有分布,所以提出了CPM(Chinese Pretrained language Model):包含2.6B参数,使用100GB中文训练数据。CPM可以对接下游任务:对话、文章生成、完形填空、语言理解。随着参数规模的增加,CPM在一些数据集上表现更好,表示大模型在语言生成和理解上面更有效。文章的主要贡献发布了一个CPM:2.6B参数,100GB中文训练
https://github.com/yangjianxin1/CPM论文《CPM: A Large-scale Generative Chinese Pre-trained Language Model》_陈欢伯的博客-CSDN博客1. IntroductionGPT-3含有175B参数使用了570GB的数据进行训练。但大多数语料是基于英文(93%),并且GPT-3的参数没有分布,所以提出了CPM(Chinese Pretrained language Model):包含2.6B参数,使用100GB中文训练数据。CPM可以对接下游任务:对话、文章生成、完形填空、语言理解。随着参数规模的增加,CPM在一些数据集上表现更好,表示大模型在语言生成和理解上面更有效。文章的主要贡献发布了一个CPM:2.6B参数,100GB中文训练https://blog.csdn.net/mark_technology/article/details/118680728文章本身写的非常简单,至于模型结构这块,可以看一下放出来的代码,还挺好用的,我跑一个电商场景的推荐文章生成模型,效果也不错。在生成模型上还是很建议尝试一下CPM,整体采用transformer中的代码实现,比较简洁。

上面计算时间为使用单块NVIDIA V100 GPU训练的估计时间。
1.Approach
1.1 Chinese PLM(pretrained lanuage model)
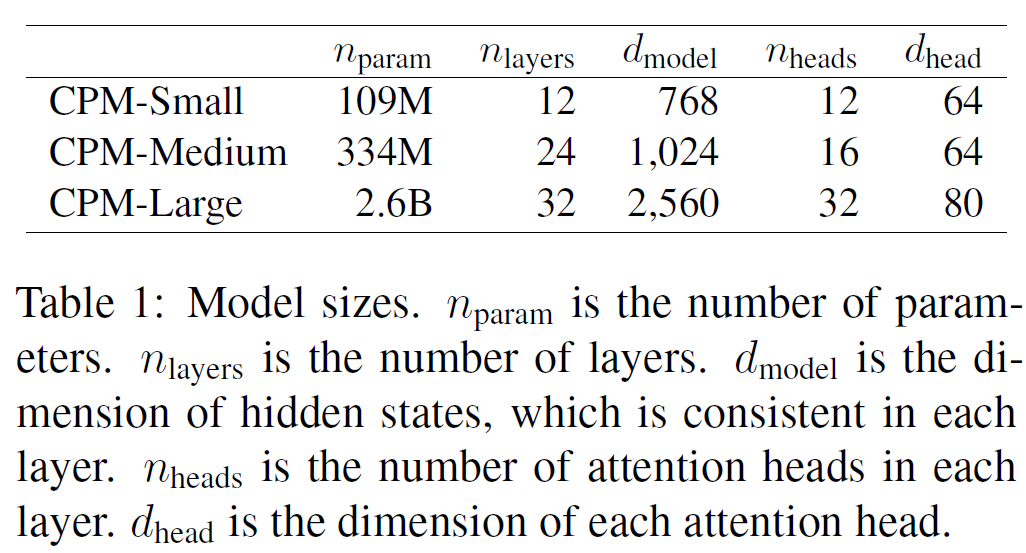
上面是CPM的模型参数版本,其中small版本至少我是可以在gtx1080ti上训练的,后面我会添加我的具体训练参数。
稍微过一下CPM的模型结构,其实就是gpt2的模型:
transformer.wte.weight [30000, 768]
transformer.wpe.weight [1024, 768]
transformer.h.0.ln_1.weight [768]
transformer.h.0.ln_1.bias [768]
transformer.h.0.attn.bias [1, 1, 1024, 1024]
transformer.h.0.attn.masked_bias []
transformer.h.0.attn.c_attn.weight [768, 2304]
transformer.h.0.attn.c_attn.bias [2304]
transformer.h.0.attn.c_proj.weight [768, 768]
transformer.h.0.attn.c_proj.bias [768]
transformer.h.0.ln_2.weight [768]
transformer.h.0.ln_2.bias [768]
transformer.h.0.mlp.c_fc.weight [768, 3072]
transformer.h.0.mlp.c_fc.bias [3072]
transformer.h.0.mlp.c_proj.weight [3072, 768]
transformer.h.0.mlp.c_proj.bias [768]
transformer.h.1.ln_1.weight [768]
transformer.h.1.ln_1.bias [768]
transformer.h.1.attn.bias [1, 1, 1024, 1024]
transformer.h.1.attn.masked_bias []
transformer.h.1.attn.c_attn.weight [768, 2304]
transformer.h.1.attn.c_attn.bias [2304]
transformer.h.1.attn.c_proj.weight [768, 768]
transformer.h.1.attn.c_proj.bias [768]
transformer.h.1.ln_2.weight [768]
transformer.h.1.ln_2.bias [768]
transformer.h.1.mlp.c_fc.weight [768, 3072]
transformer.h.1.mlp.c_fc.bias [3072]
transformer.h.1.mlp.c_proj.weight [3072, 768]
transformer.h.1.mlp.c_proj.bias [768]
transformer.h.2.ln_1.weight [768]
transformer.h.2.ln_1.bias [768]
transformer.h.2.attn.bias [1, 1, 1024, 1024]
transformer.h.2.attn.masked_bias []
transformer.h.2.attn.c_attn.weight [768, 2304]
transformer.h.2.attn.c_attn.bias [2304]
transformer.h.2.attn.c_proj.weight [768, 768]
transformer.h.2.attn.c_proj.bias [768]
transformer.h.2.ln_2.weight [768]
transformer.h.2.ln_2.bias [768]
transformer.h.2.mlp.c_fc.weight [768, 3072]
transformer.h.2.mlp.c_fc.bias [3072]
transformer.h.2.mlp.c_proj.weight [3072, 768]
transformer.h.2.mlp.c_proj.bias [768]
transformer.h.3.ln_1.weight [768]
transformer.h.3.ln_1.bias [768]
transformer.h.3.attn.bias [1, 1, 1024, 1024]
transformer.h.3.attn.masked_bias []
transformer.h.3.attn.c_attn.weight [768, 2304]
transformer.h.3.attn.c_attn.bias [2304]
transformer.h.3.attn.c_proj.weight [768, 768]
transformer.h.3.attn.c_proj.bias [768]
transformer.h.3.ln_2.weight [768]
transformer.h.3.ln_2.bias [768]
transformer.h.3.mlp.c_fc.weight [768, 3072]
transformer.h.3.mlp.c_fc.bias [3072]
transformer.h.3.mlp.c_proj.weight [3072, 768]
transformer.h.3.mlp.c_proj.bias [768]
transformer.h.4.ln_1.weight [768]
transformer.h.4.ln_1.bias [768]
transformer.h.4.attn.bias [1, 1, 1024, 1024]
transformer.h.4.attn.masked_bias []
transformer.h.4.attn.c_attn.weight [768, 2304]
transformer.h.4.attn.c_attn.bias [2304]
transformer.h.4.attn.c_proj.weight [768, 768]
transformer.h.4.attn.c_proj.bias [768]
transformer.h.4.ln_2.weight [768]
transformer.h.4.ln_2.bias [768]
transformer.h.4.mlp.c_fc.weight [768, 3072]
transformer.h.4.mlp.c_fc.bias [3072]
transformer.h.4.mlp.c_proj.weight [3072, 768]
transformer.h.4.mlp.c_proj.bias [768]
transformer.h.5.ln_1.weight [768]
transformer.h.5.ln_1.bias [768]
transformer.h.5.attn.bias [1, 1, 1024, 1024]
transformer.h.5.attn.masked_bias []
transformer.h.5.attn.c_attn.weight [768, 2304]
transformer.h.5.attn.c_attn.bias [2304]
transformer.h.5.attn.c_proj.weight [768, 768]
transformer.h.5.attn.c_proj.bias [768]
transformer.h.5.ln_2.weight [768]
transformer.h.5.ln_2.bias [768]
transformer.h.5.mlp.c_fc.weight [768, 3072]
transformer.h.5.mlp.c_fc.bias [3072]
transformer.h.5.mlp.c_proj.weight [3072, 768]
transformer.h.5.mlp.c_proj.bias [768]
transformer.h.6.ln_1.weight [768]
transformer.h.6.ln_1.bias [768]
transformer.h.6.attn.bias [1, 1, 1024, 1024]
transformer.h.6.attn.masked_bias []
transformer.h.6.attn.c_attn.weight [768, 2304]
transformer.h.6.attn.c_attn.bias [2304]
transformer.h.6.attn.c_proj.weight [768, 768]
transformer.h.6.attn.c_proj.bias [768]
transformer.h.6.ln_2.weight [768]
transformer.h.6.ln_2.bias [768]
transformer.h.6.mlp.c_fc.weight [768, 3072]
transformer.h.6.mlp.c_fc.bias [3072]
transformer.h.6.mlp.c_proj.weight [3072, 768]
transformer.h.6.mlp.c_proj.bias [768]
transformer.h.7.ln_1.weight [768]
transformer.h.7.ln_1.bias [768]
transformer.h.7.attn.bias [1, 1, 1024, 1024]
transformer.h.7.attn.masked_bias []
transformer.h.7.attn.c_attn.weight [768, 2304]
transformer.h.7.attn.c_attn.bias [2304]
transformer.h.7.attn.c_proj.weight [768, 768]
transformer.h.7.attn.c_proj.bias [768]
transformer.h.7.ln_2.weight [768]
transformer.h.7.ln_2.bias [768]
transformer.h.7.mlp.c_fc.weight [768, 3072]
transformer.h.7.mlp.c_fc.bias [3072]
transformer.h.7.mlp.c_proj.weight [3072, 768]
transformer.h.7.mlp.c_proj.bias [768]
transformer.h.8.ln_1.weight [768]
transformer.h.8.ln_1.bias [768]
transformer.h.8.attn.bias [1, 1, 1024, 1024]
transformer.h.8.attn.masked_bias []
transformer.h.8.attn.c_attn.weight [768, 2304]
transformer.h.8.attn.c_attn.bias [2304]
transformer.h.8.attn.c_proj.weight [768, 768]
transformer.h.8.attn.c_proj.bias [768]
transformer.h.8.ln_2.weight [768]
transformer.h.8.ln_2.bias [768]
transformer.h.8.mlp.c_fc.weight [768, 3072]
transformer.h.8.mlp.c_fc.bias [3072]
transformer.h.8.mlp.c_proj.weight [3072, 768]
transformer.h.8.mlp.c_proj.bias [768]
transformer.h.9.ln_1.weight [768]
transformer.h.9.ln_1.bias [768]
transformer.h.9.attn.bias [1, 1, 1024, 1024]
transformer.h.9.attn.masked_bias []
transformer.h.9.attn.c_attn.weight [768, 2304]
transformer.h.9.attn.c_attn.bias [2304]
transformer.h.9.attn.c_proj.weight [768, 768]
transformer.h.9.attn.c_proj.bias [768]
transformer.h.9.ln_2.weight [768]
transformer.h.9.ln_2.bias [768]
transformer.h.9.mlp.c_fc.weight [768, 3072]
transformer.h.9.mlp.c_fc.bias [3072]
transformer.h.9.mlp.c_proj.weight [3072, 768]
transformer.h.9.mlp.c_proj.bias [768]
transformer.h.10.ln_1.weight [768]
transformer.h.10.ln_1.bias [768]
transformer.h.10.attn.bias [1, 1, 1024, 1024]
transformer.h.10.attn.masked_bias []
transformer.h.10.attn.c_attn.weight [768, 2304]
transformer.h.10.attn.c_attn.bias [2304]
transformer.h.10.attn.c_proj.weight [768, 768]
transformer.h.10.attn.c_proj.bias [768]
transformer.h.10.ln_2.weight [768]
transformer.h.10.ln_2.bias [768]
transformer.h.10.mlp.c_fc.weight [768, 3072]
transformer.h.10.mlp.c_fc.bias [3072]
transformer.h.10.mlp.c_proj.weight [3072, 768]
transformer.h.10.mlp.c_proj.bias [768]
transformer.h.11.ln_1.weight [768]
transformer.h.11.ln_1.bias [768]
transformer.h.11.attn.bias [1, 1, 1024, 1024]
transformer.h.11.attn.masked_bias []
transformer.h.11.attn.c_attn.weight [768, 2304]
transformer.h.11.attn.c_attn.bias [2304]
transformer.h.11.attn.c_proj.weight [768, 768]
transformer.h.11.attn.c_proj.bias [768]
transformer.h.11.ln_2.weight [768]
transformer.h.11.ln_2.bias [768]
transformer.h.11.mlp.c_fc.weight [768, 3072]
transformer.h.11.mlp.c_fc.bias [3072]
transformer.h.11.mlp.c_proj.weight [3072, 768]
transformer.h.11.mlp.c_proj.bias [768]
transformer.ln_f.weight [768]
transformer.ln_f.bias [768]
lm_head.weight [30000, 768]
1.2 data processing
CPM的词汇表有3w个。丰富的中文训练数据,中文数据其实比较好搞,直接网上爬就可以,git上作为提供了一个作文预训练的模型,在这个预训练模型上finetune效果也不错,我的训练数据大概有7-8w的标题-文本对数据。

1.3 pr-training details
lr=1.5x10-4,batch_size=3072,max_len:1024(训练时,输入数据的最大长度),steps=2000(前500轮warmup),optimizer=adam,64*v100训了2周。
2x1080ti:cpm-small版本,max_len:200,lr=0.00015,batch_size:16,steps:100,adamw。
transformer=4.6.0
2.后面是cpm在一些任务上的实验。
边栏推荐
- 编码与进制
- 语言代码表
- When Navicat connects to MySQL, it pops up: 1045: Access denied for user 'root'@'localhost'
- ZZULIOJ:1119: sequence order
- The problem of sticky packets in tcp protocol transmission
- 使用LVS和Keepalived搭建高可用负载均衡服务器集群
- DFS question list and template summary
- 2022.7.30
- 2022/07/30 学习笔记 (day20) 面试题积累
- [MySQL] Related operations on databases and tables in MySQL
猜你喜欢
MySQL索引常见面试题(2022版)

VS2017 compile Tars test project

A detailed explanation: SRv6 Policy model, calculation and drainage

打动中产精英群体,全新红旗H5用产品力跑赢需求

ThinkPHP高仿蓝奏云网盘系统源码/对接易支付系统程序

StoneDB 为何敢称业界唯一开源的 MySQL 原生 HTAP 数据库?
EasyExcel综合课程实战

MySQL进阶sql性能分析

ML之shap:基于FIFA 2018 Statistics(2018年俄罗斯世界杯足球赛)球队比赛之星分类预测数据集利用RF随机森林+计算SHAP值单样本力图/依赖关系贡献图可视化实现可解释性之攻略

只会纯硬件,让我有点慌
随机推荐
ML's shap: Based on FIFA 2018 Statistics (2018 Russia World Cup) team match star classification prediction data set using RF random forest + calculating SHAP value single-sample force map/dependency c
2022.7.27
[MySQL] Related operations on databases and tables in MySQL
StoneDB 为何敢称业界唯一开源的 MySQL 原生 HTAP 数据库?
Mysql进阶优化篇01——四万字详解数据库性能分析工具(深入、全面、详细,收藏备用)
Golang go-redis cluster模式下不断创建新连接,效率下降问题解决
2sk2225代换3A/1500V中文资料【PDF数据手册】
reindex win10
ZZULIOJ:1120: 最值交换
【Untitled】
ThinkPHP高仿蓝奏云网盘系统源码/对接易支付系统程序
【云驻共创】HCSD大咖直播–就业指南
HF2022-EzPHP reproduction
2022牛客暑期多校训练营1 J Serval and Essay
2022.7.27
openim支持十万超级大群
TCP 连接 三次握手 四次挥手
【科研】文献下载神器方式汇总
Compressing Deep Graph Neural Networks via Adversarial Knowledge Distillation
2022.7.28