当前位置:网站首页>redis学习笔记
redis学习笔记
2022-06-22 19:45:00 【fate _zore】
redis
NoSql
技术发展
技术的分类
解决功能性的问题:Java、Jsp、RDBMS、Tomcat、HTML、Linux、JDBC、SVN
解决扩展性的问题:Struts、Spring、SpringMVC、Hibernate、Mybatis
解决性能的问题:NoSQL、Java线程、Hadoop、Nginx、MQ、ElasticSearch
redis简述与安装
- Redis是一个开源的key-value存储系统。
- 和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
- 这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
- 在此基础上,Redis支持各种不同方式的排序。
- 与memcached一样,为了保证效率,数据都是缓存在内存中。
- 区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
- 并且在此基础上实现了master-slave(主从)同步。
应用场景
配合关系型数据库做高速缓存
- 高频次,热门访问的数据,降低数据库IO
- 分布式架构,做session共享
多样的数据结构存储持久化数据

安装
常用五大数据类型
键(key)操作
keys *查看当前库所有key (匹配:keys *1)
exists key判断某个key是否存在
type key 查看你的key是什么类型
del key 删除指定的key数据
unlink key 根据value选择非阻塞删除
仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
expire key 10 10秒钟:为给定的key设置过期时间
ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
select命令切换数据库
dbsize查看当前数据库的key的数量
flushdb清空当前库
flushall通杀全部库
Redis字符串(String)
简介
- string是redis最基本的类型,与mencached基本一样的类型,一个key对应一个value
- string是二进制安全的,redis的string可以包含任何数据,比如图片或序列化的对象
- string的value最大可以达到512M
常用命令:
set key value添加键值对
get <key>查询对应键值
append <key><value>将给定的 追加到原值的末尾
strlen <key>获得值的长度
setnx <key><value>只有在 key 不存在时 设置 key 的值
incr <key>将 key 中储存的数字值增1,只能对数字值操作,如果为空,新增值为1
decr <key>将 key 中储存的数字值减1只能对数字值操作,如果为空,新增值为-1
incrby / decrby <key><步长>将 key 中储存的数字值增减。自定义步长。
mset <key1><value1><key2><value2>.....同时设置一个或多个 key-value对
mget <key1><key2><key3> .....同时获取一个或多个 value
msetnx <key1><value1><key2><value2> .....同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
getrange <key><起始位置><结束位置>获得值的范围,类似java中的substring,前包,后包
setrange <key><起始位置><value>用 覆写所储存的字符串值,从<起始位置>开始(索引从0****开始)。
setex <key><过期时间><value>设置键值的同时,设置过期时间,单位秒。
getset <key><value>以新换旧,设置了新值同时获得旧值。
数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
Redis列表(List)
简介
单键多值
- Redis 列表是简单的字符串列表,按照插入顺序排序。
- 你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
- 它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

常用命令:
lpush/rpush <key><value1><value2><value3> ....从左边/右边插入一个或多个值。
lpop/rpop <key>从左边/右边吐出一个值。值在键在,值光键亡。
rpoplpush <key1><key2>从列表右边吐出一个值,插到列表左边。
lrange <key><start><stop>按照索引下标获得元素(从左到右)
lrange mylist 0 -10左边第一个,-1右边第一个,(0-1表示获取所有)
linsert <key> before <value><newvalue>在的后面插入插入值
lrem <key><n><value>从左边删除n个value(从左到右)
lset<key><index><value>将列表key下标为index的值替换成value
数据结构:
List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
Redis集合(Set)
简介:
- Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
- Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
- 一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变
常用命令:
sadd <key><value1><value2> .....->将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
smembers <key>->取出该集合的所有值。
sismember <key><value>->判断集合是否为含有该值,有1,没有0
scard<key>->返回该集合的元素个数。
srem <key><value1><value2> ....->删除集合中的某个元素。
spop <key>->随机从该集合中吐出一个值。
srandmember <key><n>->随机从该集合中取出n个值。不会从集合中删除 。
smove <source><destination>value->把集合中一个值从一个集合移动到另一个集合
sinter <key1><key2>->返回两个集合的交集元素。
sunion <key1><key2>->返回两个集合的并集元素。
sdiff <key1><key2>->返回两个集合的差集元素(key1中的,不包含key2中的)
数据结构:
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
Redis哈希(Hash)
简介:
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储
主要有以下2种存储方式:
常用命令:
hset <key><field><value>->给集合中的 键赋值
hget <key1><field>->从集合取出 value
hmset <key1><field1><value1><field2><value2>...->批量设置hash的值
hexists<key1><field>->查看哈希表 key 中,给定域 field 是否存在。
hkeys <key>->列出该hash集合的所有field
hvals <key>->列出该hash集合的所有value
hincrby <key><field><increment>->为哈希表 key 中的域 field 的值加上增量 1 -1
hsetnx <key><field><value>将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .
数据结构:
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
Redis有序集合Zset
简介:
- Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
- 不同之处是有序集合的每个成员都关联了一个评分(****score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
- 因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
- 访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
常用命令:
zadd <key><score1><value1><score2><value2>…将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zrange <key><start><stop> [WITHSCORES]返回有序集 key 中,下标在
之间的元素 带WITHSCORES,可以让分数一起和值返回到结果集。
zrangebyscore key minmax [withscores] [limit offset count]返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key maxmin [withscores] [limit offset count]同上,改为从大到小排列。
zincrby <key><increment><value>为元素的score加上增量
zrem <key><value>删除该集合下,指定值的元素
zcount <key><min><max>统计该集合,分数区间内的元素个数
zrank <key><value>返回该值在集合中的排名,从0开始。
数据结构:
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
Redis压缩表、跳跃表?拿来吧你 - 掘金 (juejin.cn)
配置文件
units单位
配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit
大小写不敏感

INCLUDES
类似jsp中的include,多实例的情况可以把公用的配置文件提取出来

网络相关配置
bind
- 默认情况bind=127.0.0.1只能接受本机的访问请求
- 不写的情况下,无限制接受任何ip地址的访问
- 生产环境肯定要写你应用服务器的地址;服务器是需要远程访问的,所以需要将其注释掉
- 如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应

protected-mode
本机访问保护模式

port
端口号,默认6379

tcp-backlog
- 设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列。
- 在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。
- 注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果

timeout
一个空闲的客户端维持多少秒会关闭,0表示关闭该功能。即永不关闭。

tcp-keepalive
- 对访问客户端的一种心跳检测,每个n秒检测一次。
- 单位为秒,如果设置为0,则不会进行Keepalive检测,建议设置成60

GENERAL通用
daemonize
是否开启后台进程,默认关闭

pidfile
存放pid文件的位置,每个实例会产生一个不同的pid文件
loglevel
设置日志的级别

logfile
日志的输出文件地址

databases
设定库的数量 默认16,默认操作的数据库为0号,可以使用SELECT 命令在连接上指定数据库id

SECURITY
设置密码
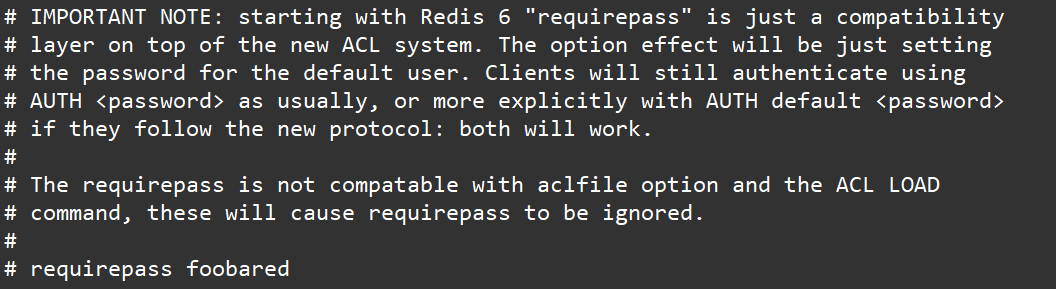
访问密码的查看、设置和取消
在命令中设置密码,只是临时的。重启redis服务器,密码就还原了。
永久设置,需要再配置文件中进行设置。
LIMITS限制
发布与订阅
什么是发布和订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
Redis的发布和订阅
客户端可以订阅频道如下图

当给这个频道发布消息后,消息就会发送给订阅的客户端

发布订阅命令行实现
- 打开一个客户端订阅channel1

- 命令:
SUBSCRIBE channel1 - 打开另一个客户端,给channel1发布消息

- 命令:
publish channel1 hello 
新数据类型
Bitmaps
简介
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如下图

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis提供了Bitmaps这个“数据类型”可以实现对位的操作:
- Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作。
- Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

命令
setbit<key><offset><value>设置Bitmaps中某个偏移量的值(0或1)
实例:
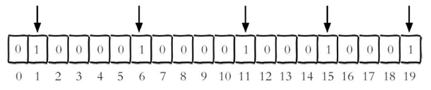
每个独立用户是否访问过网站存放在Bitmaps中, 将访问的用户记做1, 没有访问的用户记做0, 用偏移量作为用户的id。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1, 6, 11, 15, 19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图

注意:
设置Bitmaps中某个偏移量的值(0或1)注意:很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
getbit<key><offset>获取Bitmaps中某个偏移量的值
实例:
获取id=8的用户是否在2020-11-06这天访问过, 返回0说明没有访问过:

bitcount<key>[start end]统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。
bitop and(or/not/xor) <destkey> [key…]bitop是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中。
实例
2020-11-04 日访问网站的userid=1,2,5,9。
setbit unique:users:20201104 1 1
setbit unique:users:20201104 2 1
setbit unique:users:20201104 5 1
setbit unique:users:20201104 9 1
2020-11-03 日访问网站的userid=0,1,4,9。
setbit unique:users:20201103 0 1
setbit unique:users:20201103 1 1
setbit unique:users:20201103 4 1
setbit unique:users:20201103 9 1
计算出两天都访问过网站的用户数量
bitop and unique:users:and:20201104_03
unique:users:20201103unique:users:20201104

Bitmaps与set对比
假设网站有1亿用户, 每天独立访问的用户有5千万, 如果每天用集合类型和Bitmaps分别存储活跃用户可以得到表
| set和Bitmaps存储一天活跃用户对比 | |||
|---|---|---|---|
| 数据 类型 | 每个用户id占用空间 | 需要存储的用户量 | 全部内存量 |
| 集合 类型 | 64位 | 50000000 | 64位*50000000 = 400MB |
| Bitmaps | 1位 | 100000000 | 1位*100000000 = 12.5MB |
很明显, 这种情况下使用Bitmaps能节省很多的内存空间, 尤其是随着时间推移节省的内存还是非常可观的
| set和Bitmaps存储独立用户空间对比 | |||
|---|---|---|---|
| 数据类型 | 一天 | 一个月 | 一年 |
| 集合类型 | 400MB | 12GB | 144GB |
| Bitmaps | 12.5MB | 375MB | 4.5GB |
但Bitmaps并不是万金油, 假如该网站每天的独立访问用户很少, 例如只有10万(大量的僵尸用户) , 那么两者的对比如下表所示, 很显然, 这时候使用Bitmaps就不太合适了, 因为基本上大部分位都是0
HyperLogLog
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
(1)数据存储在MySQL表中,使用distinct count计算不重复个数
(2)使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
能否能够降低一定的精度来平衡存储空间?Redis推出了HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
命令
pfadd
pfadd <key>< element> [element ...]
添加指定元素到 HyperLogLog 中

将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0。
pfcount
pfcount<key> [key ...]
计算HLL的近似基数,可以计算多个HLL,比如用HLL存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可

pfmerge
pfmerge<destkey><sourcekey> [sourcekey ...]
将一个或多个HLL合并后的结果存储在另一个HLL中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得

Geospatial
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
命令
geoadd
geoadd<key>< longitude><latitude><member> [longitude latitude member...]
添加地理位置(经度,纬度,名称)
实例

注意:两极无法直接添加,一般会下载城市数据,直接通过 Java 程序一次性导入。
有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878 度到 85.05112878 度。
当坐标位置超出指定范围时,该命令将会返回一个错误。
已经添加的数据,是无法再次往里面添加的。
geopos
geopos <key><member> [member...]
获得指定地区的坐标值

geodist
geodist<key><member1><member2> [m|km|ft|mi ]
获取两个位置之间的直线距离
实例

单位:
- m 表示单位为米[默认值]。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
如果用户没有显式地指定单位参数, 那么 GEODIST 默认使用米作为单位
georadius
georadius<key>< longitude><latitude>radius m|km|ft|mi
以给定的经纬度为中心,找出某一半径内的元素

Jedis操作Redis6
测试
依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
连接测试(错误示范)
public static void main(String[] args) {
//创建jedis对象
Jedis jedis = new Jedis("192.168.150.111",6379);
//测试是否能链接到
String ping = jedis.ping();
System.out.println(ping);
}

解决方法
禁用Linux的防火墙:Linux(CentOS7)里执行命令
systemctl stop firewalld.service
redis.conf中注释掉bind 127.0.0.1 ,然后 protected-mode no
正确结果

数据类型测试
@Test
public void string(){
//批量添加
jedis.mset("k1","v1","k2","v2","k3","v3");
//批量查询(返回list)
jedis.mget("k1","k2","k3").forEach(System.out::println);
}
@Test
public void list(){
jedis.lpush("lk","lv1","lv2","lv3");
List<String> lk = jedis.lrange("lk", 0, -1);
System.out.println(lk);
}
@Test
public void set(){
jedis.sadd("sk1","sv1","sv1","sv2","sv3","sv4","sv5");
Set<String> sk1 = jedis.smembers("sk1");
System.out.println(sk1);
}
@Test
public void hash(){
jedis.hset("user","age","20");
String hget = jedis.hget("user", "age");
System.out.println(hget);
}
@Test
public void zSet(){
jedis.zadd("zk1", 100d,"zv1");
jedis.zadd("zk1", 200d,"zv2");
jedis.zadd("zk1", 50d,"zv3");
Set<String> zk1 = jedis.zrange("zk1", 0, -1);
System.out.println(zk1);
}
}
模拟手机验证码
思路
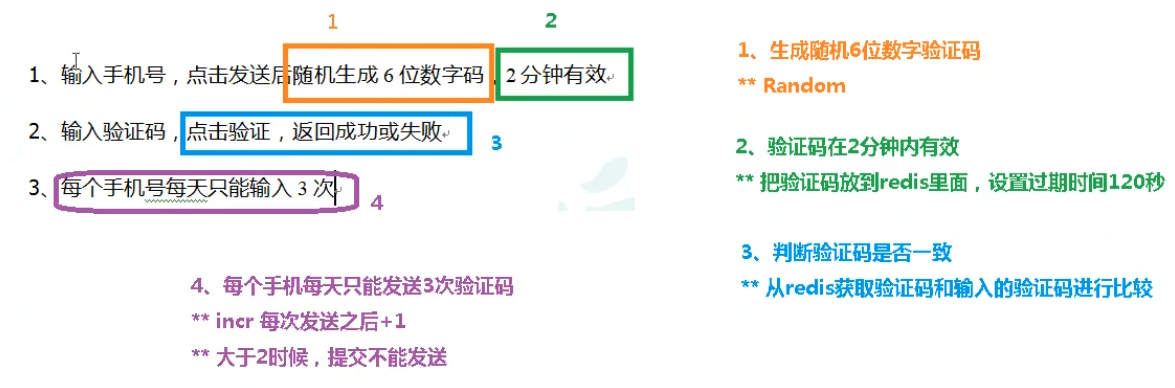
package com.fate.jedis;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import java.util.Random;
/** * @author m */
public class CodeController {
Jedis jedis = new Jedis("192.168.150.111",6379);
public Boolean isCode(String code,String id) {
String rightCode = jedis.get(id + "_code");
return rightCode.equals(code);
}
public String getCode() {
Random random = new Random();
StringBuilder code = new StringBuilder();
for (int i = 0; i < 6; i++) {
int r= random.nextInt(10);
code.append(r);
}
return code.toString();
}
public String setCode(String id) {
String code = getCode();
jedis.incrBy(id,1);
String count = jedis.get(id);
if (count == null) {
jedis.setex(id,24*60*60,"1");
}else if (Integer.parseInt(count)<3){
jedis.incrBy(id,1);
jedis.setex(id+ "_code",120*2 ,code);
return code;
}else {
System.out.println("次数上限");
}
return code;
}
@Test
public void t(){
String code = setCode("18848312652");
Boolean aBoolean = isCode(code, "18848312652");
System.out.println(aBoolean);
}
}
Redis6与Spring Boot整合
引入依赖
<!-- redis整合-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.0</version>
</dependency>
配置文件
#Redis服务器地址
spring.redis.host=192.168.150.111
#Redis服务器连接端口
spring.redis.port=6379
#Redis数据库索引(默认为0)
spring.redis.database= 0
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
配置类
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
/** * @author m */
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
@SuppressWarnings({
"rawtypes", "unchecked" })
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory){
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
//Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
//String序列号配置
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//key和hash的key都采用String的序列化配置
template.setKeySerializer(stringRedisSerializer);
template.setHashKeySerializer(stringRedisSerializer);
//value和hash的value采用Json的序列化配置
template.setValueSerializer(jackson2JsonRedisSerializer);
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
测试
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/** * @author m */
@RestController
@RequestMapping("/redisTest")
public class RedisTestController {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@GetMapping()
public String test(){
redisTemplate.opsForValue().set("name","lucy");
return (String) redisTemplate.opsForValue().get("name");
}
}
RedisTemplate
所有方法
// 配置默认序列化与反序列化工具类
1.afterPropertiesSet
// 根据参数执行相关operation操作,例如,事务
2.execute
// 执行pipelining流水线相关操作
3.executePipelined
// 执行指定connection连接的相关操作
4.executeWithStickyConnection
// 执行session内的execute方法
5.executeSession
// 创建RedisConnection代理类
6.createRedisConnectionProxy
// connection连接的预处理
7.preProcessConnection
// 结果的后处理,默认什么都不做
8.postProcessResult
// 是否向RedisCallback暴露本地连接
9.isExposeConnection
// 设置是否向RedisCallback暴露本地连接
10.setExposeConnection
// 12到26都是设置和获取相关序列化工具类
11.isEnableDefaultSerializer
12.setEnableDefaultSerializer
13.getDefaultSerializer
14.setDefaultSerializer
15.setKeySerializer
16.getKeySerializer
17.setValueSerializer
18.getValueSerializer
19.getHashKeySerializer
20.setHashKeySerializer
21.getHashValueSerializer
22.setHashValueSerializer
23.getStringSerializer
24.setStringSerializer
25.setScriptExecutor
// 27到34为私有方法,不对外提供使用
26.rawKey
27.rawString
28.rawValue
29.rawKeys
30.deserializeKey
31.deserializeMixedResults
32.deserializeSet
33.convertTupleValues
// 执行事务
34.exec
35.execRaw
// 删除操作
36.delete
// 接触链接
37.unlink
// 查看是否含有指定key
38.hasKey
39.countExistingKeys
// 设置过期时间
40.expire
41.expireAt
// 转换成字节流并向channel发送message
42.convertAndSend
// 获取过期时间
43.getExpire
// 根据传入的正则表达式返回所有的key
44.keys
// 取消指定key的过期时间
45.persist
// 移动指定的key和index到数据库中
46.move
// 从键空间随机获取一个key
47.randomKey
// 将指定key改成目标key
48.rename
// key不存在时,将指定key改成目标key
49.renameIfAbsent
// 设置存储在指定key的类型
50.type
// 检索存储在key的值的序列化版本
51.dump
// 执行Redis的restore的命令
52.restore
// 标记事务阻塞的开始
53.multi
// 丢弃所有在multi之后发出的命令
54.discard
// 观察指定key在事务处理开始即multi之后的修改情况
55.watch
// 刷新先前观察的所有key
56.unwatch
// 为key元素排序
57.sort
// 关闭客户端连接
58.killClient
// 请求连接客户端的相关信息和统计数据
59.getClientList
// 更改复制配置到新的master
60.slaveOf
// 将本机更改为master
61.slaveOfNoOne
// 64到79都是获取相对应的操作
62.opsForCluster
63.opsForGeo
64.boundGeoOps
65.boundHashOps
66.opsForHash
67.opsForHyperLogLog
68.opsForList
69.boundListOps
70.boundSetOps
71.opsForSet
72.opsForStream
73.boundStreamOps
74.boundValueOps
75.opsForValue
76.boundZSetOps
77.opsForZSet
// 设置是否支持事务
78.setEnableTransactionSupport
// 设置bean的类加载器
79.setBeanClassLoader
spring-data-redis 提供了如下功能:
连接池自动管理,提供了一个高度封装的“RedisTemplate”类
进行了归类封装,将同一类型操作封装为operation接口
ValueOperations:简单K-V操作
SetOperations:set类型数据操作
ZSetOperations:zset类型数据操作
HashOperations:针对map类型的数据操作
ListOperations:针对list类型的数据操作提供了对 key 的“bound”(绑定)便捷化操作API,可以通过bound封装指定的key,然后进行一系列的操作而无须“显式”的再次指定Key,即 BoundKeyOperations
BoundValueOperations
BoundSetOperations
BoundListOperations
BoundSetOperations
BoundHashOperations将事务操作封装,有容器控制。
针对数据的“序列化/反序列化”,提供了多种可选择策略(RedisSerializer)
- JdkSerializationRedisSerializer:POJO对象的存取场景,使用JDK本身序列化机制,将pojo类通过ObjectInputStream/ObjectOutputStream进行序列化操作,最终redis-server中将存储字节序列。是目前最常用的序列化策略。
- StringRedisSerializer:Key或者value为字符串的场景,根据指定的charset对数据的字节序列编码成string是“newString(bytes,charset)”和“string.getBytes(charset)”的直接封装。是最轻量级和高效的策略。
- JacksonJsonRedisSerializer:jackson-json工具提供了javabean与json之间的转换能力,可以将pojo实例序列化成json格式存储在redis中,也可以将json格式的数据转换成pojo实例。因为jackson工具在序列化和反序列化时,需要明确指定Class类型,因此此策略封装起来稍微复杂。
- OxmSerializer:提供了将javabean与xml之间的转换能力,目前可用的三方支持包括jaxb,apache-xmlbeans;redis存储的数据将是xml工具。不过使用此策略,编程将会有些难度,而且效率最低;不建议使用。【需要spring-oxm模块的支持】
如果你的数据需要被第三方工具解析,那么数据应该使用StringRedisSerializer而不是 JdkSerializationRedisSerializer。
RedisTemplate 顶层方法
- 确定给定 key 是否存在,有的话就返回 true,没有就返回 false
redisTemplate.hasKey(K key)
- 删除给定的 key
redisTemplate.delete(K key)
- 删除给定 key 的集合
redisTemplate.delete(Collection<K> keys)
- 执行 Redis 转储命令并返回结果,把key值序列化成byte[]类型
redisTemplate.dump(K key)
- 对传入的key值设置过期时间、将给定 key 的过期时间设置为日期时间戳
redisTemplate.expire(K key, long timeout, TimeUnit unit)
redisTemplate.expireAt(K key, Date date)
- 查找与给定模式匹配的所有 key ,返回的是一个没有重复的Set类型
redisTemplate.keys(K pattern)
- 将 oldKey 重命名为 newKey。
redisTemplate.rename(K oldKey, K newKey)
- 获取key值的类型
redisTemplate. type(K key)
- 仅当 newKey 不存在时,才将密钥 oldKey 重命名为 newKey。
redisTemplate.renameIfAbsent(K oldKey, K newKey)
- 随机从redis中获取一个key
redisTemplate.randomKey()
- 获取当前key的剩下的过期时间
redisTemplate.getExpire(K key)
- 获取剩余的过期时间,同时设置时间单位
redisTemplate. getExpire(K key, TimeUnit timeUnit)
- 删除 key 的过期时间
redisTemplate. persist(K key)
- 将给定的 key 移动到带有索引的数据库
redisTemplate. move(K key, int dbIndex)
RedisTemplate.opsForValue() 方法
设置key跟value的值
redisTemplate.opsForValue().set(K key, V value)获取 key 的值
redisTemplate.opsForValue().get(Object key)设置key跟value的值,同时设置过期时间
redisTemplate.opsForValue().set(K key, V value, Duration timeout)在 start 和 end 之间获取键值的子字符串
redisTemplate.opsForValue().get(K key, long start, long end)设置 key 的值并返回其旧值
redisTemplate.opsForValue().getAndSet(K key, V value)获取多个 key
redisTemplate.opsForValue().multiGet(Collection<K> keys)获取原来的key的值后在后面新增上新的字符串
redisTemplate.opsForValue().append(K key, String value)增量方式增加double值
redisTemplate.opsForValue().increment(K key, double increment)通过increment(K key, long delta)方法以增量方式存储long值(正值则自增,负值则自减)
redisTemplate.opsForValue().increment(K key, long increment)仅当提供的 key 不存在时,才使用集合中提供的键值对将多个 key 设置为多个值。
redisTemplate.opsForValue().multiSetIfAbsent(Map<? extends K,? extends V> map)使用集合中提供的键值对将多个 key 设置为多个值
Map map = new HashMap(); map.put("1","1"); map.put("2","2"); map.put("3","3"); redisTemplate.opsForValue().multiSet(Map<? extends K,? extends V> map)获取指定key的字符串的长度
redisTemplate.opsForValue().size(K key)用给定值覆盖从指定偏移量开始的 key 的部分
redisTemplate.opsForValue().set(K key, V value, long offset)如果 key 不存在,则设置 key 以保存字符串值,存在返回false,否则返回true
redisTemplate.opsForValue().setIfAbsent(key, value)重新设置key的值并加入过期时间
redisTemplate.opsForValue().set(key, value, timeout, unit)将二进制第offset位值变为value
redisTemplate.opsForValue().setBit(K key, long offset, boolean value)对key所储存的字符串值,获取指定偏移量上的位(bit)
redisTemplate.opsForValue().getBit(K key, long offset)
RedisTemplate.opsForHash() 方法
- 从 key 处的 hash 中获取给定 hashKey 的值,即 key field(hashKey) value
redisTemplate.opsForHash().get(H key, Object hashKey)
- 获取存储在 key 的整个 hash,即获取所有值
redisTemplate.opsForHash().entries(H key)
- 设置hash hashKey 的值
redisTemplate.opsForHash().put(H key, HK hashKey, HV value)
- 使用 m 中提供的数据将多个 hash 字段设置为多个值,即使用 map 进行赋值
redisTemplate.opsForHash().putAll(H key, Map<? extends HK,? extends HV> m)
- 仅当 hashKey 不存在时才设置 hash hashKey 的值。
redisTemplate.opsForHash().putIfAbsent(H key, HK hashKey, HV value)
- 删除给定的hash hashKeys
redisTemplate.opsForHash().delete(H key, Object... hashKeys)
- 确定给定的hash hashKey 是否存在
redisTemplate.opsForHash().hasKey(H key, Object hashKey)
- 通过给定的增量增加hash hashKey 的值
redisTemplate.opsForHash().increment(H key, HK hashKey, double increment)
redisTemplate.opsForHash().increment(H key, HK hashKey, long increment)
- 在 key 处获取 hash 的 hashKey 集(字段)
redisTemplate.opsForHash().keys(H key)
- 获取 key 的 hash 大小。
redisTemplate.opsForHash().size(H key)
- 在 key 处获取 hash 的值
redisTemplate.opsForHash().values(H key)
- 查看匹配的键值对
redisTemplate.opsForHash().scan(H key, ScanOptions options)
RedisTemplate.opsForList() 方法
- 从 key 的 list 中获取索引处的元素
redisTemplate.opsForList().index(K key, long index)
- 从 key 的 list 中获取 start 和 end 之间的元素
redisTemplate.opsForList().range(K key, long start, long end)
- 为 key 添加值
redisTemplate.opsForList().leftPush(K key, V value)
- 将值添加到 key 中
redisTemplate.opsForList().leftPushAll(K key, Collection<V> values)
- 仅当 list 存在时,才将值添加到 key 中
redisTemplate.opsForList().leftPushIfPresent(K key, V value)
- 在 pivot 之前将值添加到 key 中
redisTemplate.opsForList().leftPush(K key, V pivot, V value)
- 将值附加到 key
redisTemplate.opsForList().rightPush(K key, V value)
redisTemplate.opsForList().rightPushAll(K key, Collection<V> values)
- 在 pivot 之后将值添加到 key 中
redisTemplate.opsForList().rightPush(K key, V pivot, V value)
- 在列表元素的索引处设置值
redisTemplate.opsForList().set(K key, long index, V value)
- 删除并返回存储在 key 的列表中的第一个元素、
redisTemplate.opsForList().leftPop(K key)
redisTemplate.opsForList().leftPop(K key, Duration timeout)
redisTemplate.opsForList().leftPop(K key, long count)
redisTemplate.opsForList().leftPop(K key, long timeout, TimeUnit unit)
- 删除并返回存储在 key 的列表中的最后一个元素
redisTemplate.opsForList().rightPop(K key)
redisTemplate.opsForList().rightPop(K key, Duration timeout)
redisTemplate.opsForList().rightPop(K key, long count)
redisTemplate.opsForList().rightPop(K key, long timeout, TimeUnit unit)
- 从 sourceKey 的列表中删除最后一个元素,将其附加到 destinationKey 并返回其值
redisTemplate.opsForList().rightPopAndLeftPush(K sourceKey, K destinationKey)
redisTemplate.opsForList().rightPopAndLeftPush(K sourceKey, K destinationKey, Duration timeout)
- 从存储在 key 的列表中删除第一个 count 出现的 value
redisTemplate.opsForList().remove(K key, long count, Object value)
- 在 start 和 end 之间的元素的 key 处修剪列表
redisTemplate.opsForList().trim(K key, long start, long end)
- 获取存储在 key 的列表的大小
redisTemplate.opsForList().size(K key)
RedisTemplate.opsForSet() 方法
- 在 key 的 set 中添加给定值
redisTemplate.opsForSet().add(K key, V... values)
- 在 key 的 set 中删除给定值并返回已删除元素的数量
redisTemplate.opsForSet().remove(K key, Object... values)
- 从 key 的 set 中移除并返回一个随机成员
redisTemplate.opsForSet(). pop(K key)
- 在 key 处获取集合的大小
redisTemplate.opsForSet().size(K key)
- 检查在 key 的 set 中是否包含值
redisTemplate.opsForSet().isMember(K key, Object o)
- 返回在 key 和 otherKeys 处与所有给定 sets 相交的成员
redisTemplate.opsForSet().intersect(K key, Collection<K> otherKeys)
- 在 key 和 otherKeys 处与所有给定 sets 相交,并将结果存储在 destKey 中
redisTemplate.opsForSet().intersectAndStore(K key, Collection<K> otherKeys, K destKey)
- 在 key 和 otherKey 处相交所有给定的 sets,并将结果存储在 destKey 中
redisTemplate.opsForSet().intersectAndStore(K key, K otherKey, K destKey)
- 合并给定 key 和 otherKey 的所有 sets
redisTemplate.opsForSet().union(K key, K otherKey)
- 将给定 key 和 otherKey 处的所有 set 合并,并将结果存储在 destKey 中
redisTemplate.opsForSet().unionAndStore(K key, K otherKey, K destKey)
- 获取差集
redisTemplate.opsForSet().difference(key, otherKeys)
- 获取差集并存储到destKey
redisTemplate.opsForSet().differenceAndStore(key, otherKey, destKey)
- 随机获取集合中的一个元素
redisTemplate.opsForSet().randomMember(key)
- 获取集合中的所有元素
redisTemplate.opsForSet().members(key)
1
- 随机获取集合中count个值
redisTemplate.opsForSet().randomMembers(key, count)
- 随机获取集合中count个值,但是去重
redisTemplate.opsForSet().distinctRandomMembers(key, count)
- 遍历set
redisTemplate.opsForSet().scan(key, options)
RedisTemplate.opsForZSet() 方法
- 添加元素,从小到大排序
redisTemplate.opsForZSet().add(key, value, score)
- 删除多个values的值
redisTemplate.opsForZSet().remove(key, values)
- 增加元素的score值同时返回增加后的值
redisTemplate.opsForZSet().incrementScore(key, value, delta)
- 返回元素在集合的从小到大排名
redisTemplate.opsForZSet().rank(key, value)
- 返回元素在集合的由大到小排名
redisTemplate.opsForZSet().reverseRank(key, value)
- 获取集合中指定区间的元素
redisTemplate.opsForZSet().reverseRangeWithScores(key, start,end)
- 查询集合中的元素并从小到大排序
redisTemplate.opsForZSet().reverseRangeByScore(key, min, max)
redisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, min, max)
- 从高到低的排序,然后获取最小与最大值之间的值
redisTemplate.opsForZSet().reverseRangeByScore(key, min, max, start, end)
- 根据score值获取元素数量
redisTemplate.opsForZSet().incrementScore(key, value, delta)
- 获取集合的大小
redisTemplate.opsForZSet().size(key)redisTemplate.opsForZSet().zCard(key)
- 获取集合中key、value元素的score值
redisTemplate.opsForZSet().score(key, value)
- 移除指定索引元素
redisTemplate.opsForZSet().removeRange(key, start, end)
- 移除指定score范围的集合成员
redisTemplate.opsForZSet().removeRangeByScore(key, min, max)
- 获取key和otherKey的并集并存储在destKey中
redisTemplate.opsForZSet().unionAndStore(key, otherKey, destKey)
- 获取key和otherKey的交集并存储在destKey中
redisTemplate.opsForZSet().intersectAndStore(key, otherKey, destKey)
Redis6的事务操作
Redis的事务定义

Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Redis事务的主要作用就是串联多个命令防止别的命令插队。
Multi、Exec、discard
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。
组队的过程中可以通过discard来放弃组队。

事务的错误处理
- 组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消

- 如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。

事务冲突
例子
一个请求想给金额减8000
一个请求想给金额减5000
一个请求想给金额减1000

两种锁的思想

悲观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
WATCHkey [key …]
在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个) key ,如果在事务执行之前这个(或这些) key被其他命令所改动,那么事务将被打断。
unwatch
取消 WATCH 命令对所有 key 的监视。
如果在执行 WATCH 命令之后,EXEC 命令或DISCARD 命令先被执行了的话,那么就不需要再执行UNWATCH 了。
Redis事务三特性
Ø 单独的隔离操作
- 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Ø 没有隔离级别的概念
- 队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
Ø 不保证原子性
- 事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
秒杀案例
思路

- 传入uid和prodid(并验证)
- 根据uid和prodid生成key
- 库存判断(null未开始,0结束),重复秒杀判断
- 用户秒杀,库存–
- 用户进入到秒杀成功清单
代码:
public static boolean doSecKill(String uid,String prodid) throws IOException {
//1 uid和prodid非空判断
if(uid == null || prodid == null) {
return false;
}
//2 连接redis
//Jedis jedis = new Jedis("192.168.44.168",6379);
//通过连接池得到jedis对象
JedisPool jedisPoolInstance = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = jedisPoolInstance.getResource();
//3 拼接key
// 3.1 库存key
String kcKey = "sk:"+prodid+":qt";
// 3.2 秒杀成功用户key
String userKey = "sk:"+prodid+":user";
//监视库存
jedis.watch(kcKey);
//4 获取库存,如果库存null,秒杀还没有开始
String kc = jedis.get(kcKey);
if(kc == null) {
System.out.println("秒杀还没有开始,请等待");
jedis.close();
return false;
}
// 5 判断用户是否重复秒杀操作
if(jedis.sismember(userKey, uid)) {
System.out.println("已经秒杀成功了,不能重复秒杀");
jedis.close();
return false;
}
//6 判断如果商品数量,库存数量小于1,秒杀结束
if(Integer.parseInt(kc)<=0) {
System.out.println("秒杀已经结束了");
jedis.close();
return false;
}
//7 秒杀过程
//使用事务
Transaction multi = jedis.multi();
//组队操作
multi.decr(kcKey);
multi.sadd(userKey,uid);
//执行
List<Object> results = multi.exec();
if(results == null || results.size()==0) {
System.out.println("秒杀失败了....");
jedis.close();
return false;
}
//7.1 库存-1
//jedis.decr(kcKey);
//7.2 把秒杀成功用户添加清单里面
//jedis.sadd(userKey,uid);
System.out.println("秒杀成功了..");
jedis.close();
return true;
}
可以通过线程池解决链接超时问题
public class JedisPoolUtil {
private static volatile JedisPool jedisPool = null;
private JedisPoolUtil() {
}
public static JedisPool getJedisPoolInstance() {
if (null == jedisPool) {
synchronized (JedisPoolUtil.class) {
if (null == jedisPool) {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(200);
poolConfig.setMaxIdle(32);
poolConfig.setMaxWaitMillis(100*1000);
poolConfig.setBlockWhenExhausted(true);
poolConfig.setTestOnBorrow(true); // ping PONG
jedisPool = new JedisPool(poolConfig, "192.168.44.168", 6379, 60000 );
}
}
}
return jedisPool;
}
public static void release(JedisPool jedisPool, Jedis jedis) {
if (null != jedis) {
jedisPool.returnResource(jedis);
}
}
}
可以使用lua来解决库存遗留问题
public class SecKill_redisByScript {
private static final org.slf4j.Logger logger =LoggerFactory.getLogger(SecKill_redisByScript.class) ;
public static void main(String[] args) {
JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis=jedispool.getResource();
System.out.println(jedis.ping());
Set<HostAndPort> set=new HashSet<HostAndPort>();
// doSecKill("201","sk:0101");
}
static String secKillScript ="local userid=KEYS[1];\r\n" +
"local prodid=KEYS[2];\r\n" +
"local qtkey='sk:'..prodid..\":qt\";\r\n" +
"local usersKey='sk:'..prodid..\":usr\";\r\n" +
"local userExists=redis.call(\"sismember\",usersKey,userid);\r\n" +
"if tonumber(userExists)==1 then \r\n" +
" return 2;\r\n" +
"end\r\n" +
"local num= redis.call(\"get\" ,qtkey);\r\n" +
"if tonumber(num)<=0 then \r\n" +
" return 0;\r\n" +
"else \r\n" +
" redis.call(\"decr\",qtkey);\r\n" +
" redis.call(\"sadd\",usersKey,userid);\r\n" +
"end\r\n" +
"return 1" ;
static String secKillScript2 =
"local userExists=redis.call(\"sismember\",\"{sk}:0101:usr\",userid);\r\n" +
" return 1";
public static boolean doSecKill(String uid,String prodid) throws IOException {
JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis=jedispool.getResource();
//String sha1= .secKillScript;
String sha1= jedis.scriptLoad(secKillScript);
Object result= jedis.evalsha(sha1, 2, uid,prodid);
String reString=String.valueOf(result);
if ("0".equals( reString ) ) {
System.err.println("已抢空!!");
}else if("1".equals( reString ) ) {
System.out.println("抢购成功!!!!");
}else if("2".equals( reString ) ) {
System.err.println("该用户已抢过!!");
}else{
System.err.println("抢购异常!!");
}
jedis.close();
return true;
}
}
Redis6持久化之RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
示意图

fork
- Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
- 在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”
- 一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
持久化流程

dump.rdb文件
在redis.conf中配置文件名称,默认为dump.rdb

rdb文件的保存路径,也可以修改。默认为Redis启动时命令行所在的目录下dir “/myredis/”

如何触发RDB快照;保持策略
配置文件中默认的快照配置

命令save VS bgsave
- save :save时只管保存,其它不管,全部阻塞。手动保存。不建议。
- bgsave**:Redis会在后台异步进行快照操作,** 快照同时还可以响应客户端请求。
可以通过lastsave 命令获取最后一次成功执行快照的时间
flushall命令
执行flushall命令,也会产生dump.rdb文件,但里面是空的,无意义
Save
格式:save 秒钟 写操作次数
RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件,
默认是1分钟内改了1万次,
或5分钟内改了10次,
或15分钟内改了1次。
禁用
不设置save指令,或者给save传入空字符串
动态停止RDB:
redis-cli config set save “”#save后给空值,表示禁用保存策略
配置文件
stop-writes-on-bgsave-erro
当Redis无法写入磁盘的话,直接关掉Redis的写操作。推荐yes

rdbcompression
对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。
如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。推荐yes.

rdbchecksum 检查完整性
在存储快照后,还可以让redis使用CRC64算法来进行数据校验,
但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
推荐yes.

rdb的备份
先通过config get dir 查询rdb文件的目录
将*.rdb的文件拷贝到别的地方
rdb的恢复
- 关闭Redis
- 先把备份的文件拷贝到工作目录下 cp dump2.rdb dump.rdb
- 启动Redis, 备份数据会直接加载
优劣
优势
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适合使用
- 节省磁盘空间
- 恢复速度快

劣势
- Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
- 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。

Redis6持久化之AOF
简介
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
持久化流程
- 客户端的请求写命令会被append追加到AOF缓冲区内
- AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
- AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
- Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的;

AOF 默认不开启
可以在redis.conf中配置文件名称,默认为 appendonly.aof
AOF文件的保存路径,同RDB的路径一致。
AOF和RDB同时开启
AOF和RDB同时开启,系统默认取AOF的数据(数据不会存在丢失)
AOF启动/修复/恢复
- AOF的备份机制和性能虽然和RDB不同, 但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
- 正常恢复
- 修改默认的appendonly no,改为yes
- 将有数据的aof文件复制一份保存到对应目录(查看目录:config get dir)
- 恢复:重启redis然后重新加载
- 异常恢复
- n 修改默认的appendonly no,改为yes
- n 如遇到AOF文件损坏,通过/usr/local/bin/redis-check-aof–fix appendonly.aof进行恢复
- n 备份被写坏的AOF文件
- n 恢复:重启redis,然后重新加载
AOF同步频率设置
appendfsync always
始终同步,每次Redis的写入都会立刻记入日志;性能较差但数据完整性比较好
appendfsync everysec
每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
appendfsync no
redis不主动进行同步,把同步时机交给操作系统。
Rewrite压缩
简介
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, 只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof
原理与实现
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),redis4.0版本后的重写,是指上就是把rdb 的快照,以二级制的形式附在新的aof头部,作为已有的历史数据,替换掉原来的流水账操作。
no-appendfsync-on-rewrite:
如果 no-appendfsync-on-rewrite=yes ,不写入aof文件只写入缓存,用户请求不会阻塞,但是在这段时间如果宕机会丢失这段时间的缓存数据。(降低数据安全性,提高性能)
如果 no-appendfsync-on-rewrite=no, 还是会把数据往磁盘里刷,但是遇到重写操作,可能会发生阻塞。(数据安全,但是性能降低)
触发机制,何时重写
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。
auto-aof-rewrite-percentage:设置重写的基准值,文件达到100%时开始重写(文件是原来重写后文件的2倍时触发)
auto-aof-rewrite-min-size:设置重写的基准值,最小文件64MB。达到这个值开始重写。
例如:文件达到70MB开始重写,降到50MB,下次什么时候开始重写?100MB
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,
如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
重写流程
bgrewriteaof触发重写,判断是否当前有bgsave或bgrewriteaof在运行,如果有,则等待该命令结束后再继续执行。
主进程fork出子进程执行重写操作,保证主进程不会阻塞。
子进程遍历redis内存中数据到临时文件,客户端的写请求同时写入aof_buf缓冲区和aof_rewrite_buf重写缓冲区保证原AOF文件完整以及新AOF文件生成期间的新的数据修改动作不会丢失。
1).子进程写完新的AOF文件后,向主进程发信号,父进程更新统计信息。
2).主进程把aof_rewrite_buf中的数据写入到新的AOF文件。
使用新的AOF文件覆盖旧的AOF文件,完成AOF重写。

优劣
优势

- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
劣势
- 比起RDB占用更多的磁盘空间。
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
- 存在个别Bug,造成恢复不能。

选择建议
- 官方推荐两个都启用。
- 如果对数据不敏感,可以选单独用RDB。
- 不建议单独用 AOF,因为可能会出现Bug。
- 如果只是做纯内存缓存,可以都不用。
Redis6的主从复制
简介
主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
作用
- 读写分离,性能扩展
- 容灾快速恢复

具体操作
- 拷贝多个redis.conf文件include(写绝对路径)
- 开启daemonize yes
- Pid文件名字pidfile
- 指定端口port
- Log文件名字
- dump.rdb名字dbfilename
- Appendonly 关掉或者换名字
新建redis****.conf
include /myRedis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
启动三个服务

执行slaveof 主机ip 端口号
常用3招
一主二仆
- 当从服务挂掉之后,再次启动,不会继承之前的主从状态,此时该服务为master,需要重新设置,并且重新设置之后,会复制主服务的数据
- 当主服务挂掉之后,从服务的状态不会改变,当再次启动主服务的时候,还是会自动延续之前的主从状态,数据也会被复制到主服务中来,一切照旧
薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他 slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
- 用 slaveof
- 中途变更转向:会清除之前的数据,重新建立拷贝最新的
- 风险是一旦某个slave宕机,后面的slave都没法备份
- 主机挂了,从机还是从机,无法写数据了

反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
用 slaveof no one 将从机变为主机。
主从复制原理
- 服务器链接到主服务器之后,向主服务器发送数据同步消息
- 主服务器收到消息,将数据通过rdb方式进行持久化,将rdb文件传输给从服务器,从服务器通过rdb文件进行读取
- 每当主服务器进行了写操作,都会通知从服务器进行数据同步
- 从服务器只在第一次链接的时候主动请求数据同步,其他情况下都是由主服务器主导数据同步

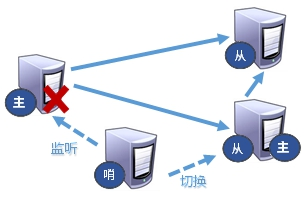
哨兵模式
简介
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
实现步骤
一仆二主模式
自定义的/myRedis目录下新建sentinel.conf文件
配置哨兵,填写内容
sentinel monitor mymaster 127.0.0.1 6379 1
其中mymaster为监控对象起的服务器名称, 1 为至少有多少个哨兵同意迁移的数量。
启动哨兵
/usr/local/bin
redis做压测可以用自带的re dis-benchmark工具
执行redis-sentinel /myredis/sentinel.conf
当主机挂掉,从机选举中产生新的主机
(大概10秒左右可以看到哨兵窗口日志,切换了新的主机)
哪个从机会被选举为主机呢?根据优先级别:slave-priority
原主机重启后会变为从机。
复制延时
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
故障恢复

优先级在redis.conf中默认:slave-priority 100,值越小优先级越高
偏移量是指获得原主机数据最全的
每个redis实例启动后都会随机生成一个40位的runid
java设置
private static JedisSentinelPool jedisSentinelPool=null;
public static Jedis getJedisFromSentinel(){
if(jedisSentinelPool==null){
Set<String> sentinelSet=new HashSet<>();
sentinelSet.add("192.168.11.103:26379");
JedisPoolConfig jedisPoolConfig =new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10); //最大可用连接数
jedisPoolConfig.setMaxIdle(5); //最大闲置连接数
jedisPoolConfig.setMinIdle(5); //最小闲置连接数
jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待
jedisPoolConfig.setMaxWaitMillis(2000); //等待时间
jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pong
jedisSentinelPool=new JedisSentinelPool("mymaster",sentinelSet,jedisPoolConfig);
return jedisSentinelPool.getResource();
}else{
return jedisSentinelPool.getResource();
}
}
Redis6集群
问题
容量不够,redis如何进行扩容?
并发写操作, redis如何分摊?
另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。
之前通过代理主机来解决,但是redis3.0中提供了解决方案。就是无中心化集群配置。
简介
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
配置
配置基本信息
开启daemonize yes
Pid文件名字
指定端口
Log文件名字
Dump.rdb名字
Appendonly 关掉或者换名字
redis cluster配置修改
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
include /home/bigdata/redis.conf
port 6379
pidfile "/var/run/redis_6379.pid"
dbfilename "dump6379.rdb"
dir "/home/bigdata/redis_cluster"
logfile "/home/bigdata/redis_cluster/redis_err_6379.log"
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
启动所有服务
将六个节点合成一个集群
组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
- 合体 cd /opt/redis-6.2.1/src
- edis-cli --cluster create --cluster-replicas 1 192.168.150.111:6379 192.168.150.111:6380 192.168.150.111:6381 192.168.150.111:6389 192.168.150.111:6390 192.168.150.111:6391
采用集群策略连接,设置数据会自动切换到相应的写主机
通过 cluster nodes 命令查看集群信息
节点分配
一个集群至少要有三个主节点。
选项 --cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
slots
[OK] All nodes agree about slots configuration.
>>> Check for open slots…
>>> Check slots coverage…
[OK] All 16384 slots covered.
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,
集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
在集群中录入值
在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。
redis-cli客户端提供了 –c 参数实现自动重定向。
如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。
不在一个slot下的键值,是不能使用mget,mset等多键操作。

可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去

查询集群中的值
CLUSTER GETKEYSINSLOT 返回 count 个 slot 槽中的键。

故障恢复
如果主节点下线,从节点能否自动升为主节点?注意:15****秒超时会

主节点恢复后,主从关系会如何?主节点回来变成从机。
如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使用,也无法存储。
redis.conf中的参数 cluster-require-full-coverage
集群的jedis
即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。
无中心化主从集群。无论从哪台主机写的数据,其他主机上都能读到数据。
public class JedisClusterTest {
public static void main(String[] args) {
Set<HostAndPort>set =new HashSet<HostAndPort>();
set.add(new HostAndPort("192.168.31.211",6379));
JedisCluster jedisCluster=new JedisCluster(set);
jedisCluster.set("k1", "v1");
System.out.println(jedisCluster.get("k1"));
}
}
优劣
优势
- 实现扩容
- 分摊压力
- 无中心配置相对简单
劣势
- 多键操作是不被支持的
- 多键的Redis事务是不被支持的。lua脚本不被支持
- 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
Redis6应用问题解决
缓存穿透

key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
解决方案
一个一定不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
- **对空值缓存:**如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟
- **设置可访问的名单(白名单):**使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问
- 采用布隆过滤器:(布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被 这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
- 进行实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
缓存击穿
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
**实时调整:**现场监控哪些数据热门,实时调整key的过期时长
使用锁:
- 就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
- 先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)(1) 去set一个mutex key
- 当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
- 当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。

缓存雪崩
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key正常访问

解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
- **构建多级缓存架构:**nginx缓存 + redis缓存 +其他缓存(ehcache等)
- 使用锁或队列:用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
- **设置过期标志更新缓存:**记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
- 分散缓存过期时间:比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
分布式锁
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁主流的实现方案:
基于数据库实现分布式锁
基于缓存(Redis等)
基于Zookeeper
每一种分布式锁解决方案都有各自的优缺点:
性能:redis最高
可靠性:zookeeper最高
这里,我们就基于redis实现分布式锁。
redis实现分布式锁
redis:命令
set sku:1:info “OK” NX PX 10000
EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
XX :只在键已经存在时,才对键进行设置操作。

多个客户端同时获取锁(setnx)
获取成功,执行业务逻辑{从db获取数据,放入缓存},执行完成释放锁(del)
其他客户端等待重试
java代码
@GetMapping("testLock")
public void testLock(){
//1获取锁,setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111");
//2获取锁成功、查询num的值
if(lock){
Object value = redisTemplate.opsForValue().get("num");
//2.1判断num为空return
if(StringUtils.isEmpty(value)){
return;
}
//2.2有值就转成成int
int num = Integer.parseInt(value+"");
//2.3把redis的num加1
redisTemplate.opsForValue().set("num", ++num);
//2.4释放锁,del
redisTemplate.delete("lock");
}else{
//3获取锁失败、每隔0.1秒再获取
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
问题:setnx刚好获取到锁,业务逻辑出现异常,导致锁无法释放
解决:设置过期时间,自动释放锁。
优化之设置锁的过期时间
设置过期时间有两种方式:
首先想到通过expire设置过期时间(缺乏原子性:如果在setnx和expire之间出现异常,锁也无法释放)
在set时指定过期时间(推荐)

残留问题
场景:如果业务逻辑的执行时间是7s。执行流程如下
\1. index1业务逻辑没执行完,3秒后锁被自动释放。
\2. index2获取到锁,执行业务逻辑,3秒后锁被自动释放。
\3. index3获取到锁,执行业务逻辑
\4. index1业务逻辑执行完成,开始调用del释放锁,这时释放的是index3的锁,导致index3的业务只执行1s就被别人释放。
最终等于没锁的情况。
解决:setnx获取锁时,设置一个指定的唯一值(例如:uuid);释放前获取这个值,判断是否自己的锁
优化之UUID防误删


问题:删除操作缺乏原子性。
优化之LUA脚本保证删除的原子性
@GetMapping("testLockLua")
public void testLockLua() {
//1 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
//2 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
// 3 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock) {
// 执行的业务逻辑开始
// 获取缓存中的num 数据
Object value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value + "");
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set("num", String.valueOf(++num));
/*使用lua脚本来锁*/
// 定义lua 脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,
// 那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}

Redis6新功能
ACL
简介
Redis ACL是Access Control List(访问控制列表)的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。
在Redis 5版本之前,Redis 安全规则只有密码控制 还有通过rename 来调整高危命令比如 flushdb , KEYS* , shutdown 等。Redis 6 则提供ACL的功能对用户进行更细粒度的权限控制 :
- 接入权限:用户名和密码
- 可以执行的命令
- 可以操作的 KEY
命令
- 使用
acl list命令展现用户权限列表

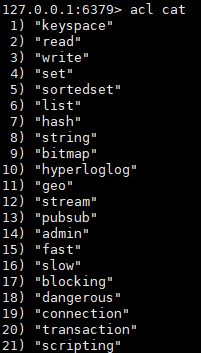
使用acl cat命令
查看添加权限指令类别
加参数类型名可以查看类型下具体命令
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ESLqIrqI-1655813763243)(https://pic.imgdb.cn/item/62b1b3960947543129cde382.png)]
使用
acl whoami命令查看当前用户[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QoEW2Uur-1655813763244)(https://pic.imgdb.cn/item/62b1b3b10947543129ce094c.png)]
使用
aclsetuser命令创建和编辑用户ACL规则:某些规则只是用于激活或删除标志,或对用户ACL执行给定更改的单个单词。其他规则是字符前缀,它们与命令或类别名称、键模式等连接在一起。
ACL规则 类型 参数 说明 启动和禁用用户 on 激活某用户账号 off 禁用某用户账号。注意,已验证的连接仍然可以工作。如果默认用户被标记为off,则新连接将在未进行身份验证的情况下启动,并要求用户使用AUTH选项发送AUTH或HELLO,以便以某种方式进行身份验证。 权限的添加删除 + 将指令添加到用户可以调用的指令列表中 - 从用户可执行指令列表移除指令 [email protected] 添加该类别中用户要调用的所有指令,有效类别为@admin、@set、@sortedset…等,通过调用ACL CAT命令查看完整列表。特殊类别@all表示所有命令,包括当前存在于服务器中的命令,以及将来将通过模块加载的命令。 [email protected] 从用户可调用指令中移除类别 allcommands [email protected]的别名 nocommand [email protected]的别名 可操作键的添加或删除 ~ 添加可作为用户可操作的键的模式。例如~*允许所有的键
通过命令创建新用户默认权限
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vjCpzbE3-1655813763245)(https://pic.imgdb.cn/item/62b1b4210947543129cec73e.png)]](/img/2e/6314d410c9fe5a423c8d87443a8f41.png)
在上面的示例中,我根本没有指定任何规则。如果用户不存在,这将使用just created的默认属性来创建用户。如果用户已经存在,则上面的命令将不执行任何操作。
设置有用户名、密码、ACL权限、并启用的用户
acl setuser user2 on >password ~cached:* +get
切换用户,验证权限

IO多线程
简介
IO多线程其实指客户端交互部分的网络IO交互处理模块多线程,而非执行命令多线程。Redis6执行命令依然是单线程。
原理
Redis 6 加入多线程,但跟 Memcached 这种从 IO处理到数据访问多线程的实现模式有些差异。Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想因为多线程而变得复杂,需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。整体的设计大体如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wSg43Msc-1655813763247)(https://pic.imgdb.cn/item/62b1b4cd0947543129cfdc38.png)]](/img/56/8c65216db900555b394d1d44295c5f.png)
另外,多线程IO默认也是不开启的,需要再配置文件中配置
io-threads-do-reads yes
io-threads 4
支持Cluster
之前老版Redis想要搭集群需要单独安装ruby环境,Redis 5 将 redis-trib.rb 的功能集成到 redis-cli 。另外官方 redis-benchmark 工具开始支持 cluster 模式了,通过多线程的方式对多个分片进行压测。
其他
Redis6新功能还有:
1、RESP3新的 Redis 通信协议:优化服务端与客户端之间通信
2、Client side caching客户端缓存:基于 RESP3 协议实现的客户端缓存功能。为了进一步提升缓存的性能,将客户端经常访问的数据cache到客户端。减少TCP网络交互。
3、Proxy集群代理模式:Proxy 功能,让 Cluster 拥有像单实例一样的接入方式,降低大家使用cluster的门槛。不过需要注意的是代理不改变 Cluster 的功能限制,不支持的命令还是不会支持,比如跨 slot 的多Key操作。
4、Modules API
Redis 6中模块API开发进展非常大,因为Redis Labs为了开发复杂的功能,从一开始就用上Redis模块。Redis可以变成一个框架,利用Modules来构建不同系统,而不需要从头开始写然后还要BSD许可。Redis一开始就是一个向编写各种系统开放的平台。
边栏推荐
猜你喜欢
Software testing - Test Case Design & detailed explanation of test classification

字节跳动提出轻量级高效新型网络MoCoViT,在分类、检测等CV任务上性能优于GhostNet、MobileNetV3!...
A detailed solution to mysql8.0 forgetting password

超快变形金刚 | 用Res2Net思想和动态kernel-size再设计 ViT,超越MobileViT
![[160. cross linked list]](/img/79/177e2c86bd80d12f42b3edfa1974ec.png)
[160. cross linked list]

底部菜单添加的链接无法跳转到二级页面的问题

让知识付费系统视频支持M3U8格式播放的方法

Visualization of wine datasets in R language
![[cm11 linked list splitting]](/img/66/6ac3f78db20ec7f177b88c88028dde.png)
[cm11 linked list splitting]

R language usarrests dataset visualization

随机推荐
如何计算 R 中的基尼系数(附示例)
Evaluation index and code realization (ndcg)
Golang学习笔记—结构体
A Dynamic Near-Optimal Algorithm for Online Linear Programming
84-我对网传&lt;52 条 SQL 语句性能优化策略&gt;的一些看法
让知识付费系统视频支持M3U8格式播放的方法
一行代码为特定状态绑定SwiftUI视图动画
The road to systematic construction of geek planet business monitoring and alarm system
Performance test (I)
[cm11 linked list splitting]
[redis]集群与常见错误
91-oracle普通表改分区表的几种方法
扩展Ribbon支持基于元数据的版本管理
Several common MySQL commands
Golang學習筆記—結構體
Feign FAQ summary
苹果CoreFoundation源代码
阿里云视频点播播放出错,控制台访问出现code:4400
87-with as写法的5种用途
程序员必看的学习网站