当前位置:网站首页>CV - baseline summary (development history from alexnet to senet)
CV - baseline summary (development history from alexnet to senet)
2022-06-12 23:35:00 【A deep slag who loves learning】
One 、 The original
Deep learning starts from 2015 Since then , The model is also iteratively optimized ;
Now many new models often stand on the shoulders of giants , I want to record here baseline A process of model development , And constantly updated content ; Each layer of the model will not be split , Instead, key innovation points are recorded , Of course, it also includes some personal understanding and thinking , If there is something wrong or incomplete, you are welcome to communicate , I also hope to improve my understanding of the model in future work ;
BaseLine What do you mean ?
Usually we also call BaseLine Model is classified model , It is often used to implement a classification task when getting started . But these models do not just appear in classification tasks , But the whole CV The cornerstone of the field . Detection of rear contact 、 Division 、 Key point regression and other tasks , Are inseparable from a key step —— feature extraction ; This key step is based on the feature map after feature extraction ,BaseLine Models are essential for these tasks , And choose different models , It also has a great impact on the performance of the whole task ( Of course, we do not rule out designing our own models for feature extraction )
Two 、AlexNet
significance : A model belonging to the originator of the opening , The prologue of convolution network dominating computer vision ;
This model is relatively simple , Take a look directly at Network structure chart :

This network has a feature , Lies in two GPU Parallel training and final fusion , To use more training resources , The idea of setting this network structure is also involved in the new network , You can start here first Mark once ;
Key concepts
One 、ReLU The proposal of activation function , What are the advantages ?
First ReLU and Sigmoid Equal activation functions are nonlinear activation functions , Because if you use a linear activation function , So there is no difference between a neural network with multiple hidden layers and a single layer , It will lose the characteristics of convolution network ;
Here's a comparison Sigmoid Functions and ReLU function , Let's first look at the formula , This must be remembered ;
Sigmoid Calculation formula :
y = 1 1 + e − x y=\frac{1}{1+e^{-x}} y=1+e−x1
The gradient formula :
y ′ = y ∗ ( 1 − y ) y^{\prime}=y *(1-y) y′=y∗(1−y)
ReLu Calculation formula :
y = m a x ( 0 , x ) y = max(0, x) y=max(0,x)
The gradient formula :
y ′ = { 1 , x > 0 undefined, x = 0 0 , x < 0 y^{\prime}=\left\{\begin{array}{cc} 1, & x>0 \\ \text { undefined, } & x=0 \\ 0, & x<0 \end{array}\right. y′=⎩⎨⎧1, undefined, 0,x>0x=0x<0

As can be seen from the two pictures above ,sigmoid Function in x When the value is large or small , The gradient is almost 0, Will cause the gradient to disappear ;
ReLU There are the following points :
1、 Make web training faster ( Because the calculation is simple and the gradient is greater than 0 The area gradually increases )
2、 Prevent the gradient from disappearing ;
3、 Make the network sparse ( When x It's a negative number , The gradient of 0, Neurons do not participate in training )
reflection :
ReLU In less than 0 It's about , The gradient is also 0, Is there room for improvement ?
Leaky relu It's right ReLU An improvement of , Solved the above problems ;
Calculation formula :
y = m a x ( 0.01 x , x ) y = max(0.01x, x) y=max(0.01x,x)
Two 、 Calculation of convolution layer output size ?
The parameters we pass into the convolution are : Enter picture size I * I、 Convolution kernel size K * K、 step S、 fill Padding by P
Output size calculation formula :
O = ( I − K + 2 P ) / S + 1 O = (I - K+2P) / S +1 O=(I−K+2P)/S+1
3、 ... and 、Dropout The concept of
Random inactivation of neurons , The function is to reduce over fitting , Improve the generalization ability of the network ;
For a more detailed explanation, please refer to this article :https://zhuanlan.zhihu.com/p/77609689
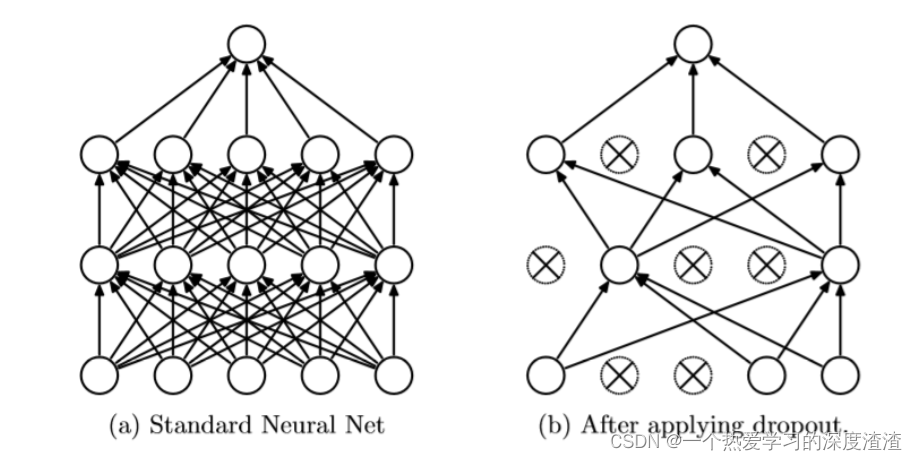
Be careful : The test requires multiplying the output of the neuron by the inactivation ratio p;
3、 ... and 、VGG
significance :VGG So far, it has been used as the backbone structure by other networks , It opens the small convolution kernel 、 The age of deep convolution ;

The figure is given in the paper VGG An evolving process , At present, the main use is VGG16【D】 and VGG19【E】;
Key concepts
One 、 The stack 3x3 A function of convolution ? Why is small convolution kernel better than large convolution kernel ?
In fact, the function of convolution is to continuously extract the features of the input image , stay AlexNet Using a large convolution kernel , In this way, the sampling speed is faster , The number of layers of the model is not much . stay VGG Use in 3x3 After convolution kernel , Usually it is 2 Times the probability of down sampling , It helps to deepen the number of layers of the network ;
advantage :
1、 Increase the receptive field
2 individual 3 * 3 Stacking is equivalent to 1 individual 5 * 5, They feel the same way ;
2、 Reduce computation
Three 3x3 The parameter quantity required for convolution kernel is 27C
One 7x7 The parameter quantity required for convolution kernel is 49C
Both have the same receptive field , But with 3x3 The convolution kernel parameters are reduced 44%
Expand your thinking :**1x1 What does convolution kernel do ?** The next network will explain ;
Two 、 How to set the network to any size input ?
When there is a full connection layer in the model , The input to the model is fixed , Can the full connection layer be replaced ?
Replace the last full connection layer with the convolution layer , As shown in the figure below :

The idea here is very important , With the development of the Internet , Due to the large amount of computation and the limitation on the input size of the full connection layer , Slowly replaced by convolution ;
Of course, the most important thing is , In the subsequent FCN in , It is also in the form of full convolution , Network structure to realize encoding and decoding ;
Four 、GoogleNet
here GoogleNet It is divided into V1、V2、V3、V4 Four versions , Because it is not commonly used nowadays , Here we mainly introduce its key ideas ;
There are no versions here , Mainly explain the important concepts ,GoogleNet What is important is that some of them trick;
The first thing to know is Inception modular

characteristic : Improve the utilization of computing resources , Increase the depth and width of the network , A small increase in parameters ;
Key concepts
One 、1x1 The function of convolution ?
This concept belongs to a very important one , stay Inception There are many uses in the module , And in ResNet Also used in ;
characteristic : Only change the number of output channels , Do not change the width and height of the output ;
effect :
1、 Play the role of dimension increase or dimension decrease , Can be used to compress the thickness , It can be used for the final classification output ;
2、 Increase nonlinearity , You can add one layer while keeping the number of channels unchanged 1x1 Convolution ;
3、 Reduce computation , Reduce the number of channels , The amount of calculation is naturally reduced ;
Two 、 What is the concept of ancillary loss ?
This concept is not common in subsequent networks , The main purpose is to extract the middle layer information for classification ;
Realization : A loss is computationally calculated at the middle layer output , Weighted with the loss of the final output ;
Personal understanding :
This trick It's not really necessary , You want to use the information of the middle layer in the subsequent network , The method of feature fusion can be adopted , use concat perhaps add The way , It is more effective than auxiliary loss ;
3、 ... and 、 A definition of sparse matrix ?
We often hear a concept , Make the network sparse , So what about sparsity , What are the advantages ?
sparse matrix :
The value is in the matrix 0 The number of elements is far more than that of non - elements 0 Element quantity , And it's irregular ;
Dense matrix :
The values in the matrix are not 0 There are far more elements than 0 Number of elements , And it's irregular ;
advantage : Sparse matrix can be decomposed into dense matrix to accelerate convergence , The simple conclusion is that it can not only reduce the memory but also improve the training speed ;
Four 、BN What is the role of layers ?
Reference article :https://blog.csdn.net/weixin_42080490/article/details/108849715
Its full name is Batch Normalization, Mainly to solve the problem that as the network deepens , Training is getting slower , The problem of slower and slower convergence ;
The cause of the problem :
With the stacking of network layers , The update of the parameters of each layer will lead to the change of the input data distribution of the upper layer , In this way, the high-level input distribution will change dramatically , So that the high-level has to constantly adapt to the low-level parameter update ; This condition is also called internal covariate offset , That is to say ICS;
In the training process of neural network, the input of each layer of neural network keeps the same distribution ;
Practical use : Change the data to a mean of 0 The standard deviation is 1 The standard normal distribution of , Make the input value of the activation function fall in the sensitive area , The output of the network will not be very large , You can get a larger gradient , The problem of gradient disappearance is avoided , It also accelerates training ;
The main role :
1、 Speed up the training and convergence of the network ( here GoogleNetV2 The mid version is faster than the previous version 10 times )
2、 Control the gradient explosion to prevent the gradient from disappearing ;
3、 Prevent over fitting ;
Be careful :
Used BN After the layer , We can abandon dropout This operation , And there is no need to pay too much attention to the initialization of weights , We can also use a larger learning rate to accelerate the convergence of the model , There are really many benefits , Basically, every network will add such a structure ;
5、 ... and 、 What strategy is convolution decomposition ?
1、 The large convolution kernel is decomposed into small convolution kernel stacks ;
Here is also the two 3x3 Convolution instead of a 5x5 Convolution ;
2、 It's broken down into asymmetric convolutions ;
That is to say nxn The convolution of is decomposed into a 1xn And a nx1 The stack of convolutions ;
This is mainly to reduce network parameters , But this strategy is only useful when the resolution of the network feature map is small , So it is not common in subsequent networks
6、 ... and 、 What is the label smoothing strategy ?
problem :
Conventional One-hot There is a problem with coding , That is, overconfidence , It is easy to cause over fitting ;
resolvent :
Put the label smooth , take One-hot The confidence in the code is 1 The item of is attenuated , Avoid overconfidence , The part that will decay confience Average into each category ;
Example :
The original tag value is (0,1,0,0) ——>>(0.00025,0.99925,0.00025,0.00025)
Then it is passed into the loss function ;
5、 ... and 、ResNet
ResNet As and VGG It is also the most popular convolutional neural network structure in industry , Its important modules are shown in the figure below :

Its significance is to promote the network to a deeper level of development , Successfully trained hundreds of layers of network for the first time ;
Key concepts
One 、 What is the above structure called ? What does it do ?
Reference article :https://zhuanlan.zhihu.com/p/80226180
The structure in the above figure is called residual structure (Residual learning)
What problems will arise from deepening the network layer ?
1、 It is easy to produce gradient disappearance or gradient explosion ( Can be BN Layer and regularization are added to solve )
2、 Network degradation : The performance of the network is gradually saturated with the increase of the number of layers , And then it goes down rapidly ( Network optimization is difficult )
The residual structure is also a process of network identity mapping , The formula is as follows :
F ( x ) = W 2 ∗ R e L U ( W 1 ∗ x ) F(x) = W2*ReLU(W1*x) F(x)=W2∗ReLU(W1∗x)
H ( x ) = F ( x ) + x = W 2 ∗ R e L U ( W 1 ∗ x ) + x H(x) = F(x) + x = W2*ReLU(W1*x) + x H(x)=F(x)+x=W2∗ReLU(W1∗x)+x
When F(x) by 0 when ,H(x)= x, Therefore, the identity mapping of the network is realized ;
effect :
1、 Conducive to gradient propagation , So that the gradient does not disappear or explode , The network can be stacked to thousands of layers ;
2、 The jump connection structure is introduced , It plays the role of quoting upper level information , There is also a concept of integrated learning ;
Of course , In order to reduce the amount of calculation , It also introduces the previously improved 1x1 Convolution for ascending and descending dimensions :

6、 ... and 、ResNeXt
The main idea : be based on ResNet The Internet , Introduced Inception The concept of aggregation transformation in ;

Key concepts
One 、 What is block convolution ? What's the role ?

Like the structure above , Is the structure of block convolution , The idea comes from AlexNet Split the convolution into two GPU On this idea ;
Implementation strategy : Divide the input feature map into C Group , Normal convolution is performed inside each group , Then, the output characteristic map is obtained by channel splicing ;
effect :
1、 Use fewer parameters to get the same characteristic graph ;
2、 Let the network learn more different characteristics , Get more information ;
Be careful : Although block convolution is similar to deep separable convolution , But it's not the same , Then we will introduce ;
7、 ... and 、DenseNet
significance : For the convolution network short path and feature resuse Rethinking , Achieve better results ;
Whole DenseNet The network is divided into three parts , That is, head convolution 、Dense Block The stack , Fully connected output classification probability ;
Header convolution is the operation of convolution and pooling to control the output dimension , This time we will mainly explain Dense This structure ;

Key concepts
One 、 What is dense connection ? What are the advantages ?
DenseNet The most important structure in is shown in the figure above , Call it dense connection ;
Mainly in a Block in , The input of each layer comes from the characteristic diagram of all the layers before it , The output of each layer is directly connected to the input of all layers behind it ;
effect :
1、 Get more features with fewer parameters , Reduced the amount of parameters ,DenseNet Only by the ResNet1/3 The accuracy of the parameters is similar ;
2、 Low level feature reuse , More features ;
3、 Stronger gradient flow , More hop structures , Gradients are easier to propagate forward ;
Be careful :
Dense connections actually play the role of regularization on small data , There is a saying that dense connections are more suitable for small data sets ;
shortcoming :
DenseNet Your training is a huge drain on storage resources , Because a large number of characteristic graphs need to be reserved for back propagation calculation ;
Two 、 Feature fusion add and concat What's the difference ? Which is better? ?
add: The values of the characteristic graph are added , The number of channels remains unchanged ;
concat: It refers to feature map splicing , The number of channels increases ;
Personal understanding : In fact, the difference between the two is add Is the addition of two characteristic graphs , There is a risk of losing information ,concat It is feature map splicing , Keep all original information , So use concat The way will be better , but add The required memory and parameters will be less than concat;
8、 ... and 、SENet
significance : The attention mechanism was first introduced into convolutional neural networks , And the mechanism is a plug and play module ;

The above figure is the most important module structure in the network ——SE block, It embodies the process of compression and fusion ;
Key concepts
One 、 What is the core idea of attention mechanism ?
Attention mechanism can be understood as , Design some weight values of network output layer , Use weight value and characteristic graph to calculate , Realize the transformation of characteristic graph , Make the model strengthen the eigenvalue of the concerned area ;
Two 、SE—block The principle of structure , How to realize the attention mechanism ?
From the picture above, we can see ,SE—block It is mainly divided into three parts :Squeeze、Excitation、Scale;
Squeeze: Through global average pooling (GAP) Compress the feature map to vector form (1x1xC);
Excitation: Two fully connected layers map and transform the feature vector , Finally, a sigmoid Limit the scope to [0, 1];
Scale: The weight vector obtained is multiplied by each original channel to obtain the weighted characteristic graph ;
summary :
The above is how the attention mechanism is implemented , Of course, attention mechanism can not only act on channels , It can also act on HxW, Some frontier applications of attention mechanism are also used for VIT in , If you are interested, you can understand Attation Development and application of ;
Last
This will also CV—Baseline The basic models in , But only from some characteristics of the network , Some small trick It is not explained in this article , If you are interested, you can read the paper ;
Of course , Understanding the principles of a model is not a mastery of the model , Code implementation is also a key step , It is hoped that each module and structure can be implemented with a familiar framework , Especially for the official open source code , principle + Only when you are proficient in the code can you really master ;

边栏推荐
- Qrcodejs2 QR code generation JS
- About three-tier architecture and MVC
- For product managers, which of the two certificates, PMP and NPDP, is more authoritative?
- RT thread quick start - experience RT thread
- ShardingSphere-proxy-5.0.0部署之分表实现(一)
- How to package a colorpicker component for color selection?
- The fate of Internet people is that it is difficult to live to 30?
- Heilongjiang Branch and Liaoning Branch of PostgreSQL Chinese community have been established!
- Leetcode 890 finding and replacing patterns [map] the leetcode path of heroding
- Model over fitting - solution (II): dropout
猜你喜欢

2022年R2移动式压力容器充装考试题及在线模拟考试

2022 questions d'examen pour le personnel de gestion de la sécurité de l'unit é de gestion des produits chimiques dangereux et examen de simulation en ligne

CST learning: four element array design of circular patch antenna (II) array formation and combination results

Deep feature synthesis and genetic feature generation, comparison of two automatic feature generation strategies

Comprehensive analysis of C array

Teach you how to grab ZigBee packets through cc2531 and parse encrypted ZigBee packets

The carrying capacity of L2 level ADAS increased by more than 60% year-on-year in January, and domestic suppliers "emerged"

Model over fitting - solution (II): dropout

Colab教程(超级详细版)及Colab Pro/Colab Pro+使用评测

Gb28181 protocol -- alarm
随机推荐
2022年电工(初级)操作证考试题库及在线模拟考试
Qrcodejs2 QR code generation JS
Lua date time
妙才周刊 - 5
Access static variables within class in swift
同花顺股票账户开户安全吗
The "fourteenth five year plan" development plan and panoramic strategic analysis report of China's information and innovation industry 2022 ~ 2028
[North Asia data recovery] data recovery cases in which the partitions disappear and the partitions are inaccessible after the server reinstalls the system
Go time format assignment
【建议收藏】通俗易懂图解网络知识-第一篇
C language: how to give an alias to a global variable?
lua 循环语句
InfoQ 极客传媒 15 周年庆征文|简述构建微服务架构的四大挑战
[Yugong series] wechat applet in February 2022 - Reference
Message queue directory
ASP. Net core Middleware
Hongmeng starts 2
启牛帮开通的股票账户是安全可信的吗?
The development trend of digital collections!
Module 8 operation