当前位置:网站首页>【mysql进阶】索引分类及索引优化方案(五)
【mysql进阶】索引分类及索引优化方案(五)
2022-06-12 13:42:00 【wu_55555】
文章目录
0. 引言
索引是数据库中占据着核心地位,它能帮助服务器减少需要扫描的数据量,减少排序和临时表,大大提高查询效率,因此索引的使用在数据库中是必须掌握的技能,但是不正当的使用索引,不能不能提高性能,反而会降低运行效率。
因此今天,我们就来谈谈如何正确建立索引,索引如何优化
1. 索引的分类
在正式开始讲述之前,我们依然要先理解索引有哪几种,每种是用场景是什么,这样才能正确选型
有很多同学看到这个问题就会一股脑的说,索引有主键索引、唯一索引、普通索引、全文索引、组合索引、聚簇索引、非聚簇索引这几种。
然而这样的说法,并不正确,因为这些索引类型并不在一个维度。就好像聚簇索引严格上来讲并不是索引类型,而是索引的存储方式。
所以下面我们按照不同的维度,来向大家介绍这些索引类型
1.1 按数据结构分类
索引的底层数据结构B+树,hash表,如果不清楚的可以查看专栏的上一篇文章。
所以按照数据结构来分,有B+树索引、Hash索引,同时还有一个全文索引,专用于text类型建立的索引
1.2 按照物理存储分类
mysql中有聚簇索引和非聚簇索引,这两种索引实际上并不是索引,而是索引的存储方式。
mysql常用的两种存储引擎:innodb和myisam。
innodb采用的存储方式就是聚簇索引,即索引与数据是放在一个文件中的,我们在data文件中,查看采用了innodb的数据库文件,会发现每张表都有一个.ibd文件
myisam采用的存储方式是非聚簇索引,即索引和数据不是放在一个文件中的, 同样我们查看采用myisam的数据库文件
因为数据库默认采用innodb存储引擎,我们先将其中一个表的存储引擎修改为myisam
alter table user engine=myisam;
然后查看文件,我们发现user表的数据库文件变成了两个,一个.MYD,一个.MYI。即myisam data和myisam index
1.3 按字段类型分类
按照字段类型分类有:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(NORMAL)、全文索引(FULLTEXT)
在利用navicat等数据库管理工具创建索引时也可以看到其索引类型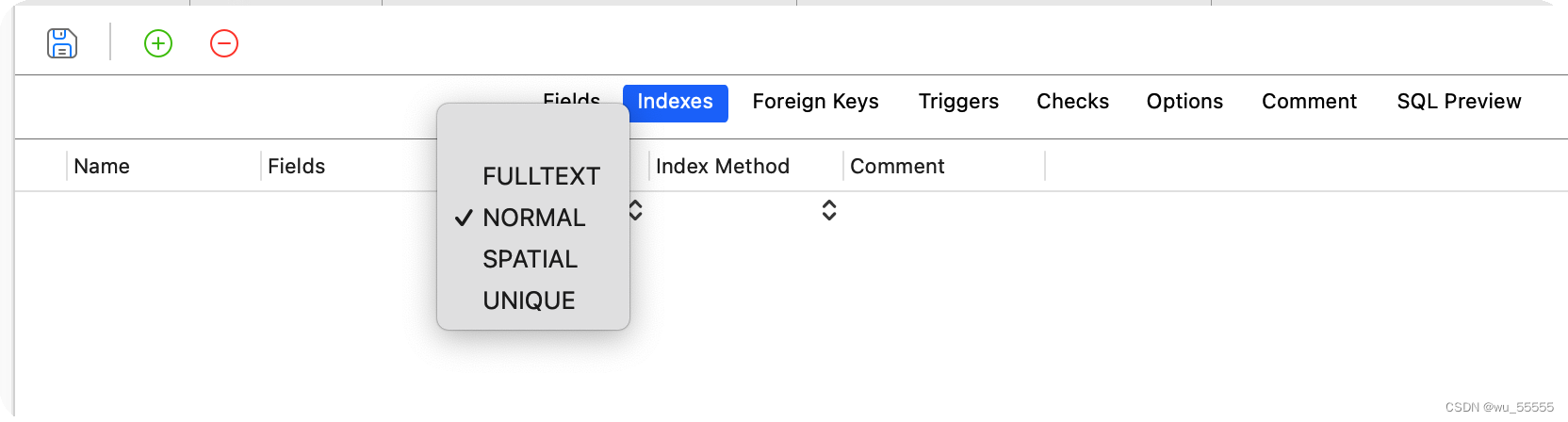
- 主键索引:用于主键
- 唯一索引:使用唯一索引的数据要求保证唯一性,常用在编号、单据号等唯一性数据上
- 普通索引:无使用限制
- 全文索引:CHAR、VARCHAR ,TEXT 类型
1.4 按字段个数分类
从字段个数来看,我们分为单列索引和组合索引
2. 基本概念
我们还要理解几个基本概念,才能理解索引优化的思路
1.1 回表
学习了上一章的同学会知道,B+树索引的数据结构如图所示(索引默认是B+树索引),其叶子节点中会存储索引值及对应的data。采用了聚簇索引存储方式的主键索引树的data是行数据,非聚簇索引存储方式的主键索引的data是指向行数据的内存地址指针。而非主键索引树其叶子节点存储的data则是主键值
什么是回表?简单来说就是需要走两个索引树才能查询到目标数据。按执行流程来讲,就是需要先根据非主键索引树找到对应的主键,然后根据主键在主键索引树中找到对应的行数据。这样的操作就叫回表。
其实我们把行数据理解为表,需要通过访问行数据才能找到想要的数据的操作就是回表。
我们举个例子:
user表中id是主键,name是索引,select * from user是回表操作吗?select id,name from user是回表操作吗
select * from user操作是一个回表操作。因为name索引中是无法提供全部数据的。
但是name索引中可以提供name和id数据,因此select id,name from user不是回表操作
实际开发中在满足业务需求的前提下,我们应当尽量避免回表操作
1.2 索引覆盖
不需要从主键索引树查询任何数据,直接从一颗索引树就能获取到所有目标数据,这就是索引覆盖,比如我们上述举的例子select id,name from user操作就满足索引覆盖
尽可能多的满足索引覆盖
1.3 最左匹配
最左优先,以最左边的为起点任何连续的索引都能匹配上。
我们用一个案例来理解这个概念
user表中id是主键,name,age是组合索引
在组合索引适用的时候,会先匹配name,然后才会匹配age。按照从做往右的顺序。同时范围查询会让这个查询后的索引失效
以下的几个语句,哪些会使用到组合索引?
1、select * from user where name=? and age=? 会
2、select * from user where name=? 会(只查name,不查age)
3、select * from user where age=? 不会
4、select * from user where age=? and name=? 会
5、select * from user where name=? and age>? 会
6、select * from user where id > ? and name=? and age=? 不会
解析:
1、name,age的调用顺序满足组合索引,所以会使用到组合索引
2、name作为查询条件,按照最左匹配原则,先匹配name。后续的age因为不需要查询,所以无需匹配,同时也会用到组合索引,可以理解为用一半
3、只用age作为查询条件,最左匹配原则要求先匹配name后才能匹配age,没有name开道age是不能先用的,所以无法使用组合索引
4、age,name作为查询条件,这个顺序刚好相反怎么会能使用组合索引呢?这是因为mysql有一个优化器,它会将执行顺序自动调换,会将区分度高的查询条件放前面,同时调整顺序使查询尽可能满足最左匹配。
区分度高是什么意思?举个例子,select * from user where id>14 and name='111'这个语句,如果name='111’这个条件能够排除更多的数据,使得剩下的数据更少,在更少的数据中查询满足id>14条件的数据就会更容易
所以优化器会将第4条语句调整为select * from user where name=? and age=?,自然能够使用组合索引
5、虽然说范围查询会使这个查询后的索引失效,但是当前这个范围查询如果作用在索引上依旧会生效,索引会使用组合索引
6、id>?的范围查询让后续的查询的索引失效了,所以不用使用组合索引
所以我们在书写sql的时候,要尽可能满足最左匹配原则,范围查询的时候要注意是否会影响索引
同时需要注意like语句中也有最左匹配原则体现,比如like '5%'是会使用索引进行查询的,而like '%5'或者like '%5%'是不会用索引进行查询的。所以我们经常会发现某些查询支持前缀查询,但不支持完全模糊查询,这就是原因。在满足业务的情况下,尽量使用前缀查询
1.4 索引下推
索引下推是个mysql自动优化的机制,在mysql5.6版本推出。不用我们手动调整,了解即可
在没有索引下推之前,mysql执行查询是通过索引先从存储引擎中把数据查询出来,返回给mysql服务器(server),然后再在server层处理针对查询条件的筛选,即判断数据是否符合查询条件
在有了索引下推之后,mysql服务器会先将存在索引的查询条件发送给存储引擎,然后存储引擎把满足索引查询条件的数据返回,mysql服务器收到数据后,再处理针对非索引的查询条件的数据筛选
还是上述的例子
user表中有组合索引name,age,执行select * from table where sex=? and name=? and age=?
没有索引下推:存储引擎根据name,age组合索引查询出主键,然后从主键树中查询出行数据,返回给mysql server,mysql server在返回数据中筛选满足sex=? and name=? and age=?条件的数据
有了索引下推:mysql server把name=? and age=?发送给存储引擎,存储引擎筛选出满足name=? and age=?条件的数据返回给server,server再从这些返回数据中筛选sex=?的数据
索引推优化减少存储引擎查询基础表的次数,同时减少了MySQL服务器从存储引擎接收数据的次数,提高了查询效率
3. 索引的优化
在了解了上述的基本概念后,相信部分同学心中已经有了一些索引优化的想法了,下面我们来详细列举
3.1 索引创建优化方案
满足以下几个条件的列,可以考虑创建索引:
- 1、频繁作为查询条件的字段
- 2、重复值较少的字段:一般区分度在80%以上的列才可以建立索引,区分度=
count(distinct(列名))/count(*) - 3、定义有外键的列
- 4、不经常更新的列: 频繁的更新会导致索引树结构的调整,会消耗大量的资源,反而降低mysql的性能
同时建立索引的列,也要注意以下几点:
- 1、尽量避免null值
null会导致很多难以察觉的查询失效 - 2、针对该索引的查询条件,要避免强制类型转换
强制类型转换会让索引失效。比如id是索引且是整型,查询条件为id='123'时,mysql会自动执行强制类型转换将’123’转换为123,但这时查询就不会再走索引,而是全表查询 - 3、尽量拓展索引,而不是删除后再创建:
比如原来有索引a,现在要再补充成为组合索引a,b,那就修改索引a为a,b。而不是直接删除索引a再创建组合索引a,b。这是因为索引树的构建过程很消耗资源,如果数据库正在运行,有消耗大量资源在索引的构建上,势必会影响其他业务的查询效率 - 4、类型为text,image,bit的列不建议建立索引,甚至不建议使用这几种数据类型
有全文检索的需求,更建议使用ES等搜索中间件 - 5、组合索引选择区分度更高的列在前
组合索引涉及多列,那么如何确定哪一列在前呢?首先要考虑业务需求,如果有先分组和排序的需求,则按照需求来确认字段顺序,如果没有这两个需求,那么就将区分度更高的字段排在前面,这样可以用该字段实现更高的筛选率,使得查询更精确。 - 6、避免重复的索引
如果已经建立了组合索引a,b,那么就不要对a再单独建立索引,这时a索引就是重复索引。但是b建立索引则不是重复索引 - 7、创建表的时候不要把所有索引都建立
实际我们不建议在一开始就把所有的索引一股脑的建立好,索引应该是根据业务情况循序渐进建立的。
3.2 索引使用优化方案
后续操作基于如下案例,我们通过explain语句来查看执行效果,如不了解explain语句的,可查看专栏之前文章
order表中有索引no,amount,主键id,组合索引weight,distance
3.2.1 以下几点会导致索引失效
1、范围查询后的索引查询会失效
2、不满足最左匹配原则的索引查询会失效
3、不同字符集之间的转换会导致索引失效,所以带有中文的数据库尽量使用utf8mb4
4、
like '%xx'查询会导致索引失效
explain select * from `order` where no like '%1'

- 5、计算、函数、类型转换会导致索引失效,所以计算过程尽量放到业务层处理
explain select * from `order` where no = 12

- 6、or连接了一个非索引列查询条件时,索引查询会失效
explain select * from `order` where no = '12' or address = '1'

- 7、除了上述几点外,当查询出的数量过大,与全表查询的效率差不多时,mysql就会取消索引查询,而直接全表扫描。这类情况常出现在使用
not 、<> 、!=、is null、is not null
3.2.2 索引使用优化细节
1、尽量使用主键查询,主键索引不会产生回表
2、使用前缀索引:有的时候索引列数据很长,如果创建索引的话会导致空间的浪费,一个数据页承装不了多少个索引,从而导致IO操作变多,查询减慢。所以我们可以通过截取前缀的概念来创建索引
# 创建索引时 只使用前7个字节
alter table user add key(name(7));
# 查询时
select name from user where left(name,7)='xxxxxxx';
3、使用索引来进行排序
4、使用索引字段来作为关联字段
5、单表索引应该控制在5个以内
6、组合索引字段数不宜超过5个
7、删除没有使用的索引
我们可以通过下述统计出索引的使用情况,查询出哪些索引一直没有使用,没有使用的索引可以考虑删除掉,不要浪费资源。
SELECT
OBJECT_SCHEMA,
OBJECT_NAME,
INDEX_NAME
FROM
table_io_waits_summary_by_index_usage
WHERE
INDEX_NAME IS NOT NULL
AND COUNT_STAR = 0
AND OBJECT_SCHEMA <> 'mysql'
ORDER BY
OBJECT_SCHEMA,
OBJECT_NAME;
总结
本期的分享就到此结束了,如果觉得文章对你学习有帮助,不妨点赞收藏加关注,下期见~
边栏推荐
- Pytoch official fast r-cnn source code analysis (I) -- feature extraction
- 2065: [example 2.2] sum of integers
- Codeforces 1638 B. odd swap sort - tree array, no, simple thinking
- Transmission and response of events and use cases
- Codeforces 1637 A. sorting parts - simple thinking
- C language array and pointer
- 创新实训(十一)开发过程中的一些bug汇总
- AWLive 结构体的使用
- 上海解封背后,这群开发者“云聚会”造了个AI抗疫机器人
- 高通平台开发系列讲解(协议篇)QMI简单介绍及使用方法
猜你喜欢

Innovation training (XI) summary of some bugs in the development process

Understanding recursion

C#DBHelper_ FactoryDB_ GetConn

Paw 高级使用指南

Script引入CDN链接提示net::ERR_FILE_NOT_FOUND问题

简历 NFT 平台 TrustRecruit 加入章鱼网络成为候选应用链

Octopus network progress monthly report | may 1-May 31, 2022

There was an error installing mysql. Follow the link below to CMD
![[WUSTCTF2020]颜值成绩查询-1](/img/dc/47626011333a0e853be87e492d8528.png)
[WUSTCTF2020]颜值成绩查询-1

When the byte jumps, the Chinese 996 is output in the United States
随机推荐
FFmpeg 学习指南
Codeforces 1629 D. pecuriar movie preferences - simple thinking, palindrome strings
Software construction 03 regular expression
C language structure
Scyther工具形式化分析Woo-Lam协议
Seekg, tellg related file operations
Code debugging - print log output to file
Recursion of subviews of view
D1 Nezha Development Board understands the basic startup and loading process
618进入后半段,苹果占据高端市场,国产手机终于杀价竞争
"Non" reliability of TCP
NVIDIA Jetson Nano Developer Kit 入门
Possible solutions to problems after CodeBlocks installation
[Title brushing] Super washing machine
MySQL 查询 limit 1000,10 和 limit 10 速度一样快吗? 深度分页如何破解
Overview of embedded system 2- composition and application of embedded system
Simple implementation of gpuimage chain texture
Tinyxml Usage Summary
JVM runtime parameters
Pytorch framework