当前位置:网站首页>Influxdb series (IV) TSM engine (storage principle)
Influxdb series (IV) TSM engine (storage principle)
2022-07-27 19:49:00 【Lin Musen^~^】
3、 ... and 、 principle
File directory
# wal Directory structure
-- wal
-- mydb
-- autogen
-- 1
-- _00001.wal
-- 2
-- _00035.wal
-- 2hours
-- 1
-- _00001.wal
# data Directory structure
-- data
-- mydb
-- autogen
-- 1
-- 000000001-000000003.tsm
-- 2
-- 000000001-000000001.tsm
-- 2hours
-- 1
-- 000000002-000000002.tsm
LSM Tree
The core of the core idea is to give up some reading ability , In exchange for maximum write capability . Its core idea is actually very simple , Is to first store the latest data in memory , Wait until you accumulate the last more , Then merge and sort the data in memory to the end of the disk queue
For disks , The way to maximize the characteristics of disk technology is : Read or write a fixed size piece of data at one time , And reduce the number of random seek operations as much as possible .
The evolution of the storage engine
LevelDB
A lot of shard File descriptor , Run out of system resources .
BoltDB
Random writes occur in some environments , Resulting in write performance degradation
Timing data 
It can be said that SeriesKey It's a data source
InfluxDB Use a... In memory Map To store timeline data , This Map It can be expressed as <Key, List>. among Key Expressed as seriesKey+fieldKey,Map In a Key Corresponding to one List,List Store timeline data in . In fact, this is a very natural idea , There are no profound difficulties . be based on Map Such a data structure , The process of writing timing data into memory can be expressed as the following three steps :
After the time series data enters the system, first according to measurement + tags Piece together seriesKey
According to this seriesKey And to be checked fieldKey Piece together Key, And then Map According to the Key Find the corresponding time series set , If not, create a new List
Once found, it will Timestamp|Value The combined value is added to the timeline data link list
TSM Storage engine
TSM The storage engine consists of several parts : cache、wal、tsm file、compactor.
cache、wal
When inserting data , In fact, at the same time cache And wal Middle write data , It can be said that cache yes wal Data in the file is cached in memory . When InfluxDB Startup time , Will traverse all wal file , Reconstruct cache, So even if the system breaks down , It will not lead to the loss of data .
**cache The data in is not infinitely growing , There is one maxSize Parameters are used to control when cache How much memory is used by the data in will be written to tsm file .** If not configured , The default upper limit is 25MB, whenever cache After the data in the , Will put the current cache Take a snapshot , Then clear the current cache The content in , Create a new one wal The file is used to write , The rest wal The file will be deleted at the end , The data in the snapshot will be sorted and written to a new tsm In file .
current cache There is a problem with the design of , When a snapshot is being written to a new tsm When you file , Current cache Because a lot of data is written , Reached the threshold again , At this time, the previous snapshot has not been completely written to disk ,InfluxDB The best way is to make subsequent write operations fail , Users need to handle it by themselves , Continue writing data after waiting for recovery
TSM file
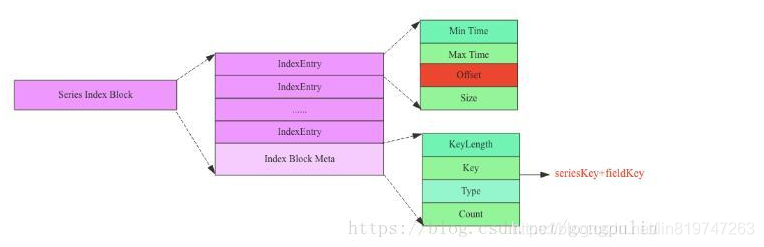
Single tsm The main format of the document is as follows
It is mainly divided into four parts : Header, Blocks, Index, Footer.
among Index Part of the contents will be cached in memory , The data structure of each part is described in detail below .



compactor
compactor Components continue to run in the background , every other 1 Seconds to check if there is any data that needs to be compressed and merged .
There are two main operations , One is cache When the size of the data in reaches the threshold value , Take a snapshot , Then transfer to a tsm In file .
The other is to merge the current tsm file , Will be more than one small tsm Merge the files into one , Make each file as large as possible as a single file , Reduce the number of files , And some data deletion operations are also completed at this time .
Read and write flow
Reading process

First of all, according to the Key Find the corresponding SeriesIndex Block, because Key Is ordered , So you can use binary search to implement
find SeriesIndex Block Then, according to the search time range , Use [MinTime, MaxTime] The index locates to possible Series Data Block list
The Series Data Block Load it into memory, decompress it, and then use the binary search algorithm to find
Writing process
- httpd The service parses out all to be inserted Points, And database , Storage strategy, etc , Then call PointsWriter Of WritePoints Method insert data .
WritePointsThe function will according to Point The timestamp of determines which one it belongs to Shard, Then callwriteToShardFunction batch will Points Write to different Shard in .
Hardware promotion 
边栏推荐
- GestureDetector(手势识别)
- [basic knowledge of deep learning - 44] the method of realizing multiple classification by logistic regression
- Dry goods of technical practice | preliminary exploration of large-scale gbdt training
- 王牌代码静态测试工具Helix QAC 2022.2 中的新增功能(1)
- Map和Set
- 爱立信承认在中国等五国行贿,向美支付10.6亿美元罚款
- 时间复杂度和空间复杂度
- 嵌入式C语言结构体
- What's new in helix QAC 2022.2, the ace code static testing tool (1)
- 下放三星3J1传感器:代码暗示Pixel 7人脸识别安全性将大增
猜你喜欢

Chinese character search Pinyin wechat applet project source code

C language: 13. Pointer and memory
C language: 7. How to use C language multi source files

Original pw4203 step-down 1-3 lithium battery charging chip
Map and set
技术实践干货 | 初探大规模 GBDT 训练

应用程序池已被禁用
C language: 14. Preprocessing

RadioGroup(单选框)
【深度学习基础知识 - 45】机器学习中常用的距离计算方法

随机推荐
27. Basics of golang - mutex lock, read / write lock
[Huawei cloud stack] [shelf presence] issue 13: have you seen the decoupling architecture of the management area? Help government and enterprise customers solve big problems
C language: 11. Pipeline
英特尔推出全球最小的高分辨率激光雷达,售价仅349美元
Introduction to Flink operator
首发骁龙765G!Redmi K30 5G版发布:支持5G双模120Hz屏,定价1999元起
爱立信承认在中国等五国行贿,向美支付10.6亿美元罚款
[basic knowledge of deep learning - 43] concept of odds ratio
【深度学习基础知识 - 37】解决正负样本不均衡 Focal Loss
What's new in helix QAC 2022.2, the ace code static testing tool (1)
FileOutputStream(文件储存)与FileInputStream(文件读取)
【深度学习基础知识 - 45】机器学习中常用的距离计算方法
IIS 发生未知FastCGI错误:0x80070005
嵌入式C语言结构体
[deep learning target detection series - 01] what is target detection
Intent(有无返回值得跳转)
[daily accumulation - 06] view CUDA and cudnn versions
【深度学习基础知识 - 43】优势比的概念
C language: 10. Input stream, output stream, error stream
[basic knowledge of deep learning - 42] detailed explanation of logistic regression