当前位置:网站首页>A quick overview of transformer quantitative papers in emnlp 2020
A quick overview of transformer quantitative papers in emnlp 2020
2022-07-27 07:56:00 【51CTO】

I spent a few days reading three articles EMNLP 2020 About China Transformer Related papers on model quantification , Take a quick note of the main points .
Fully Quantized Transformer for Machine Translation
This is a collaboration between Huawei Noah Ark laboratory and the University of Montreal , Published in findings above .
「 Address of thesis :」 https://www.aclweb.org/anthology/2020.findings-emnlp.1.pdf

Method
in the light of Transformer The structure of computationally intensive operators is carried out activation quantitative , except bias All but weight It is quantified , In fact, our group has also done this .
It's quantitative perception training (QAT), Back propagation uses straight-through estimator.
Consider each channel There are differences in the distribution of , So for each channel Learn quantifiable alone scale Parameters .
Zero value processing :padding Don't need to consider , It will be mask fall .ReLU and attention softmax The lower bound of quantification is as follows 0. All quantification is added to dropout Before .
Pruning adopts structural pruning , Because sparsity pruning requires hardware or library support , More trouble . Here only for FFN Parameter to prune , And not the traditional percentage threshold , But according to ReLU Then the first layer is calculated FFN Output of each column max value , according to max Whether the value exceeds a certain threshold to prune , This threshold is set to all columns max The variance of a value is multiplied by a constant . The advantage here is that the percentage of pruning is not fixed , Each layer of dynamic shear , More or less .
experimental result

You can see that after training, you can quantify (PTQ) It's still a little bit lower , and QAT Of 8 Bit or 6 It doesn't drop much ,4 It will have a great influence . The result is also in line with the practical effect of our group .
evaluation
There is no innovation in this article , But in the end it's just findings, No one will . Quantify location and some trick It's easy to think of , And each channel In fact, it has little significance in practice , Without this trick The effect is good, too .FFN In the end, we didn't cut out many parameters .
Extremely Low Bit Transformer Quantization for On-Device Neural Machine Translation
This one is made by Samsung , Also published in findings above .
「 Address of thesis :」 https://www.aclweb.org/anthology/2020.findings-emnlp.433.pdf

Method
This article does not use the more commonly used uniform Quantitative way ( In other words, the floating-point interval is mapped to the integer interval in equal proportion ), instead binary-code, That is to say, the parameter Expressed as ( Quantization Bits ) Binary vectors of the same dimension The linear combination of , Finally, the multiplication of a matrix and a vector becomes : , For details, please refer to the previous papers of Samsung :BiQGEMM: Matrix Multiplication with Lookup Table For Binary-Coding-based Quantized DNNs.
This article aims at embedding Different word frequency of the word uses different quantized digits , The specific scheme can see the following pseudo code :

In short, the higher the frequency of words , The more quantized digits . And most words are very low ,1% That's the word that occupied 95% The frequency of words , So if they have a higher number, it doesn't matter . For each word vector , Different quantization parameters are used , This also takes into account that the spatial distribution of each word vector is different .
in the light of encoder and decoder Different types of attention, The paper also uses different quantized digits .
Training strategy , here finetune Each stage 2000 Step open a quantification , To save training time .
experimental result
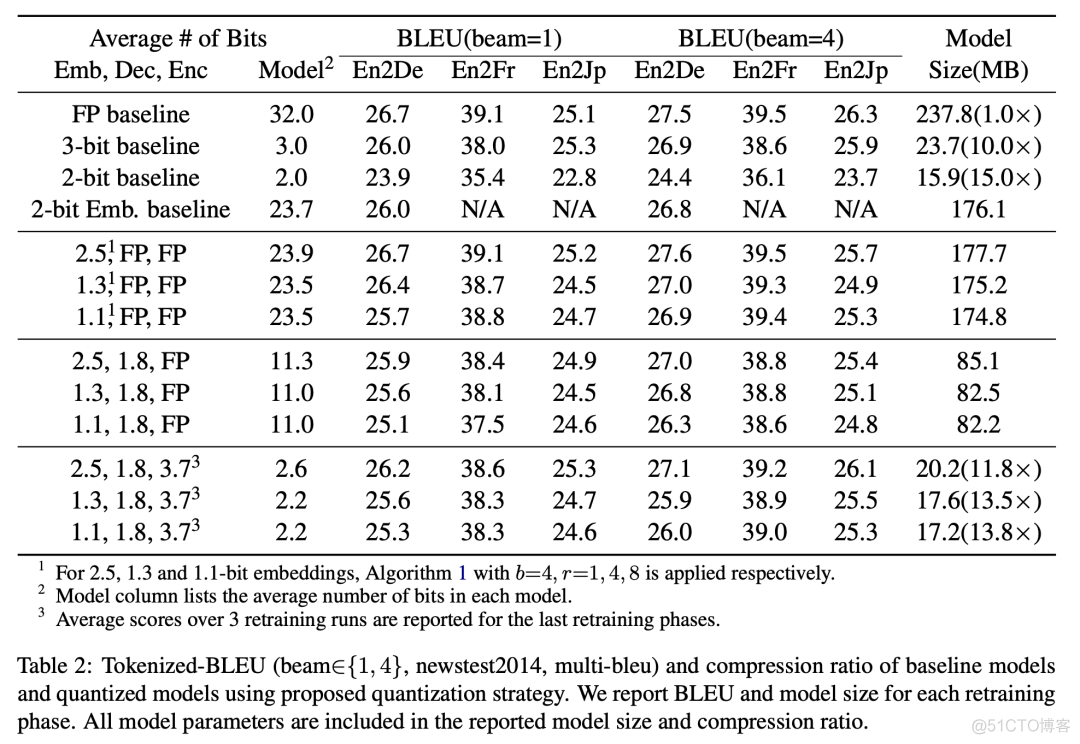
It can be seen that embedding The quantitative impact is still relatively large , Especially quantified to 2 Below the position . And all use 2 Bit quantization is bad . If we use the quantitative method in this paper , You can see that in most configurations , The losses are all in 1 Within a point , The effect is good .
evaluation
This article adopts non-uniform Quantitative way , It's a little more complicated to implement , And in terms of accelerated optimization of matrix multiplication , Not too much about how to achieve . Besides, there is no contrast uniform Quantification and non-uniform The gap in the way of quantification , It's not clear that the performance improvement is non-uniform Quantification dominates , Or according to the frequency and the difference attention Different quantized bits are dominant . Finally, there are too many artificial design factors , such as attention The number of quantized digits has to be determined , It's not very flexible to use .
TernaryBERT: Distillation-aware Ultra-low Bit BERT
This article is made by Huawei Noah Ark laboratory , Published in EMNLP On the Lord's meeting .
「 Address of thesis :」 https://www.aclweb.org/anthology/2020.emnlp-main.37.pdf

Method

As shown in the figure above , Distillation is added to this article on the basis of quantification .
First of all, for weight quantitative , Using ternary quantization , The training method is TWN perhaps LAT, You can see the specific principle of Hou Lu's paper :https://houlu369.github.io/, and activation Or use the general min-max quantitative .
To quantify the parameters ,embedding Each row takes a set of parameters , And everything else weight It's a whole set of parameters .
Distillation uses three loss:hidden state、attention and logits.teacher It's full precision ,student There are two , The first one is full precision , Models and teacher As like as two peas . Then use TWN or LAT Quantize the ternary network , Calculation loss, Finally, back propagation updates the full precision student Parameters of .
There are two more trick, One is data enhancement , The second is full precision student Model initialization is done with finetune After teacher.
experimental result

stay GLUE The experiment on , The maximum compression ratio can reach 23 times , It seems that the effect is better than ordinary Q-BERT、Q8-BERT It's still a lot better , Than BERT It's just bad 1 A p.m. . All of this activation It's only quantified to 8 position , It is estimated that the effect will not be good if we try again .
evaluation
GLUE and SQUAD It looks good on the top , Compression is also very high , But there are a few ways to integrate : Distillation 、 Data to enhance 、 Model initialization, etc , Ablation experiments can also see that the effect is greatly reduced by removing distillation and data enhancement , therefore TWN and LAT Compared with the general min-max It's not clear how much advantage there is in quantifying practice . Finally, this paper does not do machine translation task , It's all about classification tasks , It also works well on more difficult build tasks , It's really persuasive .
summary
Take a comprehensive look at , These three papers use three completely different quantitative methods . It's best to realize ,TensorFlow This is also the way to quantify ,8 Bit effects are almost lossless , But it's not going to work much lower . The last two articles are about ultra-low bit quantization , One uses binary-code, One is TWN or LAT, The compression ratio is very high . In the second part, the quantized digits of different parameters are distinguished according to word frequency or importance , In the case of ultra-low bit can also maintain good results . Direct ultra-low bit quantization , But with a series of operations such as distillation, the performance has been improved , Unfortunately, I didn't do the machine translation task , It makes people suspect .
But in the end, only the third one won the Lord's meeting , Anyway , There is still a lot to learn from .

Author's brief introduction :godweiyang, Know the same name , A master's degree in computer science of East China Normal University , Direction Natural language processing and deep learning . Like to share technology and knowledge with others , Looking forward to further communication with you ~
If you have any questions, you can leave a message in the comments section , Welcome to join us for in-depth communication on wechat ~

边栏推荐
- MySQL table name area in Linux is not case sensitive
- Redison 3.17.5 release, officially recommended redis client
- 【已解决】单点登录成功SSO转发,转发URL中带参数导致报错There was an unexpected error (type=Internal Server Error, status=500)
- 【QT】capture. Obj:-1: error: lnk2019: unresolved external symbols__ imp_ Htons (solution)
- C#winform 窗体事件和委托结合用法
- 【StoneDB Class】入门第一课:数据库知识科普
- 小程序消息推送配置 Token校验失败,请检查确认
- 一段平平无奇的秋招经历
- 反弹shell是什么?反弹shell有什么用?
- Regular and sed exercises
猜你喜欢

Lu Xun: I don't remember saying it, or you can check it yourself!

The integrated real-time HTAP database stonedb, how to replace MySQL and achieve nearly 100 times the improvement of analysis performance

物联网工业级UART串口转WiFi转有线网口转以太网网关WiFi模块选型
![[ten thousand words long article] thoroughly understand load balancing, and have a technical interview with Alibaba Daniel](/img/fc/1ee8b77d675e34da2eb8574592c489.png)
[ten thousand words long article] thoroughly understand load balancing, and have a technical interview with Alibaba Daniel
【Day42 文献精读】A Bayesian Model of Perceived Head-Centered Velocity during Smooth Pursuit Eye Movement
Framework of electronic mass production project -- basic idea

What about idea Chinese garbled code

How to update PIP3? And running PIP as the 'root' user can result in broken permissions and conflicting behavior

How to analyze and locate problems in 60 seconds?

C#winform 窗体事件和委托结合用法
随机推荐
物来顺应,未来不迎,当时不杂,既过不恋
一体化实时HTAP数据库StoneDB,如何替换MySQL并实现近百倍分析性能的提升
Regular and sed exercises
LeetCode56. 合并区间
Abstract factory pattern
API 版本控制【 Eolink 翻译】
【Day42 文献精读】A Bayesian Model of Perceived Head-Centered Velocity during Smooth Pursuit Eye Movement
[resolved] the new version of pychart (2022) connects to the server to upload files and reports an error of "command Rsync is not found in path", and the files cannot be synchronized
抽象工厂模式
Solution to automatic disconnection of SSH link of Tencent ECS
【StoneDB Class】入门第一课:数据库知识科普
Jjwt generate token
Lua迭代器
Demo submit a program and obtain ALV data of the program
Convert objects to key value pairs
增强:BTE流程简介
DEMO:PA30 银行国家码默认CN 增强
Redison 3.17.5 release, officially recommended redis client
RPC remote procedure call
浅谈数据安全