当前位置:网站首页>[0701] [论文阅读] Alleviating Data Imbalance Issue with Perturbed Input During Inference
[0701] [论文阅读] Alleviating Data Imbalance Issue with Perturbed Input During Inference
2022-07-02 17:38:00 【xiongxyowo】
[论文地址] [代码] [MICCAI 21]
Abstract
由于常见疾病和罕见疾病之间的数据不平衡,智能诊断往往偏向于常见疾病。即使在模型训练期间应用了再平衡策略,这种偏见仍然可能存在。为了进一步缓解这种偏见,我们提出了一种新的方法,这种方法不是在训练阶段而是在推理阶段发挥作用。对于任何测试输入数据,基于温度调整后的分类器输出和从不同疾病的反频率中得出的目标概率分布之间的差异,输入数据可以以类似于对抗性学习的方式被轻微扰动。与原始输入相比,对被扰乱的输入的分类器预测将变得不那么偏向常见疾病。所提出的推理阶段方法可以自然地与任何训练阶段的再平衡策略相结合。在三种不同的医学图像分类任务和三种分类器骨干上进行的广泛评估表明,我们的方法能够持续地提高分类器的性能,即使是经过任何再平衡策略的训练。特别是在少数类别上,性能的提高是巨大的,这证实了所提出的方法在缓解分类器对主导类别的偏见方面的有效性。
Method
本文解决的是医学诊断中数据集不均衡的问题,即,罕见病的样本是比较难收集的。具体方法则属于一种基于测试时后处理(Test-Time Postprocessing)的方法,相比于传统的测试前预处理(Training-Time Preprocessing)的方式而言有一定的新颖之处。总体流程如下所示:
考虑数据集一共包含 C C C类训练数据,其中第 c c c类的样本数为 n c n_c nc。如果某一类别 i i i的样本占主导地位,那么对于任意输入样本 x x x,输出的softmax概率 p p p也会倾向于预测为类别 i i i。那么本文的做法也很简单,在测试时对样本进行扰动,使其softmax输出偏向于少数类。
在样本 x x x输入到网络后,可以得到FC层的logit输出向量 z = [ z 1 , z 2 , . . . , z C ] T z = [z_1, z_2,...,z_C]^T z=[z1,z2,...,zC]T。最终的分类概率计算还要通过把这个 z z z给输入到softmax分类器中。对于softmax而言,其有一个温度系数 T T T,正常分类的时候我们是将其设为1的,而在一些任务比如知识蒸馏中,我们会将其设为大于1,从而使得softmax输出更为"平滑"。那么在这里也是一个道理,增大T,使得对于常见类的预测概率压低一些,而不常见类的预测概率提高一些 p ^ c = exp ( z c / T ) ∑ k = 1 C exp ( z k / T ) \hat{p}_{c}=\frac{\exp \left(z_{c} / T\right)}{\sum_{k=1}^{C} \exp \left(z_{k} / T\right)} p^c=∑k=1Cexp(zk/T)exp(zc/T) 当然,仅做到这一步,只能说缩短不同类之间的预测概率差距,并不会直接把"概率第二高的类优化成第一高的类"。而为了实现这一点,本文实现了一个扰动向量: p c ∗ = g ( n c ) ∑ k = 1 C g ( n k ) p_{c}^{*}=\frac{g\left(n_{c}\right)}{\sum_{k=1}^{C} g\left(n_{k}\right)} pc∗=∑k=1Cg(nk)g(nc) 那么这个玩意的思路其实还是很原始的。其中 g ( n c ) = l o g ( M / n c ) g(n_c) = log(M/n_c) g(nc)=log(M/nc),也就是某个类在训练集中出现的频次越高,那么其 g ( n c ) g(n_c) g(nc)就越低。现在,我们将 p c ∗ p_{c}^{*} pc∗视为一种真值,那么可以得到 p c ∗ p_{c}^{*} pc∗与原始预测 p c p_{c} pc的差异。基于这一差异,可以推出相应需要加的噪声: x ~ = x − ε ⋅ sign ( ∇ ℓ ( p ^ , p ∗ ) ) \tilde{\mathbf{x}}=\mathbf{x}-\varepsilon \cdot \operatorname{sign}\left(\nabla \ell\left(\hat{\mathbf{p}}, \mathbf{p}^{*}\right)\right) x~=x−ε⋅sign(∇ℓ(p^,p∗)) 从而在实际测试阶段实现纠偏的效果。
Experiment
在3个带bias的医学数据集Skin7,OCTMNIST,X-ray6上进行了实验。
对比方法包括传统的class-level re-weighting,focal loss以及比较现代化的two-stage deferred re-sampling,margin-based method LDAM。
边栏推荐
- Thoroughly understand the point cloud processing tutorial based on open3d!
- reduce--遍历元素计算 具体的计算公式需要传入 结合BigDecimal
- Slam | how to align timestamps?
- Basic idea of quick sorting (easy to understand + examples) "suggestions collection"
- 彻底搞懂基于Open3D的点云处理教程!
- 【愚公系列】2022年07月 Go教学课程 001-Go语言前提简介
- 什么是云原生?这回终于能搞明白了!
- R语言ggplot2可视化分面图(facet):gganimate包基于transition_time函数创建动态散点图动画(gif)
- R语言dplyr包rowwise函数、mutate函数计算dataframe数据中多个数据列在每行的最大值、并生成行最大值对应的数据列(row maximum)
- SQL training 2
猜你喜欢
Redis (6) -- object and data structure

Ali was wildly asked by the interviewer on three sides. Redis dared not write 'proficient' on his resume anymore
【每日一题】第二天

【每日一题】第一天
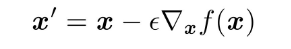
Deep learning mathematics foundation

科技公司不同人对Bug的反应 | 每日趣闻

Leetcode(81)——搜索旋转排序数组 II
文字编辑器 希望有错误的句子用红色标红,文字编辑器用了markdown

Singapore summer tourism strategy: play Singapore Sentosa Island in one day
Have you stepped on the nine common pits in the e-commerce system?
随机推荐
【每日一题】第二天
Stm32g0 USB DFU upgrade verification error -2
昨天阿里学长写了一个责任链模式,竟然出现了无数个bug
Night God simulator +fiddler packet capture test app
Mini Golf Course: a good place for leisure and tourism in London
Mysql高级篇学习总结7:Mysql数据结构-Hash索引、AVL树、B树、B+树的对比
【愚公系列】2022年07月 Go教学课程 001-Go语言前提简介
options should NOT have additional properties
R语言ggplot2可视化分面图(facet):gganimate包基于transition_time函数创建动态散点图动画(gif)
How to write controller layer code gracefully?
Masa framework - DDD design (1)
The difference between promise and observable
快速排序基本思路(通俗易懂+例子)「建议收藏」
After 22 years in office, the father of PowerShell will leave Microsoft: he was demoted by Microsoft for developing PowerShell
Crypto usage in nodejs
The difference between interceptor and filter
StretchDIBits函数
问题包含哪些环节
Eliminate the yellow alarm light on IBM p750 small computer [easy to understand]
医院在线问诊源码 医院视频问诊源码 医院小程序源码