当前位置:网站首页>Hyperparameter Optimization - Excerpt
Hyperparameter Optimization - Excerpt
2022-07-31 06:14:00 【Young_win】
Introduction to Hyperparameter Optimization
When building a deep learning model, you must decide: how many layers should be stacked?How many cells or filters should each layer contain?Should activation use relu or some other function?Should BatchNormalization be used after a certain layer?What dropout ratio should I use?These parameters at the architectural level are called hyperparameters.Correspondingly, model parameters can be trained by backpropagation.
The way to adjust hyperparameters is generally "to formulate a principle to systematically and automatically explore the possible decision space".Search the architecture space and empirically find the best performing architecture.The process of hyperparameter optimization:
1.) Select a set of hyperparameters (automatic selection);
2.) Build the corresponding model;
3.) Fit the model on the training data and measureits final performance on validation data;
4.) choose the next set of hyperparameters to try (automatic selection);
5.) repeat the above process;
6.) finally, measure the model atPerformance on test data.
The key to this process is that, given many sets of hyperparameters, the history of validation performance is used to select the next set of hyperparameters to evaluate of algorithms, such as: Bayesian Optimization, Genetic Algorithms, Simple Random Search, etc.
Hyperparameter optimization v.s. model parameter optimization
Training the model weights is relatively simple, that is, calculating the loss function on a small batch of data, and then using the backpropagation algorithm to make the weights move in the correct direction.
Hyperparameter optimization: (1.) Computing the feedback signal - whether this set of hyperparameters results in a high-performance model on this task - can be very computationally expensive, and it requires creating aNew models and trained from scratch; (2.) The hyperparameter space usually consists of many discrete decisions and thus is neither continuous nor differentiable.Therefore, in general can't do gradient descent in hyperparameter space.Instead, you have to rely on optimization methods that don't use gradients, which are much less efficient than gradient descent.
In general, random search - randomly selecting the hyperparameters to evaluate, and repeating the process - is the best solution.a.) The Python tool library Hyperopt is a hyperparameter optimization tool that internally uses Parzen to estimate its tree to predict which set of hyperparameters may yield good results.b.) The Hyperas library is to integrate Hyperopt with the Keras model.
An important issue to keep in mind when doing large-scale hyperparameter field optimization is validation overfitting.Because you are using the validation data to calculate a signal, and then updating the hyperparameters based on that signal, you are actually training the hyperparameters on the validation data and will soon overfit the validation data.
边栏推荐
- pyspark.ml特征变换模块
- Understanding of objects and functions in js
- Filter out egrep itself when using ps | egrep
- sql add default constraint
- cocos create EditBox 输入文字被刘海屏遮挡修改
- ROS之service编程的学习和理解
- 自定dialog 布局没有居中解决方案
- pytorch学习笔记10——卷积神经网络详解及mnist数据集多分类任务应用
- Fluorescein-PEG-DSPE 磷脂-聚乙二醇-荧光素荧光磷脂PEG衍生物
- Cholesterol-PEG-DBCO 胆固醇-聚乙二醇-二苯基环辛炔化学试剂
猜你喜欢
如何修改数据库密码
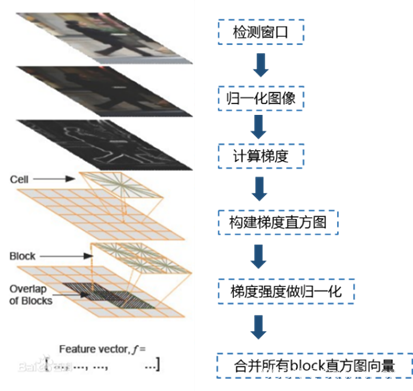
使用 OpenCV 提取图像的 HOG、SURF 及 LBP 特征 (含代码)

Gradle sync failed: Uninitialized object exists on backward branch 142
pytorch模型微调finetuning训练image_dog(kaggle)
Notes on creating a new virtual machine in Hyper-V

np.fliplr与np.flipud

wangeditor富文本编辑器上传图片以及跨域问题解决

Cholesterol-PEG-NHS NHS-PEG-CLS 胆固醇-聚乙二醇-活性酯可修饰小分子材料
Navicat从本地文件中导入sql文件
【解决问题】RuntimeError: The size of tensor a (80) must match the size of tensor b (56) at non-singleton
随机推荐
Cholesterol-PEG-Acid CLS-PEG-COOH 胆固醇-聚乙二醇-羧基修饰肽类化合物
禅道安装及使用教程
Filter out egrep itself when using ps | egrep
Global scope and function scope in js
mysql 事务原理详解
Nmap的下载与安装
pytorch模型微调finetuning训练image_dog(kaggle)
Navicat从本地文件中导入sql文件
Cholesterol-PEG-Amine CLS-PEG-NH2 胆固醇-聚乙二醇-氨基科研用
词向量——demo
unicloud 云开发记录
Embedding前沿了解
Shell/Vim相关list
Sqlite A列数据复制到B列
2022年SQL大厂高频实战面试题(详细解析)
DSPE-PEG-COOH CAS:1403744-37-5 磷脂-聚乙二醇-羧基脂质PEG共轭物
机器学习和深度学习概述
360 加固 file path not exists.
Gradle sync failed: Uninitialized object exists on backward branch 142
The browser looks for events bound or listened to by js