当前位置:网站首页>一文梳理NLP主要模型发展脉络
一文梳理NLP主要模型发展脉络
2022-08-04 12:55:00 【JMXGODLZ】
欢迎大家访问个人博客:https://jmxgodlz.xyz
前言
本文根据笔者所学知识,对NLP主要模型的发展脉络作梳理,目的在于了解主流技术的前世今生,如有理解错误的地方,麻烦指正~
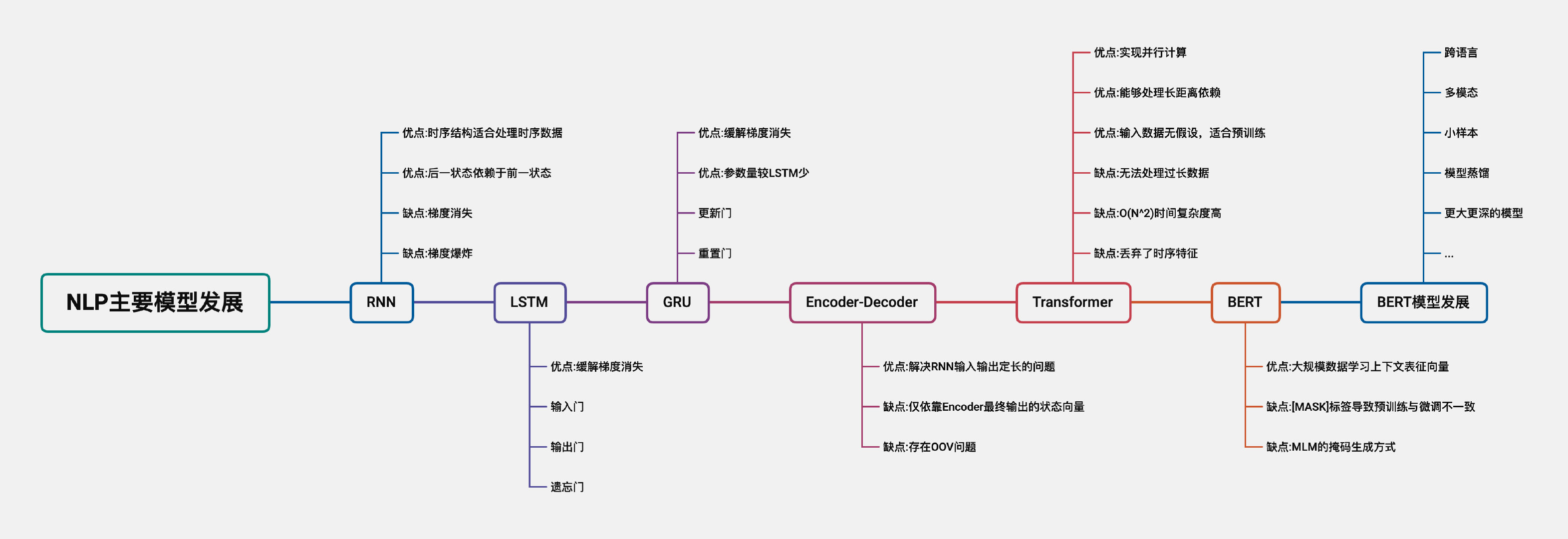
下面将依次介绍RNN、LSTM、GRU、Encoder-Deocder、Transformer、BERT设计的出发点,模型结构不作详细介绍。
RNN
自然语言处理的数据类型多为文本类型,文本数据的上下文关系具有较强的序列特征。同时,RNN模型具有“上一时刻输出作为下一时刻的输入”的特征,该特征能够很好的处理序列数据。因此,RNN模型相较于其他模型,更适合处理自然语言处理任务。
当待处理序列长度较长时,RNN模型在反向传播的过程中,受链式求导法则的影响,当求导过程导数过小或过大时,会导致梯度消失或梯度爆炸。
LSTM
RNN模型的权重矩阵在时间维度上是共享的。LSTM相较于RNN模型,通过引入门控机制,缓解梯度消失,那么LSTM如何避免梯度消失?
这里给出几个关键结论,详细分析后续开一篇介绍。
RNN模型在时间维度共享参数矩阵,因此RNN模型总的梯度等于各时间的梯度之和, g = ∑ g t g=\sum{g_t} g=∑gt。
RNN中总的梯度不会消失,只是远距离梯度消失,梯度被近距离梯度主导,无法捕获远距离特征。
梯度消失的本质:由于RNN模型在时间维度共享参数矩阵,导致针对隐藏状态h求导时,循环计算矩阵乘法,最终梯度上出现了参数矩阵的累乘。
LSTM缓解梯度消失的本质:引入门控机制,将矩阵乘法转为逐元素相乘的哈达马积: c t = f t ⊙ c t − 1 + i t ⊙ tanh ( W c [ h t − 1 , x t ] + b c ) c_{t}=f_{t} \odot c_{t-1}+i_{t} \odot \tanh \left(W_{c}\left[h_{t-1}, x_{t}\right]+b_{c}\right) ct=ft⊙ct−1+it⊙tanh(Wc[ht−1,xt]+bc)
GRU
GRU与LSTM模型相同,引入门控机制,避免梯度消失。区别在于,GRU只用了重置门与更新门两个门结构,参数量较LSTM少,训练速度更快。
Encoder-Decoder
RNN模型“上一时刻输出作为下一时刻的输入”的特征,也存在模型输入输出一直是等长的问题。Encoder-Decoder模型通过编码器与解码器两个部分,解决了输入输出定长的问题。其中Encoder端负责文本序列的特征表示获取,Decoder端根据特征向量解码输出序列。
但Encoder-Decoder模型仍然存在以下问题:
文本序列的特征表示向量选取
特征表示向量包含特征的有限性
OOV问题
第一个与第二个问题通过注意力机制解决,利用注意力机制有选择的关注文本序列重要的特征。
第三个问题则通过拷贝机制以及Subword编码解决。
Transformer
Transformer模型主要包含多头自注意力模块、前馈神经网络、残差结构与Dropout,其中核心模块为多头自注意力模块,各组件的功能如下:
自注意力机制在编码器端有选择的关注文本序列重要的特征,解决文本序列的特征表示向量选取及该向量包含特征的有限性问题。
多头机制中每一头映射到不同空间,得到不同侧重点的特征表示,使得特征表示的更充分。
残差结构有效避免梯度消失。
Dropout有效避免过拟合。
前馈神经网络完成隐含层到输出空间的映射
接下来将重点介绍Transformer模型的优点。
1. Transformer能够实现长距离依赖
在自注意力机制中,每个字符能够与其他所有字符计算注意力得分。这种计算方式未考虑时序特征,能够捕获长距离依赖。
但该方式缺点在于,注意力得分计算的时间复杂度为 O ( n 2 ) O(n^2) O(n2),当输入序列较长时,时间复杂度过高,因此不适合处理过长数据。
2. Transformer能够实现并行化
假设输入序列为(a,b,c,d)
传统RNN需要计算a的embedding向量得到 e a e_a ea,再经过特征抽取得到 h a h_a ha,然后以相同方式计算b,c,d。
Transformer通过self-attention机制,每个词都可以与全部序列交互,应此模型可以同时处理整个序列,得到 e a , e b , e c , e d e_a,e_b,e_c,e_d ea,eb,ec,ed,然后再一起计算 h a , h b , h c , h d h_a,h_b,h_c,h_d ha,hb,hc,hd。
3. Transformer适合预训练
RNN模型作出输入数据具有时序性的假设,将前一时刻的输出作为下一时刻的输入。
CNN模型基于输入数据为图像的假设,在结构中加入一些特质【如卷积生成特征】,使前向传播更加高效,降低网络的参数量。
与CNN、RNN模型不同, Transformer 模型是一种灵活的架构,对输入数据的结构无限制,因此适合在大规模数据上进行预训练,但该点也带来了Transformer模型在小规模数据集上泛化性差的问题。改进方法包括引入结构偏差或正则化,对大规模未标记数据进行预训练等。
BERT
模型结构
首先,BERT模型参照GPT模型,采样预训练-微调两阶段的训练方式。但是,与GPT使用Transformer解码器部分不同,BERT为了充分利用上下文信息,使用Transformer编码器部分作为模型结构。
训练任务
如果BERT与GPT同样使用语言模型作为学习任务,则模型存在标签泄露的问题【一个词的上下文包含了另一个词的预测目标】。因此为了利用上下文信息,BERT提出MLM掩码语言模型任务,通过上下文预测遮盖词,MLM有关介绍可见-不要停止预训练实战(二)-一日看尽MLM。
改进点
针对Transformer结构及预训练方式,BERT模型仍存在以下改进点:
训练方式:针对掩码方式与多任务训练方式进行改进,调整NSP训练任务与掩码的方式
模型结构调整:针对Transformer O ( n 2 ) O(n^2) O(n2)的时间复杂度以及输入结构无假设的两点,调整模型结构
架构调整:轻量化结构、加强跨块连接、自适应计算时间、分治策略的Transformer
预训练:使用完整Encoder模型,如T5,BART模型
多模态等下游任务应用
BERT模型未来发展方向主要包含:更大更深的模型、多模态、跨语言、小样本、模型蒸馏,有关讨论可见-2022预训练的下一步是什么
参考文献
https://arxiv.org/pdf/2106.04554.pdf
https://www.zhihu.com/question/34878706
边栏推荐
- 两年独立开发经验程序员告诉我们赚钱的经验(听听真正赚到钱的高手做法)
- 【PHP实现微信公众平台开发—基础篇】第1章 课程介绍
- A comprehensive understanding of MOS tubes, an article is enough
- postgre 支持 newsql 特性可行性有多大?
- ES 节点2G内存分析
- RobotFramework二次开发(一)
- Cool and efficient data visualization big screen, it's really not that difficult to do!丨Geek Planet
- String is a reference type
- 小程序对接企业微信客服
- Access Huawei game anti-addiction, click the anti-addiction pop-up window, the game crashes
猜你喜欢





随机推荐
跨链桥已成行业最大安全隐患 为什么和怎么办
A discussion of integrated circuits
MFC的相机双目标定界面设计
MATLAB——图像分块
【WeChat Mini Program】Social Internship Production Project for Information Management and Information System Major--Trash Fingerprint
用VbScript控制光驱
“蔚来杯“2022牛客暑期多校训练营2 G、J、K
leetcode 48. Rotate Image 旋转图像(Medium)
搭建ros交叉编译环境(从x86到nvidia arm)
Just a Hook
SSRF-服务器端请求伪造-相关知识
集群监控——Zabbix
Flutter教程大全合集(2022年版)
密码设置十准则
Small program on how to play in the construction of e-government service platform value
情人节浪漫3D照片墙【附源码】
【Game Of AutoTest】1、再度启程,重识游戏自动化测试
1314元的七夕礼盒,收割了多少直男?
持续交付(三)Jenkinsfile语法使用介绍
Cows 树状数组