当前位置:网站首页>Introduction to neural network (Part 1)
Introduction to neural network (Part 1)
2022-06-30 20:10:00 【Uncertainty!!】
Introduction to neural networks
Introduction to neural networks ( On )
Note source :Neural Networks Demystified
Statement : I am Xiaobai , First time to learn relevant knowledge , This is a study note , If there is a mistake , Please correct me !
Let's make a simple prediction , By the sleep time before the exam (Hours sleep) And pre exam study time (Hours study) To predict test scores (Score on test)
Just a demonstration. , Only three sets of sample values are given
Sleep time before exam (Hours sleep) And pre exam study time (Hours study) Composition matrix X X X
Test scores (Score on test) Composition matrix Y Y Y

1.1 Building neural network
Import library  Import sample data
Import sample data 
 We scale the input sample data to 0 To 1 Between
We scale the input sample data to 0 To 1 Between  The general form of neural network
The general form of neural network 

Number of neurons in input layer :2
Number of neurons in the output layer :1
The number of neurons in the hidden layer :3
The weight matrix between the input layer and the hidden layer W1( Generated from random numbers , Normal distribution may be used )
Weight matrix between hidden layer and output layer W2( Generated from random numbers , Normal distribution may be used )
1.1.1 Forward propagation (Forward Propagation)
First, put the sample data into the input layer row by row , Here's the picture , First, the first number in the first row of the sample data 3 Put the neurons above the input layer , And then 3 Multiply them separately 3 Weight , Put the three results into the hidden layer , Then the second number in the first row of the sample data 5 Put the neurons under the input layer , And then 5 Multiply them separately 3 Weight , Put the three results into the hidden layer , Add this result to the previous result

The process described above , In fact, it is a matrix composed of sample data X X X And weight matrix W ( 1 ) W^{(1)} W(1) ( Represents the matrix formed by the weight of the first layer ) The result of dot multiplication

The above matrix Z ( 2 ) Z^{(2)} Z(2) Each line in is used as Sigmoid Input to function , That is, the input of the hidden layer , after Sigmoid The calculated result is used as the output of the hidden layer


Multiply the output of each neuron in the hidden layer by each weight , Then add as input to the output layer , It is also the output of the output layer


Forward propagation :
Input value matrix X And weight matrix W1 Point multiplication
Send the dot product result to Sigmoid Handle , The processing results are output as hidden layers
The output of the hidden layer and the weight matrix W2 Point multiplication , The processing result is used as the input of the output layer , That is, the output of the output layer
Assign the output of the output layer to y ^ \hat{y} y^ As the initial value of the estimate
Feed this estimate into the least squares , Get the minimum value by calculation , That's the minimum error , We have completed the purpose of training neural network
| Parameters | meaning |
|---|---|
| X | Input vector |
| W ( 1 ) W^{(1)} W(1) | The weight matrix between the input layer and the hidden layer W1 |
| Z ( 2 ) Z^{(2)} Z(2) | Hidden layer input |
| f | Sigmoid Activation function |
| a ( 2 ) a^{(2)} a(2) | Hidden layer output vector |
| W ( 2 ) W^{(2)} W(2) | Weight matrix between hidden layer and output layer W2 |
| y ^ \hat{y} y^ | An estimate or forecast |
It gets y ^ \hat{y} y^ It is just an initial prediction value obtained by sending random numbers into the neural network , Next, in order to make the prediction more accurate , The neural network needs to be trained 

1.1.2 gradient descent (Gradient Descent) and Back propagation (Back Propagation)
Backpropagation and Gradient Descent are two different methods that form a powerful combination in the learning process of neural networks.Backpropagation and gradient descent work together to help a neural network learn.
The nature of training neural networks :Minimizing a Cost Function
There must be an error between the real value and the predicted value , We construct a function by calculating the mean square deviation between the real value and the predicted value , Then the gradient descent method , Find the minimum value of the function , The best fitting of known samples has been achieved
Then let's take a look at how to train the neural network in this example , That is, how to minimize the cost function

Our goal is to continuously adjust the weights through training , A set of weights is found to minimize the overall error

Let's start with one of the weight matrices W1 Try , The matrix W1 Assign various values , Look at the cost function costs Will there be a minimum in the end

Obviously, the above method belongs to brute force , If the 3 Try a weight matrix , Then the running time will be terrible ! We start to look at the cost function , Start with the cost function , Find the way to reduce the cost function by deriving the cost function


If the cost function is a nonconvex function in the following figure , How can we prevent falling into local optimization ? This problem will be studied later , But be clear that what we need is global optimization , Not locally optimal


Define the cost function (Cost Function)




 By the law of derivative , Will add and propose , Derivation before addition does not affect the result
By the law of derivative , Will add and propose , Derivation before addition does not affect the result 
Because the derivative of the sum is equal to the sum of the derivatives , So let's not consider addition for the time being , Apply the chain rule to derive
A better name for back propagation might be : Never stop implementing the chain rule



 take y ^ = f ( z ( 3 ) ) \hat{y}=f(z^{(3)}) y^=f(z(3)) Put in the above formula
take y ^ = f ( z ( 3 ) ) \hat{y}=f(z^{(3)}) y^=f(z(3)) Put in the above formula
 Because of the f by Sigmoid, So we need to deal with Sigmoid Derivation
Because of the f by Sigmoid, So we need to deal with Sigmoid Derivation

Definition Sigmoid The derivative of (Sigmoid Prime)



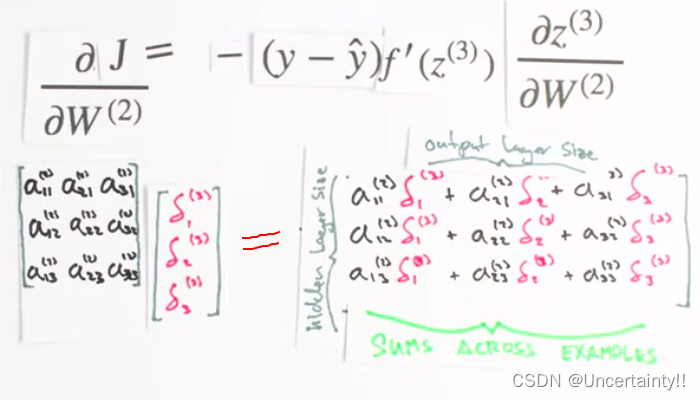
 δ ( 3 ) \delta^{(3)} δ(3) Is the back propagation error
δ ( 3 ) \delta^{(3)} δ(3) Is the back propagation error

Let's sort out the above derivation process 
About J J J For the weight matrix W1 Partial derivative of , The treatment is similar to


Calculated after operation
∂ J ∂ W ( 1 ) and ∂ J ∂ W ( 2 ) \frac{\partial J}{\partial W^{(1)}}\ \text{and}\ \frac{\partial J}{\partial W^{(2)}} ∂W(1)∂J and ∂W(2)∂J
 If you will W1 Plus a scalar times dJW1, We will find that our costs will increase
If you will W1 Plus a scalar times dJW1, We will find that our costs will increase
(W1 Plus a scalar times dJW1 It seems that it means to rise several gradients on the original basis )
 If you will W1 Subtract a scalar times dJW1, We will find that our costs will be reduced
If you will W1 Subtract a scalar times dJW1, We will find that our costs will be reduced
(W1 Subtract a scalar times dJW1 It seems that it means to drop several gradients on the original basis )
 This is also the core of gradient descent !
This is also the core of gradient descent !
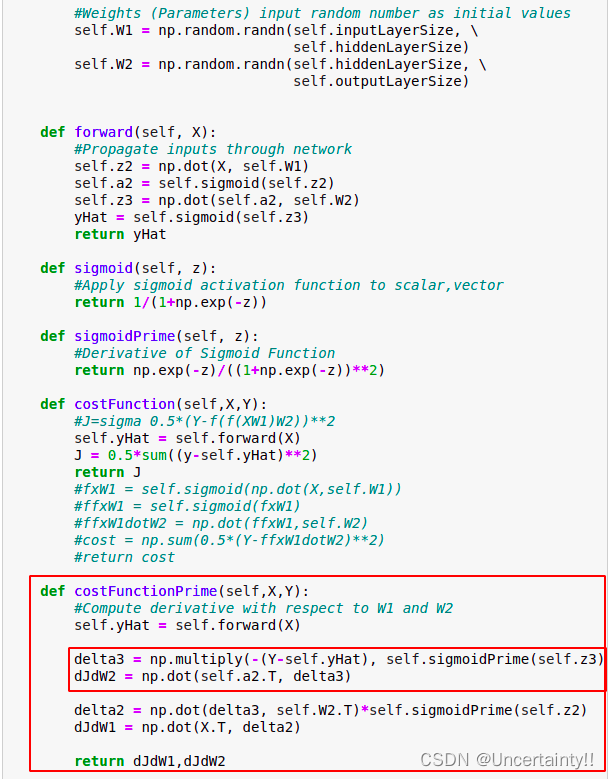
Back propagation (Back Propagation Checking)
In fitting a neural network, backpropagation computes the gradient of the loss function with respect to the weights of the network for a single input–output example, and does so efficiently, unlike a naive direct computation of the gradient with respect to each weight individually
The backpropagation algorithm works by computing the gradient of the loss function with respect to each weight by the chain rule, computing the gradient one layer at a time, iterating backward from the last layer to avoid redundant calculations of intermediate terms in the chain rule
Backpropagation is an algorithm used in machine learning that works by calculating the gradient of the loss function, which points us in the direction of the value that minimizes the loss function. It relies on the chain rule of calculus to calculate the gradient backward through the layers of a neural network. Using gradient descent, we can iteratively move closer to the minimum value by taking small steps in the direction given by the gradient.
The error is back propagated to each weight 
1.1.3 Numerical gradient test (Numerical Gradient Checking)
There is no good way for neural networks to find their own problems , So we need to test , So that the performance of the neural network will gradually decline over time
If the result of the test is similar to that of the neural network , That proves that the neural network has good performance
Take an example to briefly understand the basic principle of inspection
One is to calculate by derivation formula
One is the formula defined by the derivative , Make your own decision ϵ \epsilon ϵ Substitute the formula defined by the derivative to calculate
The result calculated by the derivative definition formula is used to verify the result calculated by the derivation formula  Add a perturbation term to each weight e(perturb) , And calculate the value of the cost function after adding the disturbance term
Add a perturbation term to each weight e(perturb) , And calculate the value of the cost function after adding the disturbance term
Subtract a disturbance term from each weight e(perturb) , And calculate the value of the cost function after subtracting the disturbance term
Then calculate the slope between the two values , Repeat this process for ownership revaluation , After completion , We get a numerical gradient vector , The values in this vector , Same as the corresponding weights


NumericalGradient Is the result calculated by adding a disturbance term
computerGradient It is the result of direct calculation through derivation formula
It is found that there is not much difference between the two , Finally, we use norms to quantify the similarity between the two results 
1.2 Training neural network
We use gradient descent to train neural networks
The problem of gradient descent : Fall into local optimum 、 Unable to find optimal value 、 Approaching the optimal value is too slow 、 Skip the optimal value, etc . Most of the practical problems are high-dimensional cases

In order to solve the above problems , We need numerical optimization

We use BFGS Algorithm optimization , And assign the optimization result to _res

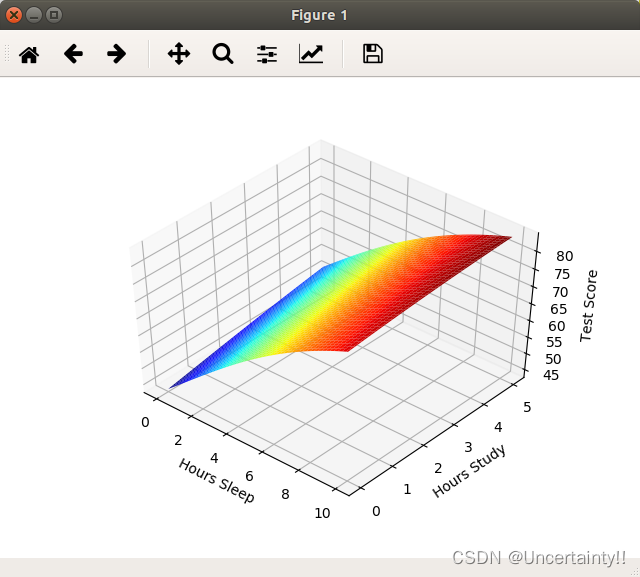
1.3 Testing neural networks
Training done , We can now input the original sample data for retesting 





边栏推荐
- 8 - function
- 启动PHP报错ERROR: [pool www] cannot get uid for user ‘@[email protected]’
- 2022 最新 JCR正式发布全球最新影响因子名单(前600名)
- Go language learning tutorial (13)
- 广州股票开户选择手机办理安全吗?
- Taihu Lake "China's healthy agricultural products · mobile phone live broadcast" enters Taihu Lake
- pytorch实现FLOPs和Params的计算
- Client请求外部接口标准处理方式
- [ICLR 2021] semi supervised object detection: unbiased teacher for semi supervised object detection
- Conditional compilation
猜你喜欢

【Try to Hack】Windows系统账户安全

微信小程序开发实战 云音乐

The prospectus of pelt medical was "invalid" for the second time in the Hong Kong stock exchange, and the listing plan was substantially delayed

mysql主从同步

《微信小程序-基础篇》带你了解小程序中的生命周期(二)

线下门店为什么要做新零售?

Kubernetes为什么会赢,容器圈的风云变幻!

建立自己的网站(20)

项目经理是领导吗?可以批评指责成员吗?

数据智能——DTCC2022!中国数据库技术大会即将开幕
随机推荐
25:第三章:开发通行证服务:8:【注册/登录】接口:接收并校验“手机号和验证码”参数;(重点需要知道【利用redis来暂存数据,获取数据的】的应用场景)(使用到了【@Valid注解】参数校验)
广州股票开户选择手机办理安全吗?
arthas调试 确定问题工具包
Why must we move from Devops to bizdevops?
计网 | 【五 传输层、六 应用层】知识点及例题
discuz 论坛提速之删除data/log下的xxx.php文件
Kubevela 1.4: make application delivery safer, easier to use, and more transparent
广州炒股开户选择手机办理安全吗?
TorchDrug--药物属性预测
盘点华为云GaussDB(for Redis)六大秒级能力
项目经理是领导吗?可以批评指责成员吗?
What is the difference between tolocal8bit and toutf8() in QT
How unity pulls one of multiple components
mysql统计账单信息(上):mysql安装及客户端DBeaver连接使用
毕业季职场人
新出生的机器狗,打滚1小时后自己掌握走路,吴恩达开山大弟子最新成果
Spark - 一文搞懂 Partitioner
6-1漏洞利用-FTP漏洞利用
项目经理不应该犯的错误
CADD课程学习(1)-- 药物设计基础知识