当前位置:网站首页>Flume interview questions
Flume interview questions
2022-07-01 22:23:00 【L fou God】
1. How do you do that Flume Monitoring of data transmission
Using a third party framework Ganglia Real-time monitoring Flume.
2. Flume Of Source,Sink,Channel The role of ? You Source What type is it ?
1. effect
(1)Source Components are designed to collect data , Can handle all kinds of 、 Log data in various formats , Include avro、thrift、exec、jms、spoolingdirectory、netcat、sequence generator、syslog、http、legacy
(2)Channel Component to cache the collected data , It can be stored in Memory or File in .
(3)Sink A component is a component used to send data to a destination , Destinations include HDFS、Logger、avro、thrift、ipc、file、Hbase、solr、 Customize .
2. Our company adopts Source The type is
(1) Monitor background logs :exec
(2) Monitor the port of log generation in the background :netcat
Exec spooldir
3. Flume Of Channel Selectors
ChannelSelectors, You can let different project logs pass through different Channel To different Sink In the middle . On the official file ChannelSelectors There are two types of :ReplicatingChannel Selector (default) and MultiplexingChannel Selector
These two kinds of Selector Is the difference between the :Replicating Will source Over here events To all channel, and Multiplexing You can choose which to send Channel.
4. Flume Parameter adjustment optimal
1. Source
increase Source individual ( Use Tair Dir Source It can be increased at the same time FileGroups Number ) Can increase Source The ability to read data . for example : When a directory produces too many files, you need to split the file directory into multiple file directories , Configure many at the same time Source In order to make sure Source Have enough ability to get new data .
batchSize Parameter determination Source One batch transportation to Channel Of event Number of pieces , Properly increasing this parameter can improve Source Carry Event To Channel Time performance .
2. Channel
type choice memory when Channel The best performance , But if Flume If the process is accidentally hung up, data may be lost .type choice file when Channel Better fault tolerance , But the performance will be better than memory channel Bad . Use file Channel when dataDirs Configuring multiple directories on different disks can improve performance .
Capacity Parameter determination Channel Can hold the largest event Number of pieces .transactionCapacity Parameters determine every time Source Go to channel It's the biggest one event The number and each time Sink from channel It's the biggest read event Number of pieces .transactionCapacity Need greater than Source and Sink Of batchSize Parameters .
3. Sink
increase Sink The number of can be increased Sink consumption event The ability of .Sink It's not as good as more , Too much Sink Will take up system resources , Cause unnecessary waste of system resources .
batchSize Parameter determination Sink Batch from Channel Read the event Number of pieces , Properly increasing this parameter can improve Sink from Channel Move out event Performance of .
5. Flume Transaction mechanism of
Flume Transaction mechanism of ( Transaction mechanism similar to database ):Flume Use two separate transactions that are responsible for the following Soucrce To Channel, And from Channel To Sink Event delivery of . such as spooling directory source Create an event for each line of the file , Once all the events in the transaction are passed to Channel And submitted successfully , that Soucrce Mark the file as complete . Empathy , Transactions are handled in a similar way from Channel To Sink Transfer process , If for some reason the event cannot be recorded , Then the transaction will roll back . And all the events will remain until Channel in , Waiting to be retransmitted .
6. Flume Will the collected data be lost ?
according to Flume Architecture principle of ,Flume It's impossible to lose data , It has a perfect internal transaction mechanism ,Source To Channel It's transactional ,Channel To Sink It's transactional , Therefore, there will be no data loss in these two links , The only possible loss of data is Channel use memoryChannel,agent Data loss due to downtime , perhaps Channel The storage is full , Lead to Source No more writing , Data not written is lost .
Flume No loss of data , But it may cause data duplication , For example, the data has been successfully generated by Sink issue , But no response was received ,Sink The data will be sent again , This may cause data duplication .
7. Flume Infrastructure (*)

(1)Agent
Agent It's a JVM process , It sends data from source to destination in the form of events .
Agent There are mainly 3 Component composition ,Source、Channel、Sink.
(2)Source
Source Is responsible for receiving data to Flume Agent The components of .Source Components can handle various types 、 Log data in various formats , Include avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy.
(3)Sink
Sink Keep polling Channel And remove them in batches , These events are written in bulk to a storage or indexing system 、 Or it could be sent to another Flume Agent.
Sink Component destinations include hdfs、logger、avro、thrift、ipc、file、HBase、solr、 Customize .
(4)Channel
Channel It's located in Source and Sink Buffer between . therefore ,Channel allow Source and Sink It operates at different rates .Channel It's thread safe , You can do several at once Source Write operations and a few Sink Read operation of .
Flume Take two Channel:Memory Channel and File Channel as well as Kafka Channel.
Memory Channel It's an in-memory queue .Memory Channel This works in situations where you don't need to worry about data loss . If you need to worry about data loss , that Memory Channel It shouldn't be used , Because the program died 、 Data is lost when a machine goes down or restarts .
File Channel Write all events to disk . So you don't lose data in the event of a program shutting down or a machine going down .
(5)Event
The transmission unit ,Flume The basic unit of data transmission , With Event Send data from the source to the destination in the form of .
Event from Header and Body Two parts ,Header Used to store the event Some properties of , by K-V structure ,Body It is used to store the data , In the form of an array of bytes .
8. Flume Business (*)

Put Transaction flow
•doPut: Write the batch data to the temporary buffer first putList
•doCommit: Check channel Whether the memory queue is enough to merge .
•doRollback:channel Out of memory queue space , Undo Data
Take Business
•doTake: Take the data to the temporary buffer takeList, And send the data to HDFS
•doCommit: If all the data is sent successfully , Then clear the temporary buffer takeList
•doRollback: If there is an exception in the process of data transmission ,rollback Set the temporary buffer t akeList The data in is returned to channel Memory queue .
9. Flume Agent internals (*)

Important components :
1)ChannelSelector
ChannelSelector The purpose of this is to select Event Which one will be sent to Channel. There are two types of them , Namely Replicating( Copy ) and Multiplexing( Multiplexing ).
ReplicatingSelector Will be the same Event To all Channel,Multiplexing According to the corresponding principles , Will be different Event To different Channel.
2)SinkProcessor
SinkProcessor There are three types , Namely DefaultSinkProcessor
、LoadBalancingSinkProcessor and FailoverSinkProcessor .
DefaultSinkProcessor The corresponding is a single Sink , LoadBalancingSinkProcessor and FailoverSinkProcessor The corresponding is Sink Group,LoadBalancingSinkProcessor It can realize the function of load balancing ,FailoverSinkProcessor Can realize the function of fail over .
10. Flume And Kafka Selection of ?
The acquisition layer can mainly use Flume、Kafka Two kinds of technology .Flume:Flume It's pipe flow , There are a lot of default implementations , Let users deploy through parameters , And expansion API.
Kafka:Kafka It's a persistent distributed message queue .Kafka It's a very versatile system . You can have many producers and many consumers sharing multiple themes Topics. by comparison ,Flume It's a special tool designed to HDFS,HBase send data . It's right HDFS There are special optimizations , And integrated Hadoop Safety features of . therefore ,Cloudera It is suggested that if data is consumed by multiple systems , Use kafka; If the data is designed for Hadoop Use , Use Flume. As you know Flume Built in a lot of source and sink Components . However ,Kafka There is obviously a smaller production consumer ecosystem , also Kafka Our community support is not good . I hope this situation will be improved in the future , But at the moment : Use Kafka It means you're ready to write your own producer and consumer code . If it already exists Flume Sources and Sinks Meet your needs , And you prefer systems that don't need any development , Please use Flume.Flume You can use interceptors to process data in real time . These are useful for data masking or overuse .Kafka You need an external stream processing system to do it .
Kafka and Flume They're all reliable systems , Zero data loss can be guaranteed by proper configuration . However ,Flume Replica events are not supported . therefore , If Flume One of the agent's nodes crashed , Even with a reliable file pipeline , You will also lose these events until you recover these disks . If you need a highly reliable pipeline , So use Kafka It's a better choice .
Flume and Kafka It's a good combination . If your design needs to start from Kafka To Hadoop Streaming data , Use Flume Proxy and configure Kafka Of Source It's also possible to read data : You don't have to be your own consumer . You can use it directly Flume And HDFS And HBase All the benefits of this combination . You can use ClouderaManager Monitoring of consumers , And you can even add interceptors for some stream processing .
边栏推荐
- MySQL series transaction log redo log learning notes
- 编程英语生词笔记本
- Manually implement function isinstanceof (child, parent)
- [STM32] stm32cubemx tutorial II - basic use (new projects light up LED lights)
- Pytest Collection (2) - mode de fonctionnement pytest
- 股票手机开户哪个app好,安全性较高的
- Count the number of each character in the character
- Case of camera opening by tour
- 【直播回顾】战码先锋首期8节直播完美落幕,下期敬请期待!
- AirServer手机第三方投屏电脑软件
猜你喜欢

编程英语生词笔记本

Training on the device with MIT | 256Kb memory

【直播回顾】战码先锋首期8节直播完美落幕,下期敬请期待!
手动实现function isInstanceOf(child,Parent)
pytest合集(2)— pytest運行方式
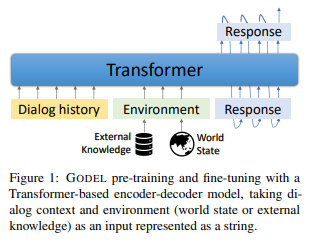
Microsoft, Columbia University | Godel: large scale pre training of goal oriented dialogue

基于LSTM模型实现新闻分类

从MLPerf谈起:如何引领AI加速器的下一波浪潮
js如何获取集合对象中某元素列表

按照功能对Boost库进行分类
随机推荐
Introduction à l'ingénierie logicielle (sixième édition) notes d'examen de Zhang haifan
最近公共祖先(LCA)在线做法
基于K-means的用户画像聚类模型
js数组拼接的四种方法[通俗易懂]
I received a letter from CTO inviting me to interview machine learning engineer
100年仅6款产品获批,疫苗竞争背后的“佐剂”江湖
CNN convolution neural network principle explanation + image recognition application (with source code) [easy to understand]
require与import的区别和使用
“丝路正青春 风采看福建”在闽外籍青年短视频大赛火热征集作品中
中通笔试题:翻转字符串,例如abcd打印出dcba
List announced | outstanding intellectual property service team in China in 2021
微信小程序,连续播放多段视频。合成一个视频的样子,自定义视频进度条
杰理之、产线装配环节【篇】
从MLPerf谈起:如何引领AI加速器的下一波浪潮
[STM32] stm32cubemx tutorial II - basic use (new projects light up LED lights)
pytest合集(2)— pytest運行方式
基于三维GIS的不动产管理应用
Basic operation of binary tree
企业架构与项目管理的关联和区别
A debugging to understand the slot mechanism of redis cluster