当前位置:网站首页>一文吃透哈希表
一文吃透哈希表
2022-07-31 12:08:00 【如风暖阳】


️前言️
博客主页:【如风暖阳】
精品Java专栏【JavaSE】、【备战蓝桥】、【JavaEE初阶】、【MySQL】、【数据结构】
欢迎点赞收藏留言评论私信必回哟本文由 【如风暖阳】 原创,首发于 CSDN
博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言


哈希表
1.什么是哈希表
- 线性表、树
在这些结构中,记录在结构中的相对位置是随机的,和记录的关键字之间不存在确定关系,因此,在结构中查找时需要进行一系列和关键字的比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( l o g 2 N log_2N log2N),搜索的效率取决于搜索过程中元素的比较次数。
- 哈希表
理想的情况下:可以不经过任何比较,一次直接从表中得到要搜索的元素。
哈希表就是通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
在向该结构中插入元素时,通过函数可以计算出该元素的存储位置;同样地,在搜索该元素时,对元素的关键码进行同样的函数计算,就又可以找到该元素。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(HashTable)(或者称散列表)
eg:
数据集合:{1,3,5,7,9}
哈希函数设置为:hash(key) = key % capacity capacity为存储元素底层空间总的大小。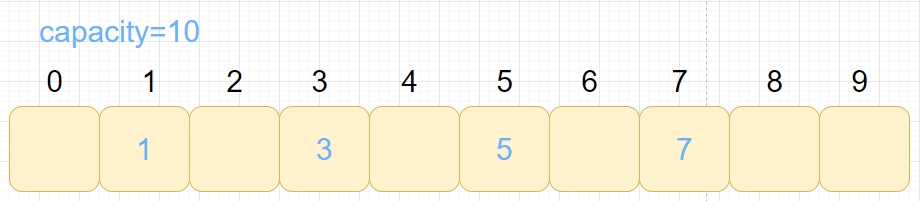
2.哈希冲突
不同关键字通过相同哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
比如在1中的例子中,如果在数据集合中添加一个数“13”,那么它通过哈希函数计算出来的位置与元素“3”位置相同,这种情况就叫做哈希冲突。
3.解决冲突
由于我们哈希表底层数组的容量往往是小于实际要存储的关键字的数量的,这就导致一个问题,冲突的发生是必然的,但我们能做的应该是尽量的降低冲突率,下边有几种方式来尽量解决冲突。
3.1 哈希函数设计
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
下边我们介绍两种常见的函数设计方法:
1.直接定制法:
取关键字的某个线性函数为散列地址:Hash(Key)=A*Key+B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
2.除留取余法:
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:
Hash(Key)=Key%p(p<=m),将关键码转换成哈希地址
3.2 负载因子调节
负载因子的定义为:α=填入表中元素的个数/表的容量
负载因子和冲突率的关系粗略演示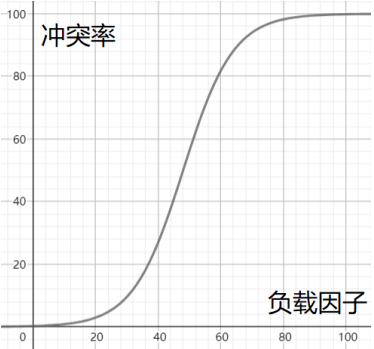
也就是说随着元素的填入,负载因子增大,冲突率也会增大。
为了降低冲突率,只能降低负载因子,但是要填入的元素的个数不能少,所以只能扩大容量
解决哈希冲突的两种常用方法是闭散列和开散列。
3.3 解决方法——闭散列
闭散列也叫做开放地址法,就是在发生哈希冲突时,如果哈希表还没有被装满,Key就可以被存放到冲突位置的“下一个”空位置处。寻找“下一个”空位置的方法有以下两种:
1.线性探测法
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。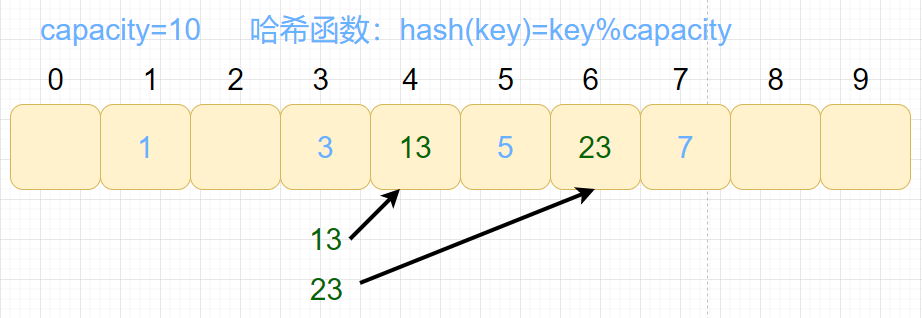
弊端:
- 这种方法会把可能冲突的元素都放在一起
- 删除影响大:假如删除了3这个元素,会影响到13、23等冲突的元素
2.二次探测法
H i H_i Hi=( H 0 H_0 H0+ i 2 i^2 i2)%capacity
H0为冲突位置,Hi为第i个冲突元素的位置,i为冲突的次数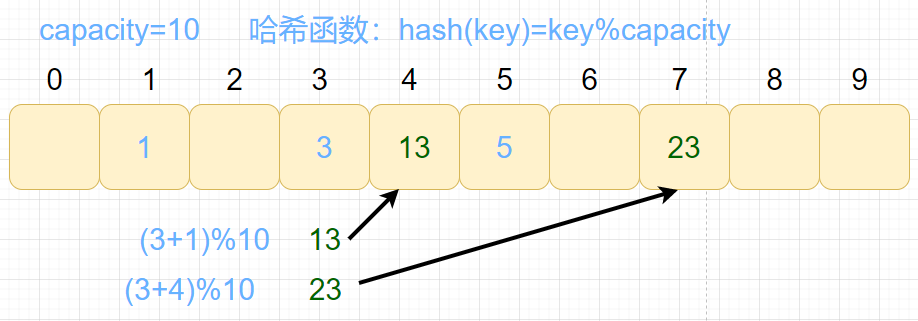
闭散列在负载因子超过0.5时就必须要考虑扩容,所以导致其空间利用率比较低。
3.4 解决方法——开散列/哈希桶(重点掌握)
开散列法又叫做链地址法(开链法),将具有相同哈希地址的元素(或记录)存储在同一个线性链表(桶)中,各链表的头结点存储在哈希表中。(注:当桶中元素较多时,线性链表结构就会变为树形结构——红黑树)
由上图可得,开散列的每个桶中都是发生哈希冲突的元素
开散列可以认为是把在大集合中搜索转换为在小集合中搜索了。
4.代码实现
哈希表结构的实现:
public class HashBuck {
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
public Node[] array;//节点数组 用于存储各链表的头结点
public int usedSize;//记录当前哈希桶中有效数据的个数
//默认的负载因子
public static final float DEFAULT_LOAD_FACTOR=0.75F;
public HashBuck() {
this.array=new Node[10];
this.usedSize=0;
}
}
哈希表方法实现:
put方法:
/** * 存储key val * @param key * @param val */
public void put(int key,int val) {
Node node=new Node(key, val);
int index=key%array.length;
Node cur=array[index];
//先判断桶中是否有相同的关键字,如果有完成value的替换
while (cur!=null) {
if(cur.key==key) {
cur.val=val;
return;
}
cur=cur.next;
}
//头插法完成节点的插入
node.next=array[index];
array[index]=node;
usedSize++;
}
该方法尚未完全完成,还需要考虑增容问题,在哈希表中判断是否需要增容,由负载因子决定。
负载因子的求法:
private float loadFactor() {
return usedSize*1.0f/array.length;
}
哈希表的增容并不像数组增容那样简单,由于每个节点都是通过哈希函数来确定位置的,而哈希函数与容量有关,所以在完成增容后,哈希表中的每一个节点都需要重新进行哈希,获取新的位置。
增容方法:
private void grow() {
Node[] newArray=new Node[2*array.length];
//遍历原哈希表中的每一个哈希桶,让每个节点都重新哈希
for (int i = 0; i < array.length; i++) {
Node cur=array[i];
while (cur!=null) {
//获取新的位置
int index=cur.key% newArray.length;
Node curNext=cur.next;//记录
//头插法完成新的哈希
cur.next=newArray[index];
newArray[index]=cur;
//因为需要遍历链表中的所有节点,所以需要提前记录cur.next
cur=curNext;
}
}
this.array=newArray;
}
get方法:
public int get(int key) {
int index=key%array.length;
Node cur=array[index];
while (cur!=null) {
if(cur.key==key) {
return cur.val;
}
cur=cur.next;
}
return -1;
}
在刚才所有的代码示例中,key都是一个普通类型,可以直接通过哈希函数来获得一个具体位置,但如果key是一个引用类型呢?
此时就需要调用该类型的hashcode()方法将其转化为整数,所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,必须覆写 hashCode 和 equals 方 法,而且要做到 equals 相等的对象,hashCode 一定是一致的。
代码示例:
自定义类:
class Person {
public String id;
public Person(String id) {
this.id=id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(id, person.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
5.面试题
1.两个对象的hashcode一样,那么equals一样吗?
两个对象的equals一样,那么hashcode一样吗?
不同对象可能获得相同的hashcode值,这两个对象只是在经过哈希函数以后存储到了同一个位置处的链表上,但不一定相同。
如果两个对象的equals相同,说明一定在同一位置,hashcode一定相同。
2.HashMap<K,V> map=new HashMap<>();底层的数组有多大?
在源码中可以看出,在不含参数的构造方法中,只有负载因子的初始化,并没有初始化数组,所以数组长度为0。

3.HashMap<K,V> map=new HashMap<>(25);底层的数组有多大?
给定初始容量的初始化,会返回接近该容量的2次幂,所以该题返回36。



4.扩容需要注意什么?
扩容需要注意所有元素都需要重新根据新的容量进行哈希,放置到新的位置。
️最后的话️
总结不易,希望uu们不要吝啬你们的哟(^U^)ノ~YO!!如有问题,欢迎评论区批评指正

边栏推荐
猜你喜欢







随机推荐
lotus-local-net 2k v1.17.0-rc4
快速学完数据库管理
Docker practical experience: Deploy mysql8 master-slave replication on Docker
如何正确地把服务器端返回的文件二进制流写入到本地保存成文件
普林斯顿微积分读本03第二章--编程实现函数图像绘制、三角学回顾
DCM 中间件家族迎来新成员
认知—运动康复医疗机器人应用设计
0x80070570文件或目录损坏且无法删除(0x80070091怎么删除)
连续变量离散化教程
R语言做面板panelvar例子
初识QEMU
[Shader] Shader official example [easy to understand]
一文吃透接口调用神器RestTemplate
The most complete phpmyadmin vulnerability summary
Acwing第 62 场周赛【未完结】
How to correctly write the binary stream of the file returned by the server to the local file and save it as a file
VBA输出日志到工作簿demo
Three-tier architecture service, dao, controller layer
消息队列面试题(2022最新整理)
apisix-Getting Started