当前位置:网站首页>CVPR 2022 | 美团技术团队精选6篇优秀论文解读
CVPR 2022 | 美团技术团队精选6篇优秀论文解读
2022-07-03 12:45:00 【海宝7号】
CVPR 2022 | 美团技术团队精选论文解读
计算机视觉国际顶会CVPR 2022近日在美国新奥尔良召开,今年美团技术团队有多篇论文被CVPR 2022收录,这些论文涵盖了模型压缩、视频目标分割、3D视觉定位、图像描述、模型安全、跨模态视频内容检索等研究领域。
本文将对6篇精选的论文做简要的介绍(附下载链接),希望能对从事相关研究的同学有所帮助或启发。
Paper 01 | Compressing Models with Few Samples: Mimicking then
ReplacingPaper 02 | Language-Bridged Spatial-Temporal Interaction for Referring
Video Object SegmentationPaper 03 | 3D-SPS: Single-Stage 3D Visual Grounding via Referred Point
Progressive SelectionPaper 04 | DeeCap: Dynamic Early Exiting for Efficient Image
CaptioningPaper 05 | Boosting Black-Box Attack with Partially Transferred
Conditional Adversarial DistributionPaper 06 | Semi-supervised Video Paragraph Grounding with Contrastive
Encoder
CVPR介绍
CVPR的全称是IEEE国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition),该会议始于1983年,与ICCV和ECCV并称计算机视觉方向的三大顶级会议。根据谷歌学术公布的2021年最新学术期刊和会议影响力排名,CVPR在所有学术刊物中位居第4,仅次于Nature、NEJM和Science。CVPR今年共收到全球8100多篇论文投稿,最终2067篇被接收,接收率约为25%。
Paper 01 |
Compressing Models with Few Samples: Mimicking then Replacing
论文作者:王环宇(美团实习生&南京大学),刘俊杰(美团),马鑫(美团),雍洋(美团实习生&西安交通大学),柴振华(美团),吴建鑫(南京大学)
| 备注:括号内的为论文发表时,论文作者所在的单位。 | 论文类型:CVPR Main Conference(Long Paper)
模型剪枝是模型压缩中一个较为成熟的研究方向,但在百万/千万数据集下剪枝后再调优的耗时问题,是制约该方向推广的一个重要痛点。近年来,小样本下模型剪枝引起了学界的关注,尤其在大规模数据集或者数据源敏感的场景下,可以迅速完成模型的压缩优化。但是,现有研究所采用的逐层通道对齐方法,在复杂结构上会极大限制可剪枝区域的范围。同时,在样本分布不均衡的情况下,过度强调层间特征分布的一致性,反而会导致优化误差的产生。
与直觉相反,本文提出了一种名为MiR (Mimicking then Replacing)的方法–通过只使用Penultimate Layer的知识传递,丢弃了传统知识蒸馏方法中依赖的后验分布对齐。并通过嫁接原模型中的分类头/检测头到压缩后的模型,可以在少样本下迅速地完成压缩模型的再调优。实验证明本文提出的算法大幅度优于各种基线方法 (并优于同期TPAMI工作),同时我们在美团图像安全审核等场景上,也得到了进一步的验证。

Paper 02 |
Language-Bridged Spatial-Temporal Interaction for Referring Video Object Segmentation
论文作者:丁子涵(美团),惠天瑞(中国科学院大学),黄君实(美团),魏晓明(美团),韩冀中(中国科学院大学),刘偲(北京航空航天大学) |
论文类型:CVPR 2022 Main Conference Long Paper(Poster)
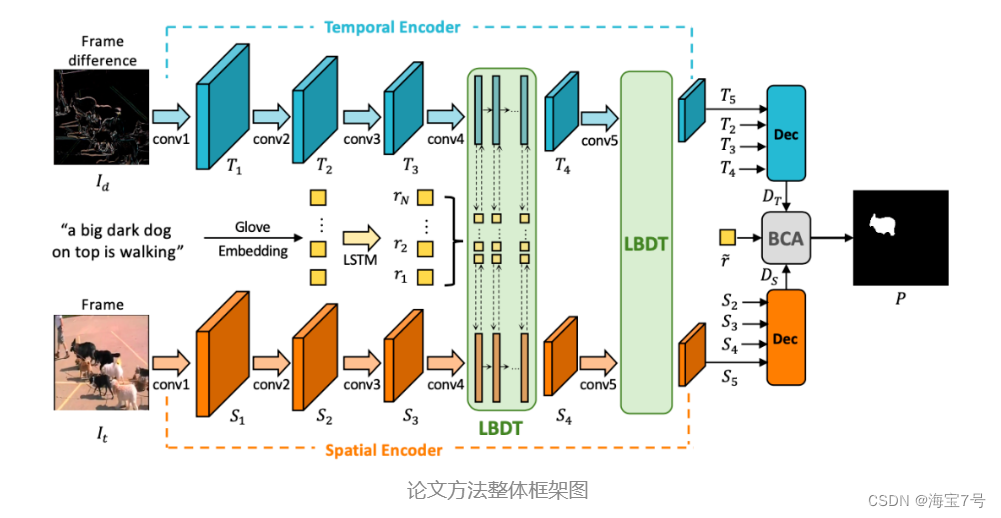
视频目标指代分割,旨在分割视频中自然语言描述所指代对象的前景像素。先前的方法要么依赖于3D卷积网络,要么结合额外的2D卷机网络作为编码器来提取混合时空特征。然而,由于在解码阶段发生的延迟和隐式时空交互,这些方法存在空间错位或错误干扰的问题。
为了解决这些限制,我们提出了一种语言桥接双向传输 (LBDT)模块,该模块利用语言作为中间桥梁,在编码阶段的早期完成显式和自适应时空交互。具体来说,在时间编码器、指代词和空间编码器之间,我们通过跨模态注意力机制聚合和传输与语言相关的运动和表观信息。此外,我们还在解码阶段提出了一个双边通道激活(BCA)模块,用于通过通道激活进一步去噪和突出时空一致的特征。大量实验表明,我们的方法在不需要图像指代分割预训练的情况下在四个普遍使用的公开数据集中实现了最优性能,并且模型效率有显著提升。
Paper 03 |
3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection
论文作者:罗钧宇(美团实习生&北京航空航天大学),付佳辉(美团实习生&北京航空航天大学),孔祥浩(美团实习生&北京航空航天大学),高晨(北京航空航天大学),任海兵(美团),申浩(美团),夏华夏(美团),刘偲(北京航空航天大学)
| 论文类型:CVPR 2022 Main Conference(Oral)
3D视觉定位任务旨在根据自然语言在点云场景中定位描述的目标对象。以前的方法大多遵循两阶段范式,即语言无关的目标检测和跨模态的目标匹配,在这种分离的范式中,由于点云相较于图像,具有不规则和大规模的特有属性,检测器需要从原始点云中采样关键点并为每个关键点生成预选框。
但是,稀疏预选框可能会在检测阶段中遗漏潜在目标,而密集预选框则可能会增大后面匹配阶段的难度。此外,与语言无关的采样得到的关键点在定位目标上的比例也较少,同样使目标预测变差。
在本文中,我们提出了一种单阶段关键点渐进选择(3D-SPS)方法,从而在语言的引导下逐步选择关键点并直接定位目标。具体来说,我们提出了一个描述感知的关键点采样(DKS)模块,以初步关注与语言相关对象上的点云数据。
此外,我们设计了一个面向目标的渐进式关系挖掘(TPM)模块,通过多层模态内关系建模和模态间目标挖掘来精细地聚焦在目标物体上。3D-SPS避免了3D视觉定位任务中检测和匹配之间的分离,在单个阶段直接定位目标。
Paper 04 |
DeeCap: Dynamic Early Exiting for Efficient Image Captioning
| 论文作者:费政聪(美团),闫旭(中科院计算所),王树徽(中科院计算所),田奇(华为) | 论文类型:CVPR 2022 Main
Conference Long Paper(Poster)
准确的描述和效率的生成,对于现实场景中图像描述的应用非常重要。基于Transformer的模型获得了显著的性能提升,但是模型的计算成本非常之高。降低时间复杂度的一种可行方法是在内部解码层中从浅层提前退出进行预测,而不通过整个模型的处理。
然而,我们在实际测试时发现以下2个问题:首先,浅层中的学习表示缺乏用于准确预测的高级语义和足够的跨模态融合信息;其次,内部分类器做出的现有决策有时是不可靠的。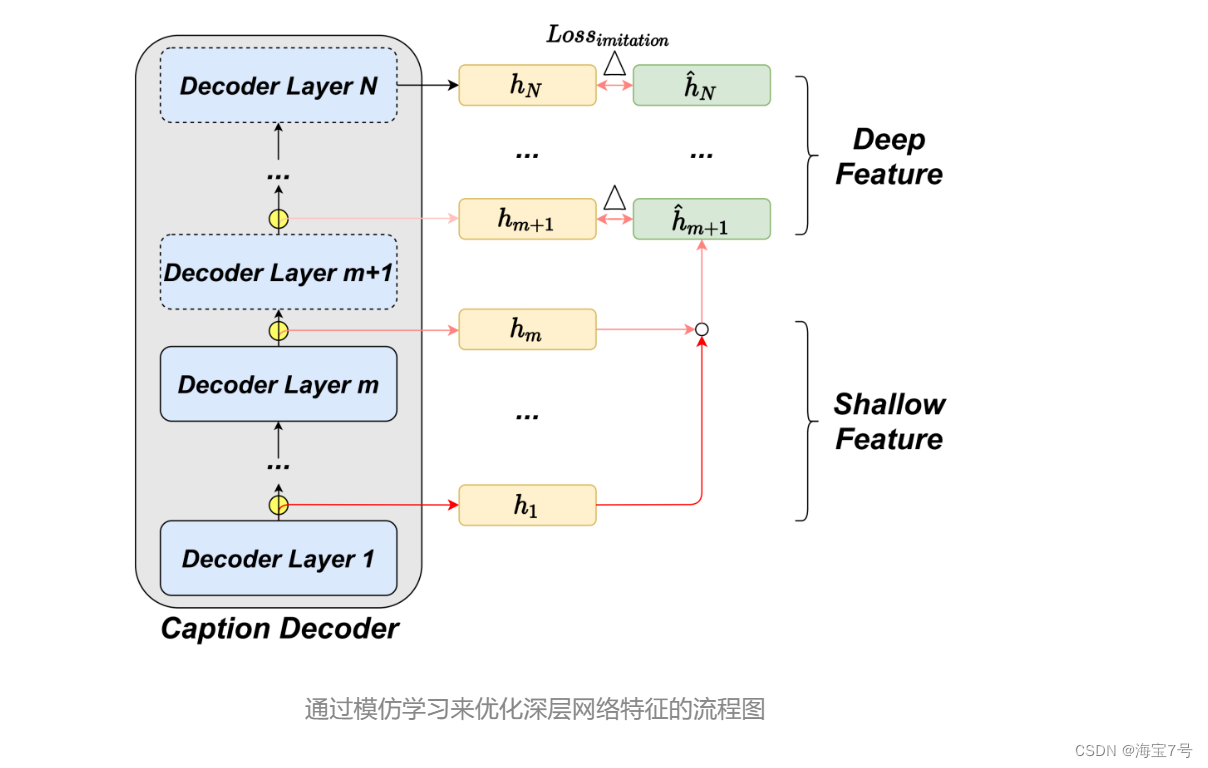
对此,我们提出了用于高效图像描述的DeeCap框架,从全局角度动态选择适当层数的解码层以提前退出。准确退出的关键在于引入的模仿学习机制,它通过浅层特征来预测深层特征。通过将模仿学习合并到整个图像描述模型中中,模仿得到的深层表示可以减轻在进行提前退出时由于缺少实际深层所带来的损失,从而有效地降低了计算成本,并保证准确性损失很小。
在MS COCO和Flickr30K数据集的实验表明,本文提出的DeeCap模型在有4倍加速度的同时保有了非常有竞争力的性能。相关代码链接:DeeCap。
Paper 05 |
Boosting Black-Box Attack with Partially Transferred Conditional Adversarial Distribution
| 论文作者:冯岩(美团),吴保元(香港中文大学),樊艳波(腾讯),刘李(香港中文大学),李志锋(腾讯),夏树涛(清华大学)
| 论文类型:CVPR 2022 Main Conference Long Paper(Poster)
本文研究在黑盒场景下的模型安全问题,即攻击者仅通过模型给出的query feedback,就实现对于目标模型的攻击。当前主流的方法是利用一些白盒代理模型和目标模型(即被攻击模型)之间的对抗可迁移性(adversarial transferrability)来提升攻击效果。
然而,由于代理模型和目标模型之间的模型架构和训练数据集可能存在差异,即“代理偏差”(Surrogate Bias),对抗性迁移性对提高攻击性能的贡献可能会被削弱。
为了解决这个问题,本文提出了一种对代理偏差具有鲁棒性的对抗可迁移性机制。总体思路是将代理模型的条件对抗分布的部分参数迁移,同时根据对目标模型的Query学习未迁移的参数,以保持在任何新的干净样本上调整目标模型的条件对抗分布的灵活性。
本文在大规模数据集以及真实API上进行了大量的实验,实验结果证明了本文提出方法的有效性。
Paper 06 |
Semi-supervised Video Paragraph Grounding with Contrastive Encoder
| 论文作者:蒋寻(电子科技大学),徐行(电子科技大学),张静然(电子科技大学),沈复民(电子科技大学),曹佐(美团),申恒涛(电子科技大学)
| 论文类型:CVPR Main Conference, Long Paper(Poster)
视频事件定位属于跨模态视频内容检索的一项任务,旨在根据输入的Query,从一段未经裁剪的视频中检索出Query对应的视频片段,相应的视频片段可用于后续生成Query对应的动图,在搜索场景中实现按搜出动图。
与视频文本检索(Video-Text Retrieval, VTR)这种检索结果为视频文件的粗粒度检索机制不同,此项任务强调在视频中实现事件级别的细粒度跨模态检索,基于对视频内容和自然语言的协同理解,在时序上达到多种模态间的对齐。
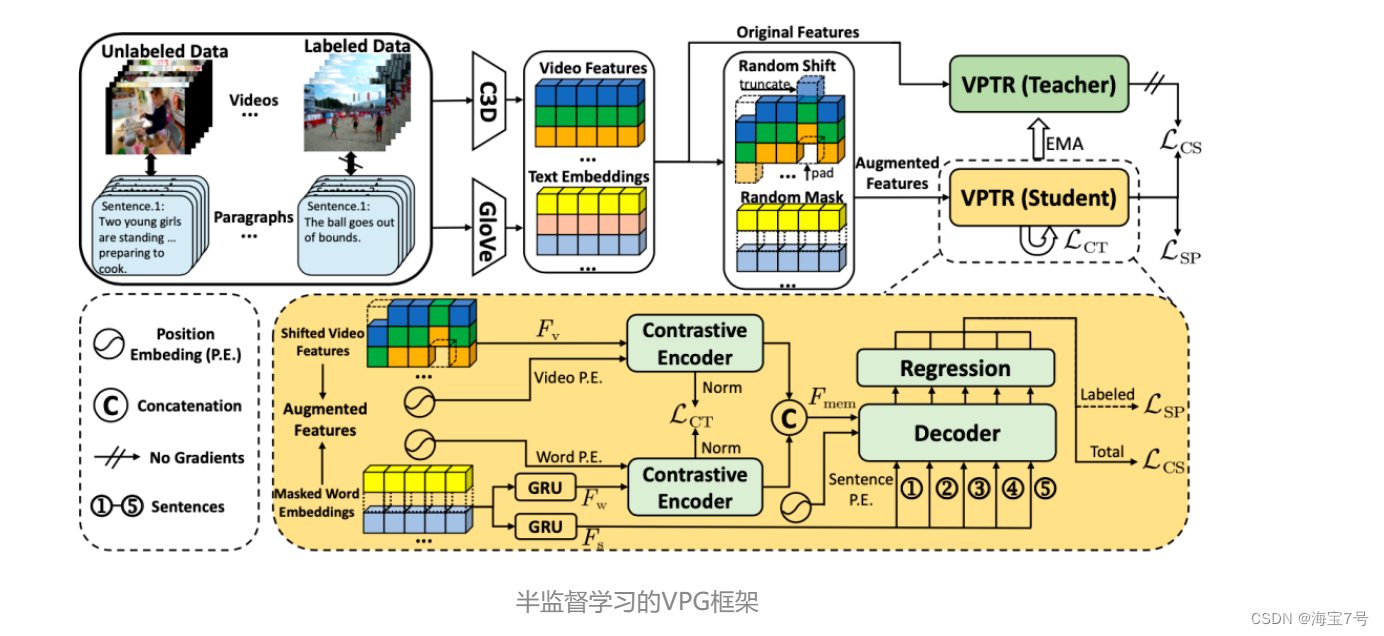
本文首次提出了一种半监督学习的VPG框架,可以在更有效地利用段落中事件上下文信息的同时,显著减少对时刻标注数据的依赖。具体来说,其由两个关键部分组成:(1) 一个基于Transformer的基础模型,通过对比编码器学习视频和段落文本之间的粗粒度对齐,同时通过引导段落中每个句子之间的交互来学习事件之间的上下文信息;(2) 一个以(1)为核心的半监督学习框架,通过平均教师模型来减少对已标注数据的依赖。实验结果表明,我们的方法在使用全部标注信息时性能达到了SOTA,同时在大量减少标注数据占比的情况下,仍然能取得相当有竞争力的结果。
此外,在CVPR 2022中,美团技术团队视觉智能部获得了第九届细粒度视觉分类研讨会(FGVC9)植物标本识别赛道的冠军,点评事业部获得了大规模跨模态商品图像召回比赛的冠军。此外,美团网约车事业部获得了轻量级NAS国际竞赛亚军。美团视觉智能部获得了深度伪造人脸检测比赛的第三名、SoccerNet 2022行人重识别比赛的第三名、大规模视频目标分割竞赛(Youtube-VOS)的第五名。
相关的技术分享,后续将会在美团技术团队公众号陆续进行推送,敬请期待。
原文来源:https://mp.weixin.qq.com/s/sblDFcBUI4U8ZPHWN9leow
美团技术团队
https://tech.meituan.com/
2021美团技术年货合辑:http://dpurl.cn/6YkRcBYz
2019-2021年前端合辑:http://dpurl.cn/LP0HtN7z
2019-2021年后端合辑:http://dpurl.cn/r416CCBz
2019-2021年算法合辑:http://dpurl.cn/xKyb85dz
2019-2021年综合文章:http://dpurl.cn/narxiDez
美团技术团队也在积极参加国际挑战赛,期望能将更多科研项目付诸于实践,进而产生更多的业务价值和社会价值。我们在实际工作场景中遇到的问题和解决方案,在论文和比赛中均有所体现,希望能对大家有所帮助或启发,也欢迎大家跟我们进行交流。
边栏推荐
- 71 articles on Flink practice and principle analysis (necessary for interview)
- PowerPoint tutorial, how to save a presentation as a video in PowerPoint?
- [Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter V exercises]
- 有限状态机FSM
- 阿南的疑惑
- 剑指 Offer 12. 矩阵中的路径
- [Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter IV exercises]
- File uploading and email sending
- The 35 required questions in MySQL interview are illustrated, which is too easy to understand
- 剑指 Offer 14- II. 剪绳子 II
猜你喜欢
 [email protected] chianxin: Perspective of Russian Ukrainian cyber war - Security confrontation and sanctions g"/>
[email protected] chianxin: Perspective of Russian Ukrainian cyber war - Security confrontation and sanctions g"/>Start signing up CCF C ³- [email protected] chianxin: Perspective of Russian Ukrainian cyber war - Security confrontation and sanctions g
Some thoughts on business

MySQL functions and related cases and exercises

道路建设问题

显卡缺货终于到头了:4000多块可得3070Ti,比原价便宜2000块拿下3090Ti
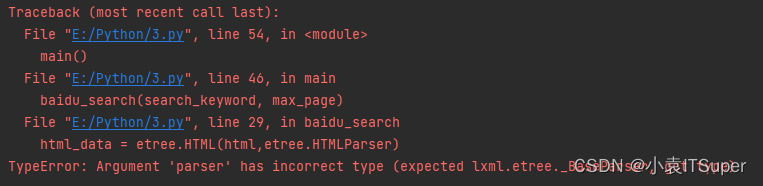
Typeerror resolved: argument 'parser' has incorrect type (expected lxml.etree.\u baseparser, got type)

regular expression
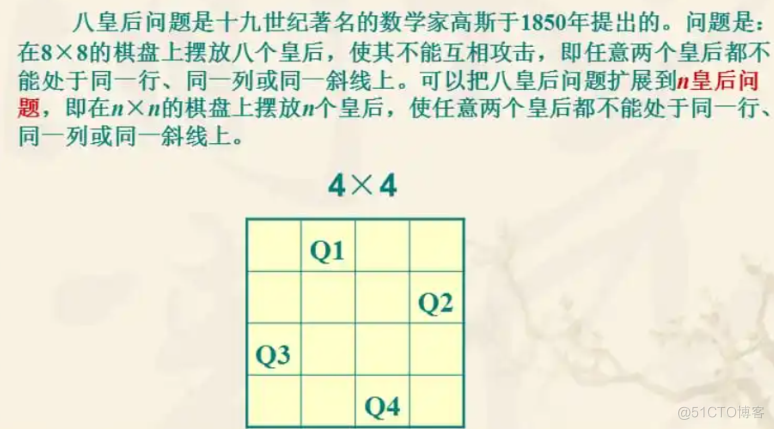
8皇后问题
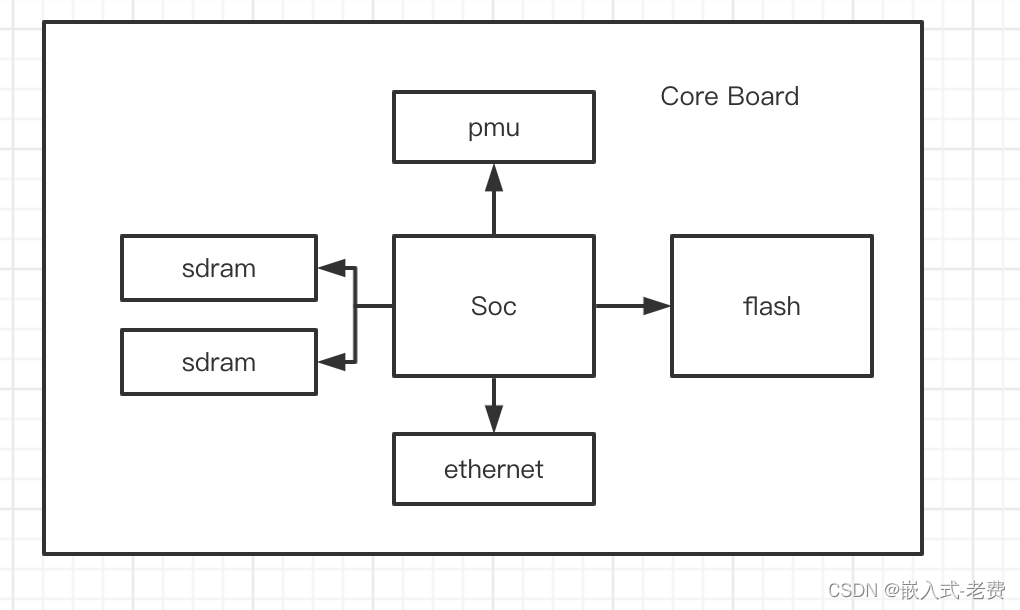
stm32和电机开发(从mcu到架构设计)
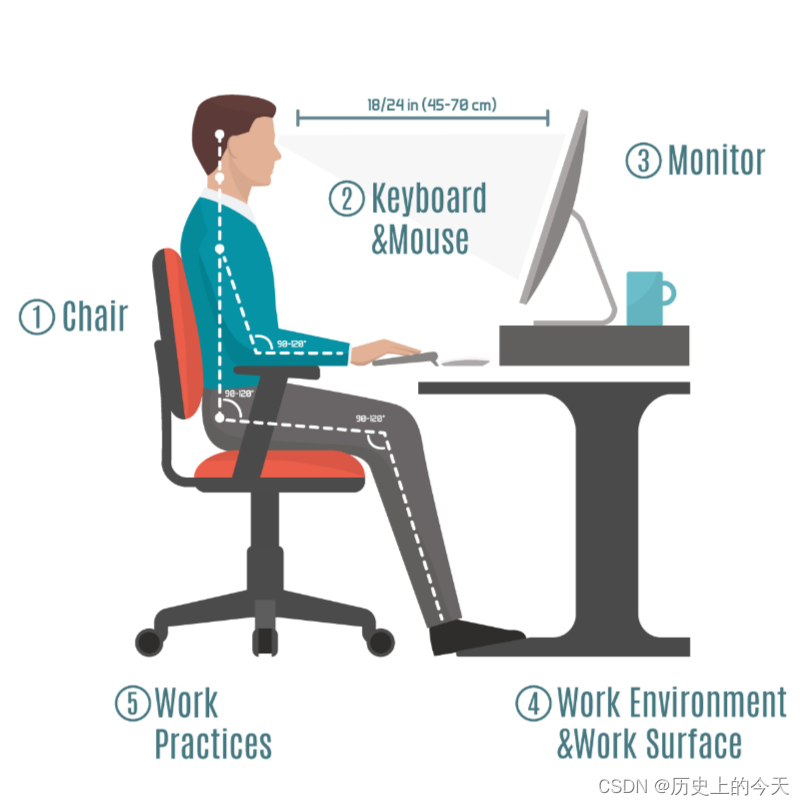
【历史上的今天】7 月 3 日:人体工程学标准法案;消费电子领域先驱诞生;育碧发布 Uplay
随机推荐
Setting up Oracle datagurd environment
Tencent cloud tdsql database delivery and operation and maintenance Junior Engineer - some questions of Tencent cloud cloudlite certification (TCA) examination
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter V exercises]
luoguP3694邦邦的大合唱站队
Kivy教程之 如何自动载入kv文件
File uploading and email sending
用户和组命令练习
The difference between stratifiedkfold (classification) and kfold (regression)
Detailed explanation of multithreading
Reptile
SSH login server sends a reminder
关于CPU缓冲行的理解
Sword finger offer 14- ii Cut rope II
Sword finger offer 15 Number of 1 in binary
Understanding of CPU buffer line
PostgreSQL installation
8皇后问题
71 articles on Flink practice and principle analysis (necessary for interview)
Red Hat Satellite 6:更好地管理服务器和云
OpenHarmony应用开发之ETS开发方式中的Image组件