当前位置:网站首页>Regular expressions and re Libraries
Regular expressions and re Libraries
2022-07-05 21:49:00 【A.way30】
Related websites
Regular expression testing
Regular expression part notes
b Station online class
Regular expressions
Definition
A syntax rule that uses expressions to match strings
Conditions of use
stay python The data analysis part of the crawler , The parsed local text content will be stored between tags or in the attributes corresponding to tags , When you want to extract the stored information , You need regular expressions .
grammar
Use metacharacters to match strings
Metacharacters
Special symbols with fixed meaning ( Match one digit by default )
| Metacharacters | meaning |
|---|---|
| . | Matches any character other than a newline character |
| \w | Match letters or numbers or underscores |
| \s | Match any whitespace |
| \d | Match the Numbers |
| \n | Match a line break |
| \t | Match a tab |
| ^ | Matches the beginning of the string |
| $ | Match the end of the string |
| \W | Match non letters or numbers or underscores |
| \D | Match non numeric |
| \S | Match non whitespace |
| a|b | Matching character α Or character b |
| () | Match the expression in brackets , It also means a group |
| […] | Match characters in a character set (a-z representative a To z All the letters ) |
| [^…] | Matches all characters except those in the character group |
Example
eg:a11111
^\d\d\d\d\d No matching results
eg:11111a
\d\d\d\d\d$ No matching results
eg: My phone number is :10010
[ I 10] I 1 0 0 1 0
quantifiers
Controls the number of occurrences of the preceding metacharacter
| quantifiers | meaning |
|---|---|
| * | Repeat zero or more times |
| + | Repeat one or more times |
| ? | Repeat zero or one time |
| {n} | repeat n Time |
| {n,} | repeat n Times or more |
| {n,m} | repeat n To m Time |
Matching mode
.* Greedy matching
.*? Laziness matches
stay python Lazy matching is commonly used in crawlers
re modular
function
pattern: Regular expressions ;string: character string ;flags: Status bit , Embeddable rules (re.S,re.M etc. )
| function | meaning |
|---|---|
| compile(pattern, flags=0) | Compiling a regular expression returns a regular expression object ( Preload regular expressions ) |
| match(pattern, string, flags=0) | Matching strings with regular expressions , Match from the beginning Matching object returned successfully Otherwise return to None |
| search(pattern, string, flags=0) | The pattern of the first occurrence of a regular expression in a search string Matching object returned successfully Otherwise return to None |
| split(pattern, string, maxsplit=0, flags=0) | Splits a string with a pattern separator specified by a regular expression Returns a list of |
| sub(pattern, repl, string, count=0, flags=0) | Replace the pattern matching the regular expression in the original string with the specified string It can be used count Specify the number of replacements |
| fullmatch(pattern, string, flags=0) | match Exact match of function ( From the beginning to the end of a string ) edition |
| findall(pattern, string, flags=0) | Find all patterns in a string that match a regular expression Returns a list of strings |
| finditer(pattern, string, flags=0) | Find all patterns in a string that match a regular expression Returns an iterator , Get the content from the iterator |
| purge() | Clear cache of implicitly compiled regular expressions |
| re.I / re.IGNORECASE | Ignore case match mark |
| re.M / re.MULTILINE | Multiline match mark |
| re.S | Single line match mark |
| (?P< Group name > Regular ) | The content can be further extracted from the regular matching content alone (p Use capital letters ) |
Example
1.findall() Return to list form
ls=re.fiindall(r'\d+'," My phone number is :10086, His phone number is :10010.")
print(ls)
#['10086','10010']
2.finditer() Return iterator
it=re.fiindall(r'\d+'," My phone number is :10086, His phone number is :10010.")
for i in it:
print(i.group())
#10086
10010
3.search() return match object
ls=re.search(r'\d+'," My phone number is :10086, His phone number is :10010.")
print(ls.group())
#10086
Only the first result is returned
4.match() Match from the beginning , And search() similar
ls=re.match(r'\d+',"10086, His phone number is :10010.")
print(ls.group())
#10086
ls=re.match(r'\d+'," My phone number is :10086, His phone number is :10010.")
print(ls.group())
# Report errors
5.compile() Preload regular expressions
obj = re.compile(r'\d')
ret = obj.finditer(" My phone number is :10086, My girlfriend's phone number is :10010")
for it in ret:
print(it.group())
ret = obj.findall(" Population 1000000")
print(ret)
#10086 10010
#['1000000']
6.(?P< Group name > Regular )
s="<div class='a'><span id='1'> Zhang San </span></div>
<div class='b'><span id='2'> Li Si </span></div>
<div class='c'><span id='3'> Wang Wu </span></div>
<div class='d' ><span id='4'> garage </span></div>
<div class='e'><span id='5'> Thompson </span></div>"
obj = re.compile(r"<div class='.*?'><span id=' (?P<id>\d+) '>(?P<name>.*?)</span></div>",re.S)
result = obj.finditer(s)
for it in result:
print(it.group( "name"))
print(it.group("id"))
# Zhang San 1
Li Si 2
Wang Wu 3
garage 4
Thompson 5
7.re.S Match the string as a whole
a = "hello123
world"
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print ('b = ' , b)
print ('c = ' , c)
# b =[] An empty list
# c =['123']
边栏推荐
- Poj 3237 Tree (Tree Chain Split)
- Oracle checkpoint queue - Analysis of the principle of instance crash recovery
- Multiplexing of Oracle control files
- 854. 相似度为 K 的字符串 BFS
- 2022-07-03-CKA-粉丝反馈最新情况
- GCC9.5离线安装
- Comprehensive optimization of event R & D workflow | Erda version 2.2 comes as "7"
- [daily training] 729 My schedule I
- Haas506 2.0 development tutorial - Alibaba cloud OTA - PAC firmware upgrade (only supports versions above 2.2)
- Some common processing problems of structural equation model Amos software
猜你喜欢
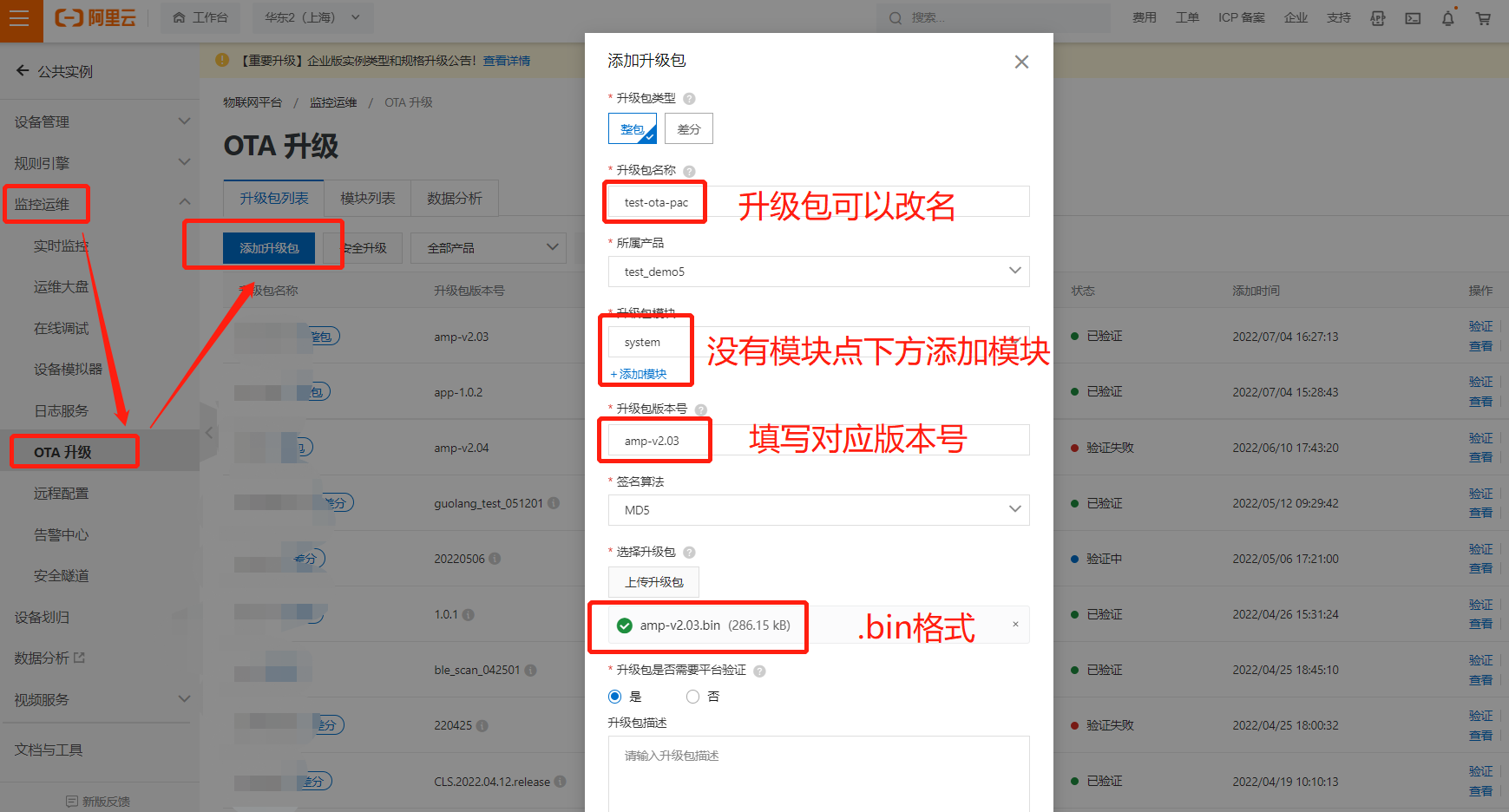
Haas506 2.0 development tutorial - Alibaba cloud OTA - PAC firmware upgrade (only supports versions above 2.2)
QML reported an error expected token ";", expected a qualified name ID

2.2 basic grammar of R language
R language learning notes
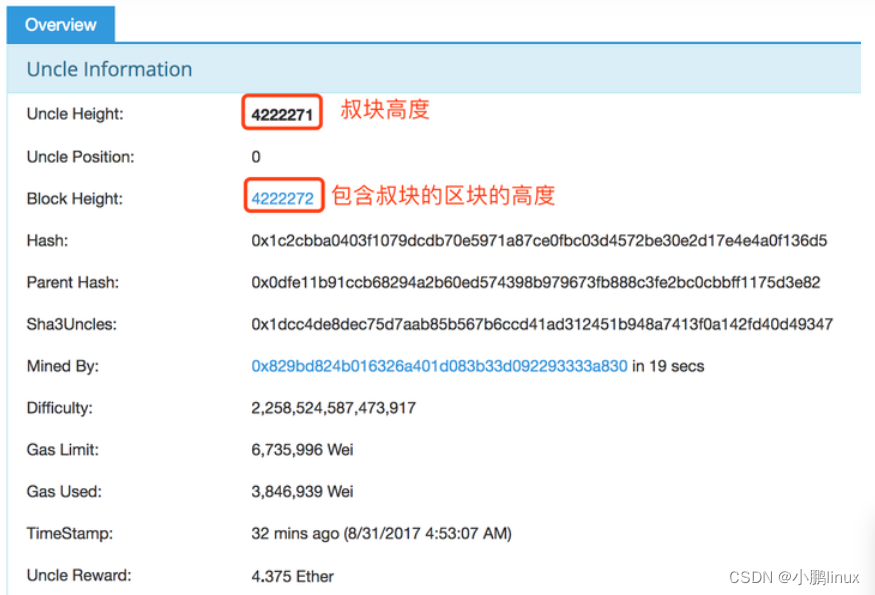
Ethereum ETH的奖励机制

Scenario interview: ten questions and ten answers about distributed locks

Yolov5 training custom data set (pycharm ultra detailed version)
DBeaver同时执行多条insert into报错处理
Teach yourself to train pytorch model to Caffe (2)
华为快游戏调用登录接口失败,返回错误码 -1
随机推荐
int GetMonth( ) const throw( ); What does throw () mean?
Li Kou ----- the maximum profit of operating Ferris wheel
让开发效率提升的跨端方案
Feng Tang's "spring breeze is not as good as you" digital collection, logged into xirang on July 8!
crm创建基于fetch自己的自定义报告
Explain various hot issues of Technology (SLB, redis, mysql, Kafka, Clickhouse) in detail from the architecture
Implementing Lmax disruptor queue from scratch (IV) principle analysis of multithreaded producer multiproducersequencer
張麗俊:穿透不確定性要靠四個“不變”
How to organize an actual attack and defense drill
Oracle检查点队列–实例崩溃恢复原理剖析
Multiplexing of Oracle control files
ICMP 介绍
Parker driver maintenance COMPAX controller maintenance cpx0200h
张丽俊:穿透不确定性要靠四个“不变”
Cross end solution to improve development efficiency rapidly
让开发效率飞速提升的跨端方案
Reading and writing operations of easyexcel
场景化面试:关于分布式锁的十问十答
MMAP learning
Pointer parameter passing vs reference parameter passing vs value parameter passing