LM-MLC 一种基于完型填空的多标签分类算法
1 前言
本文主要介绍本人在全球人工智能技术创新大赛【赛道一】设计的一种基于完型填空(模板)的多标签分类算法:LM-MLC,该算法拟合能力很强能感知标签关联性,在多个数据集上测试表明该算法与主流算法无显著性差异,在该比赛数据集上的dev效果很好,但是由于比赛期间事情多,没有好好在test集做测试。
个人认为该算法根正苗红,理论上可以获得更好的效果,因此做个开源,抛砖引玉,希望有人能提出更为有效的改进。本次开源的代码可读性较强,也有较高的扩展性,本人把LM-MLC可做的修改均写成超参形式,方便各位做测试。
2 多标签分类任务
NLP里的多标签分类任务,输入多为一段文本,输出该文本的的标签。比如在新闻类型分类中,一篇新闻可以同时有"军事"、"政治"和"历史"三个标签,再举个例子,疾病分类中,一位患者可以既感冒又咳嗽。
多标签分类任务依据数据特点又可以划分为多种类型。
2.1 文本长度
文本长度会直接影响到算法的选择,长度过长对算法语义理解要求会变高,如果长度超过512个字符,就不好直接使用BERT,需要分段编码或使用其他算法(LSTM、XLNET等)。文本过长也使得训练时间变长,着实影响到了穷逼的炼丹进度。
2.2 内容是否加密
大部分数据集是未加密的,直接可以看到原文。少部分数据集做了脱敏处理,原字词会被替换为数字或其他符号。虽说保护了隐私,但是对算法要求变高了,因为无法使用预训练模型,也没有办法做错误分析。为了达到更好的效果,需要对此类数据集继续做预训练,然后基于该预训练模型微调多标签分类任务。上文中我说的比赛就是做了加密处理。
2.3 标签数量
多标签分类数据集标签数量有多有少,少则几个多达上千(比如知乎看山杯数据集),标签数量多少也会影响到算法的选择,标签数量过多时,多标签分类任务也可以考虑转化为搜索任务,此外标签数量过多时,往往会有严重的类不平衡问题,这在设计算法时也是需要考虑的。
2.4 标签关联性
有些数据集的标签之间会存在相关性,比如新闻分类中,关于军事的新闻可能也会和政治有关系,疾病分类中,如果得了高血压,就有可能影响到视网膜。所以对于有关联的标签,算法如能考虑到标签的关联性,那么理论上效果是可以提升的,LM-MLC算法里就认真探索了标签关联性。
3 自然语言处理中的完型填空
先说一说完型填空,即一段文本,挖掉几个词,让模型去猜挖掉的词是什么,其实这就是遮挡语言模型。我们可以借助完型填空完成一些自然处理任务,关于这块的介绍,苏建林的两篇博客:博客1,博客2介绍的细致、精彩,因此我就不再过多叙述。
为了便于理解,我举个完型填空做新闻分类的例子,待分类文本是:美国攻打伊拉克,是因为萨达姆偷了布什家的高压锅 ,我们在该段文本后(或前面)加上如下一段话:这是关于[MASK]的新闻,这样完整的进入BERT的输入就是: [CLS]美国攻打伊拉克,是因为萨达姆偷了布什家的高压锅,这是关于[MASK]的新闻[SEP], 我们只要让模型判断掩掉的词是什么即可,如预测词是军事,那么分类结果就是军事,通常情况下候选词是全体标签。
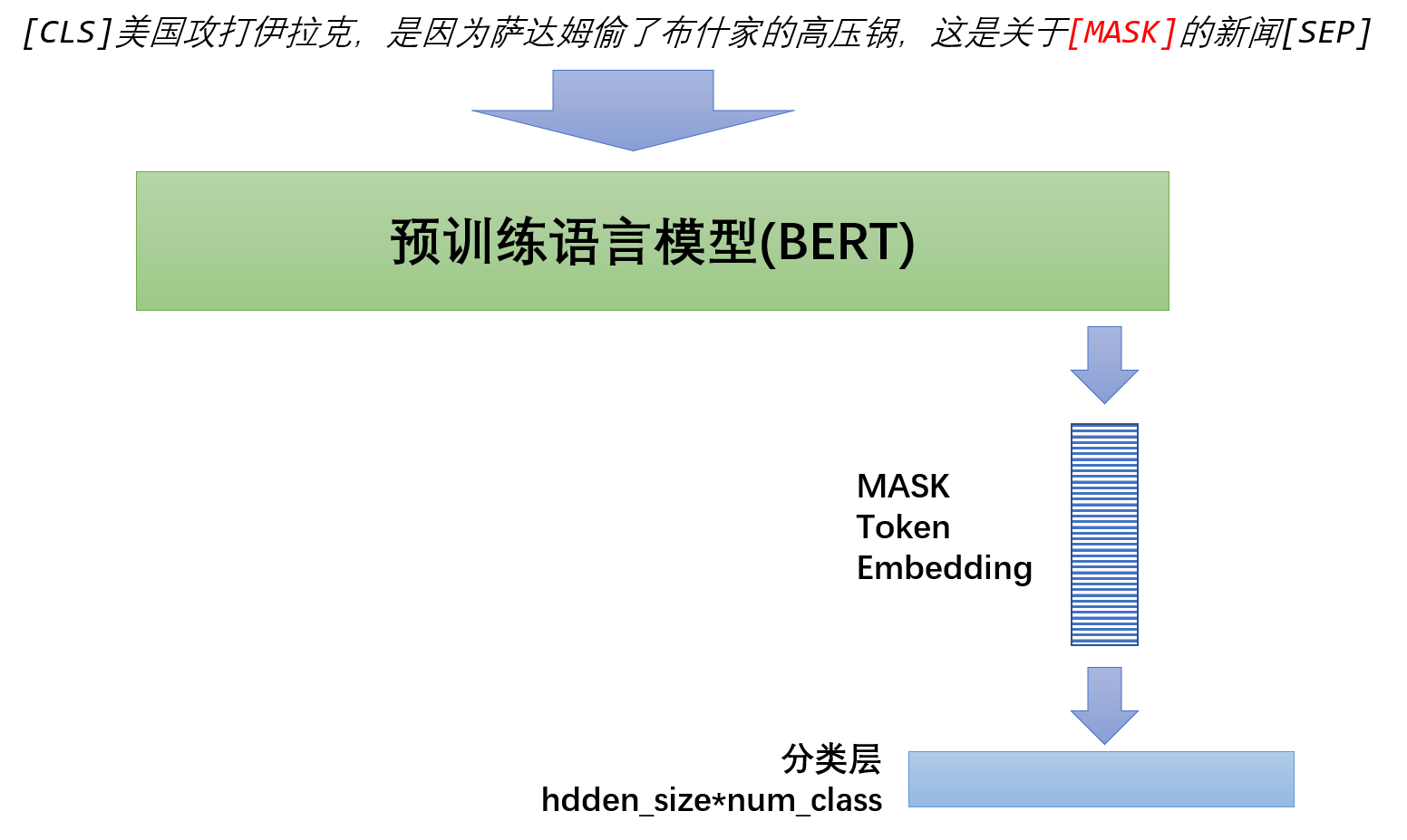
4 LM-MLC:把完型填空用在多标签分类数据集上
说了那么多背景知识,下面开始正式介绍LM-MLC算法。
4.1 模板构建
上文举得例子是关于分类的,那么对于多标签分类任务要如何构建模板呢,很自然的可以加入如下模板: "有标签1:[MASK],有标签2:[MASK],有标签3:[MASK]", 该[MASK]预测的词就是:YES或NO。一图胜千言,我们假设是在新闻多标签分类任务,共有三个标签分别是"军事","政治"和"历史",假设文本是:美国攻打伊拉克,那么输入就是:
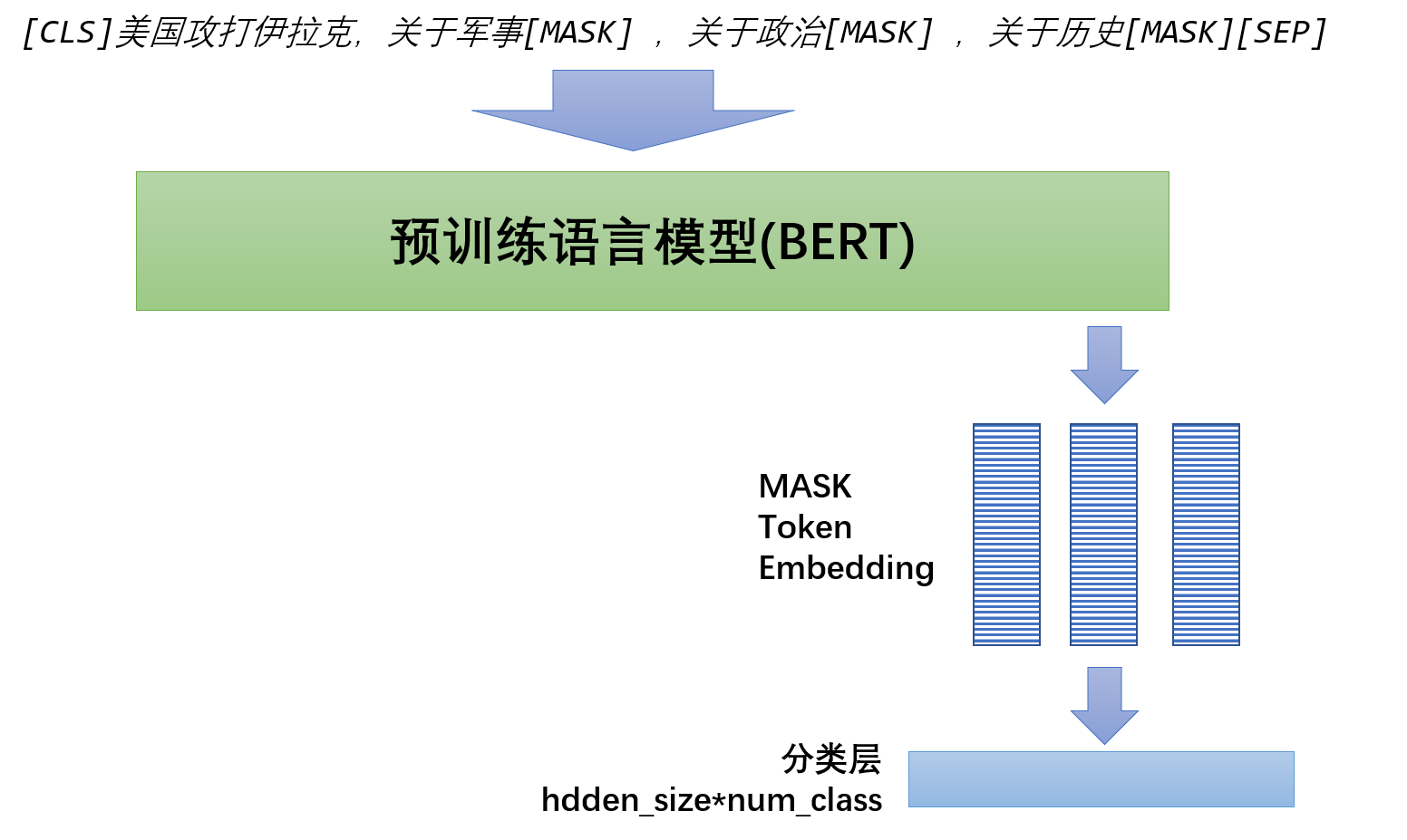
人工构建模板是一个困难的事情,模板选取很关键,模板是很不稳定的,因此本算法使用了P-tuning的做法,把模板变为[unused*]或者自己在bert的vocab中新建一些词汇,总之就是让模型自己去寻找最佳模板,所以上图输入可以进一步修改为如下形式:
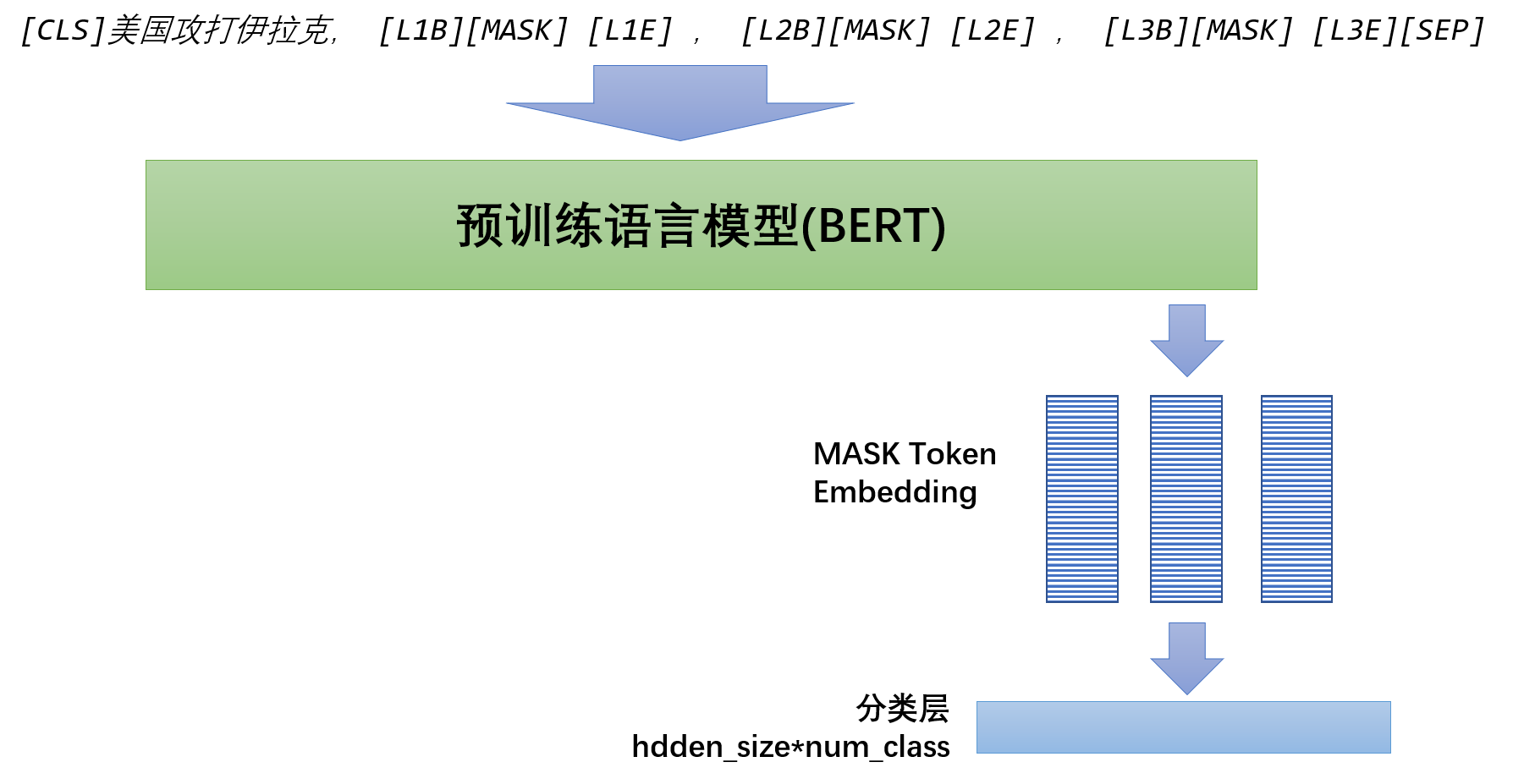
至于[MASK]前后放多少未使用字符,模板位置,不同标签是否使用不同[MASK]等就是各种微小改动,具体可以看开源代码,均以超参形式存于代码中,可以一次试个够。
4.2 模型架构
本次博客主要还是抛砖引玉,想把方法公开了和各位讨论,本次所用模型都是极为简单的,没有使用任何比赛的trick,主要提供思想。
4.2.1 Baseline模型架构
本模型的Baseline模型就是基于BERT的,模型架构极为简单,CLS向量后接全连接层,然后过Sigmoid层作为每个tag的分数。损失函数可以选用最基础的BCELoss。多提一句,也可以当成分类任务做,用交叉熵优化,但其实看公式,其实是差不多的,本人就懒得折腾了。
4.2.2 LM-MLC模型架构
模型架构图前面已经有了,再用文字描述下:基础部分还是BERT,获取TokenEmbedding后使用gather方法提取[MASK]的embedding,然后通过Sigmoid获取每个标签的分数,同样使用BCELoss损失函数。
4.3 如何训练
最简单的训练方式就是一次掩盖掉所有的标签然后全部预测,此类方法适合标签没有关联性的数据集。如果标签之间存在关联性,肯定要通过一部分标签值来预测余下的标签值,这也是LM-MLC算法的核心,很多方法都是围绕这个点设计的。
如何判断标签之间有无关联性呢,方法很简单,取训练集的标签值购置01向量,然后计算统计相关系数即可,根据系数值和下表判断相关性:
| 相关系数 | 相关性 |
|---|---|
| 0.8-1.0 | 极强相关 |
| 0.6-0.8 | 强相关 |
| 0.4-0.6 | 中等程度相关 |
| 0.2-0.4 | 弱相关 |
| 0.0-0.2 | 极弱相关或无相关 |
在训练过程中,要把一部分[MASK]改为YES或NO,这种方式让模型在对[MASK]标签做预测时不仅能感知到哪些标签值是0哪些标签值是1以及哪些标签是待预测的。在本算法中使用了[MASK]的真实值,相当于teacher-force-learning,同时为了提升模型的鲁棒性,会以1%的概率故意给错标签,实测这个trick还是挺关键的。
想要完整实现该思想时,要考虑好多细节,本人想了3种实现策略,但是也没找到最优解,我把思路和逻辑一一罗列出来供大家参考讨论。
思路一,全随机 在训练时随机掩盖一部分标签,让模型进行预测并计算损失损失
思路二,固定掩盖顺序 假设有四个标签,掩盖顺序为1->2->3->4,那么可能的掩盖顺序是:1,12,123,1234,这种方法在预测时也要使用相同的方式去预测,掩盖顺序目前没有发现最优解
思路三,UniLM 把标签作为生成任务,通过修改AttentionMask的方式来实现,即以UniLM的形式去训练,这个我没有尝试,因为这种方式已经不再是完型填空的范畴了,欢迎大家尝试。
本人比较推荐思路一,在实验中思路一的效果也是不错的
4.4 如何预测
预测时的基本思想是先预测一个标签,然后在该标签预测结果的基础上继续预测其他标签。那么最重要的问题就是如何确定预测顺序,有如下几种预测方法: 方法1:随机,即随机确定一个顺序,不足在于不同顺序会影响性能上下浮动约2个百分点 方法2:固定顺序,即按照固定顺序预测,难点在于顺序难以确定 方法3:Top-P,每一次选取模型置信度最高的标签作为首先预测的标签,效果尚可 方法4:搜索算法,使用遗传算法等搜索算法选取一个在dev上效果最号的预测顺序作为最终顺序,也可以不用搜索算法,直接random几百次找个最好的也行
方法3效果还行,方法4可提升逼格发论文。
4.5 如何进一步提升效果
在当前预训练+微调的框架下,有一个简单有效的方法那就是不要停止预训练,即把预训练模型在微调数据集上继续做预训练,然后再做微调,该方法以获得ACL2020最佳论文荣誉提名,具体参见Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks。
为什么我说LM-MLC是根正苗红呢,因为完形填空他完美契合mlm预训练任务,都是预测[MASK], 我总结两个使用该思想的方法:
-
常规做法:先继续预训练,然后微调
-
联合训练:同时做Word Mask(mlm 任务)和Label Mask(完形填空任务),然后把loss加一起,可以适当提高Label Mask的权重
本人是使用第二种,因为这两个任务实在是太契合了,通常我是微调25轮,其中前15轮联合训练,后10轮task-specific的训练,不能所有轮数都联合训练,那不然预测和训练的数据又会不一致。
4.6 小结
LM-MLC算法最大的缺点是不支持标签数量过多,假设有100个标签,模板长度为2,再加上自身MASK,那么光标签模板就占了300的长度,而BERT的输入长度限制为512,所以数据集标签多了是无法使用该方法的。
此外,由于时间精力有限,几乎没有找到合适的存在标签关联的数据集,所以对于标签关联性的一些构想还是缺少验证的,这种数据集怕是要手工构建了,绝大多数数据集都是标签无关,因此直接全部掩盖掉,全部预测就行了。
5 简单实验
数据集介绍
全球人工智能技术创新大赛【赛道一】比赛数据集,是关于医疗影像描述文本的,输出为哪些部位有异常,初赛是17分类,复赛在17分类的基础上又多了12标签分类,本人把复赛初赛复赛数据集合并到一起,当成17多标签分类任务来做。数据集不太方便提供下载。
AAPD数据集,这是开源的数据集,我分析AAPD数据集并没有较强的标签关联性,搞不懂为啥SGM多标签分类算法要用这个训练集。。。
Stackoverflow数据集,Stackoverflow的帖子都是带有tag的,截图如下,但是该数据集不能直接获得,需要去该网站下载,可能需要梯子,然后手工清洗后作为训练集,清洗代码可以见我另外一个开源库DomainSpecificThesaurus。或者先用我清洗的10W数据集,下载链接请往后看。
RCV1-V2数据集,也是开源数据集,标签间也没啥关联性,而且看着文本总感觉很奇怪。
我提供了AAPD数据集、清洗后的Stackoverflow数据集和RCv1-v2数据集,下载地址:点我下载
实验结果
因为硬件资源有限,本人工作也较忙,没有做太多的实验,这里把有记录的比赛数据集结果和AAPD数据集测试结果贴出来。
**全球人工智能技术创新大赛【赛道一】**的测试结果:
| 方法 | Acc | Micro-F1 | Jaccard-score | 1-hamming_loss |
|---|---|---|---|---|
| Baseline | 0.894 | 0.925 | 0.861 | 0.988 |
| Baseline+mlm | 0.874 | 0.917 | 0.8467 | 0.987 |
| LM-MLC | 0.900 | 0.930 | 0.869 | 0.989 |
| LM-MLC+mlm | 0.921 | 0.950 | 0.906 | 0.992 |
AAPD数据集的测试结果:
| 方法 | Acc | Micro-F1 | Jaccard-score | 1-hamming_loss |
|---|---|---|---|---|
| Baseline | 0.448 | 0.748 | 0.598 | 0.978 |
| Baseline+mlm | 0.446 | 0.758 | 0.610 | 0.980 |
| LM-MLC | 0.439 | 0.748 | 0.597 | 0.978 |
| LM-MLC+mlm | 0.453 | 0.753 | 0.604 | 0.979 |
简单解释下四个方法的含义:
- Baseline: BERT+FC, 详情见上文或源码
- Baseline+mlm: 与mlm联合训练,即mlm_loss+bce_loss
- LM-MLC: 基于完形填空的多标签分类算法,就本人所设计算法
- LM-MLC: 与mlm联合预训练,详情见上文或源码
前前后后做了很多实验,客观来说,实验结果不太符合预期,效果在其他数据集上没有显著性提升,还是挺郁闷的,抛砖引玉,希望读者能提出的改进意见。不过该方法也没有明显差于其他方法,在以后比赛中作为一种融合模型还是可以滴。
6 代码介绍
Github开源地址:https://github.com/DunZhang/LM-MLC 代码做了好多修改,力求简洁易用,同时具有较强的可读性和可扩展性,文中提到的好多点都做成了超参形式,欢迎试水
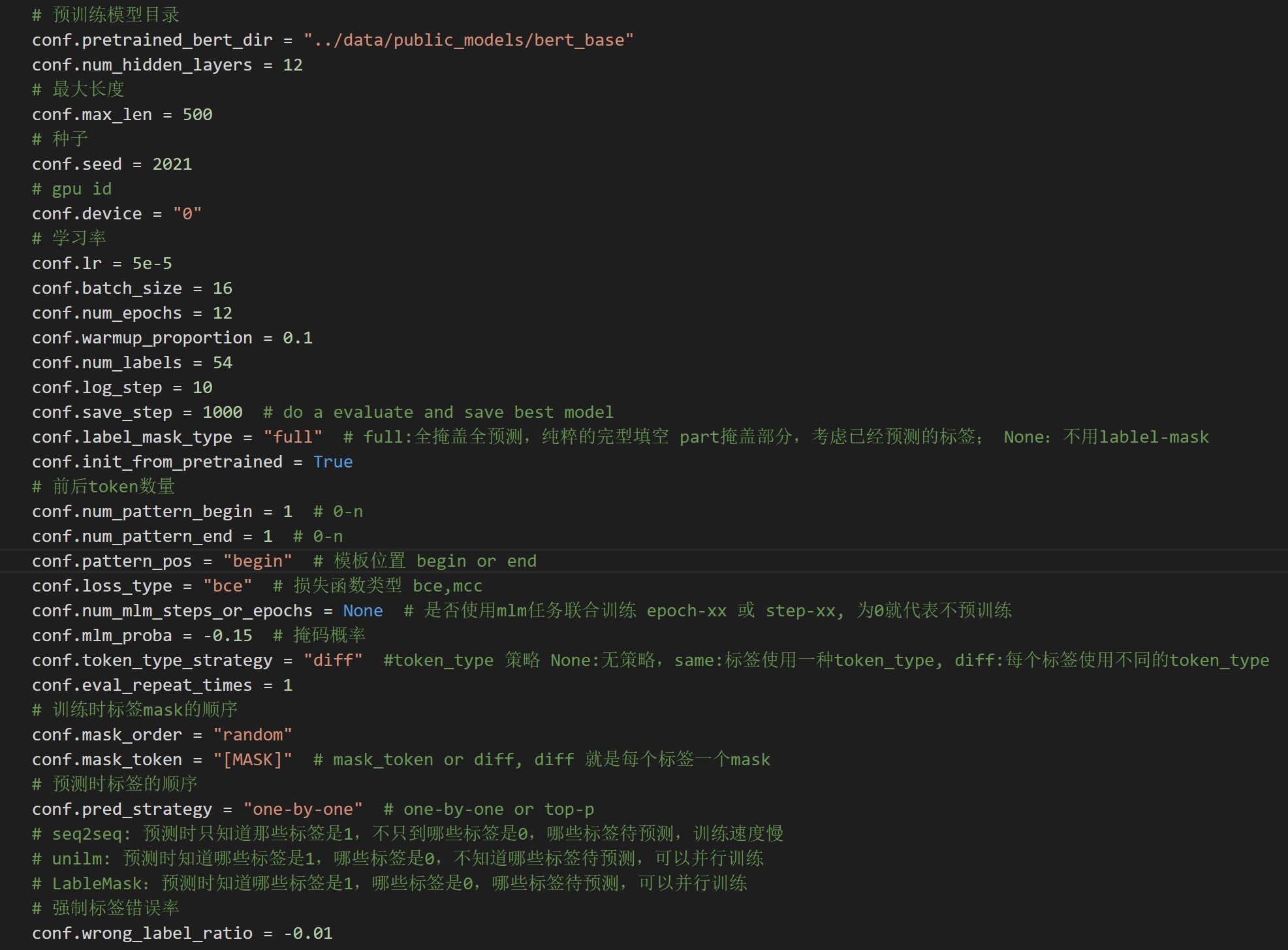
目录结构及文件名含义如下:
│ Adversarial.py # 对抗训练
│ DataIter.py # 数据生成器、迭代器
│ DataUtil.py # 相关工具
│ Evaluate.py # 评估函数
│ find_best_order.py
│ FocalLoss.py # FocalLoss
│ get_format_data.py
│ get_so_data.py
│ run_eval.py # 评测脚本
│ run_train_aapd_baseline.py # 训练脚本
│ run_train_aapd_baseline_mlm.py
│ run_train_aapd_labelmask.py
│ run_train_aapd_labelmask_mlm.py
│ run_train_gaic_baseline.py
│ run_train_gaic_baseline_mlm.py
│ run_train_gaic_labelmask.py
│ run_train_gaic_labelmask_mlm.py
│ Train.py # 训练函数
│ TrainConfig.py # 训练参数
│
└─models
│ LabelMaskModel.py # LM-MLC模型
│ SigmoidModel.py # Baseline模型
7 TODOList
-
数据集,多标签分类数据集实在是太少了,需要多搞点数据集尤其是中文数据集和标签相关的数据集
-
UnilM,可以考虑试一试,文本部分全部交互,标签逐个生成
-
考虑标签本身的语义信息,比如经济标签,经济二字本身就是有语义信息的
8 写在最后
特别感谢吉大符号计算与知识工程教育部重点实验室,提供许多思路和保贵的计算资源,希望他们能早日把基于该方法的论文搞定!
许久不写博客,打算重拾起来,博客以后纯粹的追求质量,只搞原创,只做有用的事情。顺便说下自己的下篇博客的内容:基于加密技术来编译一个属于自己的加密Python解释器,有兴趣的可以等我更新开源。

 6 Nov 16, 2022
6 Nov 16, 2022
 69 Oct 19, 2022
69 Oct 19, 2022
 68 Dec 13, 2022
68 Dec 13, 2022
 5 Feb 14, 2022
5 Feb 14, 2022
 1 Oct 21, 2021
1 Oct 21, 2021
 7 Dec 19, 2022
7 Dec 19, 2022
 59 Dec 21, 2022
59 Dec 21, 2022
 3 Sep 20, 2022
3 Sep 20, 2022
 51 Dec 08, 2022
51 Dec 08, 2022
 227 Jan 01, 2023
227 Jan 01, 2023
 [email protected]">
11 Dec 03, 2022
[email protected]">
11 Dec 03, 2022
 33 Dec 14, 2022
33 Dec 14, 2022
 472 Dec 21, 2022
472 Dec 21, 2022
 16 Sep 28, 2022
16 Sep 28, 2022
 6k Jan 06, 2023
6k Jan 06, 2023
 520 Dec 28, 2022
520 Dec 28, 2022
 125 Jan 03, 2023
125 Jan 03, 2023
 29 Jan 08, 2023
29 Jan 08, 2023
 8 Jul 16, 2022
8 Jul 16, 2022
 48 Dec 25, 2022
48 Dec 25, 2022