当前位置:网站首页>Scrapy爬虫框架
Scrapy爬虫框架
2022-07-03 18:45:00 【华为云】
Scrapy
scrapy 爬虫框架的爬取流程

scrapy框架各个组件的简介
对于以上四步而言,也就是各个组件,它们之间没有直接的联系,全部都由scrapy引擎来连接传递数据。引擎由scrapy框架已经实现,而需要手动实现一般是spider爬虫和pipeline管道,对于复杂的爬虫项目可以手写downloader和spider 的中间件来满足更复杂的业务需求。

scrapy框架的简单使用
在安装好scrapy第三方库后,通过terminal控制台来直接输入命令
- 创建一个scrapy项目
scrapy startproject myspider
- 生成一个爬虫
scrapy genspider itcast itcast.cn
- 提取数据
完善spider,使用xpath等
- 保存数据
在pipeline中进行操作
- 启动爬虫
scrapy crawl itcast
scrapy框架使用的简单流程
- 创建scrapy项目,会自动生成一系列的py文件和配置文件

- 创建一个自定义名称,确定爬取域名(可选)的爬虫

- 书写代码完善自定义的爬虫,以实现所需效果

- 使用yield 将解析出的数据传递到pipeline

- 使用pipeline将数据存储(在pipeline中操作数据需要在settings.py中将配置开启,默认是关闭)

- 使用pipeline的几点注意事项

使用logging模块
在scrapy 中
settings中设置LOG_LEVEL = “WARNING”
settings中设置LOG_FILE = “./a.log” # 设置日志文件保存位置及文件名, 同时终端中不会显示日志内容
import logging, 实例化logger的方式在任何文件中使用logger输出内容
在普通项目中
import logging
logging.basicConfig(…) # 设置日志输出的样式, 格式
实例化一个’logger = logging.getLogger(name)’
在任何py文件中调用logger即可
scrapy中实现翻页请求
案例 爬取腾讯招聘
因为现在网站主流趋势是前后分离,直接去get网站只能得到一堆不含数据的html标签,而网页展示出的数据都是由js请求后端接口获取数据然后将数据拼接在html中,所以不能直接访问网站地址,而是通过chrome开发者工具获知网站请求的后端接口地址,然后去请求该地址
通过比对网站请求后端接口的querystring,确定下要请求的url
在腾讯招聘网中,翻页查看招聘信息也是通过请求后端接口实现的,因此翻页爬取实际上就是对后端接口的请求但需要传递不同的querystring
spider 代码
import scrapyimport randomimport jsonclass TencenthrSpider(scrapy.Spider): name = 'tencenthr' allowed_domains = ['tencent.com'] start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1614839354704&parentCategoryId=40001&pageIndex=1&pageSize=10&language=zh-cn&area=cn'] # start_urls = "https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1614839354704&parentCategoryId=40001&pageIndex=1&pageSize=10&language=zh-cn&area=cn" def parse(self, response): # 由于是请求后端接口,所以返回的是json数据,因此获取response对象的text内容, # 然后转换成dict数据类型便于操作 gr_list = response.text gr_dict = json.loads(gr_list) # 因为实现翻页功能就是querystring中的pageIndex的变化,所以获取每次的index,然后下一次的index加一即可 start_url = str(response.request.url) start_index = int(start_url.find("Index") + 6) mid_index = int(start_url.find("&", start_index)) num_ = start_url[start_index:mid_index] # 一般返回的json数据会有共有多少条数据,这里取出 temp = gr_dict["Data"]["Count"] # 定义一个字典 item = {} for i in range(10): # 填充所需数据,通过访问dict 的方式取出数据 item["Id"] = gr_dict["Data"]["Posts"][i]["PostId"] item["Name"] = gr_dict["Data"]["Posts"][i]["RecruitPostName"] item["Content"] = gr_dict["Data"]["Posts"][i]["Responsibility"] item["Url"] = "https://careers.tencent.com/jobdesc.html?postid=" + gr_dict["Data"]["Posts"][i]["PostId"] # 将item数据交给引擎 yield item # 下一个url # 这里确定下一次请求的url,同时url中的timestamp就是一个13位的随机数字 rand_num1 = random.randint(100000, 999999) rand_num2 = random.randint(1000000, 9999999) rand_num = str(rand_num1) + str(rand_num2) # 这里确定pageindex 的数值 nums = int(start_url[start_index:mid_index]) + 1 if nums > int(temp)/10: pass else: nums = str(nums) next_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=' + rand_num + '&parentCategoryId=40001&pageIndex=' + nums +'&pageSize=10&language=zh-cn&area=cn' # 将 下一次请求的url封装成request对象传递给引擎 yield scrapy.Request(next_url, callback=self.parse)pipeline 代码
import csvclass TencentPipeline: def process_item(self, item, spider): # 将获取到的各个数据 保存到csv文件 with open('./tencent_hr.csv', 'a+', encoding='utf-8') as file: fieldnames = ['Id', 'Name', 'Content', 'Url'] writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writeheader() print(item) writer.writerow(item) return item补充scrapy.Request

scrapy的item使用

案例 爬取阳光网的问政信息
爬取阳光政务网的信息,通过chrome开发者工具知道网页的数据都是正常填充在html中,所以爬取阳关网就只是正常的解析html标签数据。
但注意的是,因为还需要爬取问政信息详情页的图片等信息,因此在书写spider代码时需要注意parse方法的书写
spider 代码
import scrapyfrom yangguang.items import YangguangItemclass YangguanggovSpider(scrapy.Spider): name = 'yangguanggov' allowed_domains = ['sun0769.com'] start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?page=1'] def parse(self, response): start_url = response.url # 按页分组进行爬取并解析数据 li_list = response.xpath("/html/body/div[2]/div[3]/ul[2]") for li in li_list: # 在item中定义的工具类。来承载所需的数据 item = YangguangItem() item["Id"] = str(li.xpath("./li/span[1]/text()").extract_first()) item["State"] = str(li.xpath("./li/span[2]/text()").extract_first()).replace(" ", "").replace("\n", "") item["Content"] = str(li.xpath("./li/span[3]/a/text()").extract_first()) item["Time"] = li.xpath("./li/span[5]/text()").extract_first() item["Link"] = "http://wz.sun0769.com" + str(li.xpath("./li/span[3]/a[1]/@href").extract_first()) # 访问每一条问政信息的详情页,并使用parse_detail方法进行处理 # 借助scrapy的meta 参数将item传递到parse_detail方法中 yield scrapy.Request( item["Link"], callback=self.parse_detail, meta={"item": item} ) # 请求下一页 start_url_page = int(str(start_url)[str(start_url).find("=")+1:]) + 1 next_url = "http://wz.sun0769.com/political/index/politicsNewest?page=" + str(start_url_page) yield scrapy.Request( next_url, callback=self.parse ) # 解析详情页的数据 def parse_detail(self, response): item = response.meta["item"] item["Content_img"] = response.xpath("/html/body/div[3]/div[2]/div[2]/div[3]/img/@src") yield itemitems 代码
import scrapy# 在item类中定义所需的字段class YangguangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() Id = scrapy.Field() Link = scrapy.Field() State = scrapy.Field() Content = scrapy.Field() Time = scrapy.Field() Content_img = scrapy.Field()pipeline 代码
class YangguangPipeline: # 简单的打印出所需数据 def process_item(self, item, spider): print(item) return itemscrapy的debug信息认识

通过查看scrapy框架打印的debug信息,可以查看scrapy启动顺序,在出现错误时,可以辅助解决成为。
scrapy深入之scrapy shell

通过scrapy shell可以在未启动spider的情况下尝试以及调试代码,在一些不能确定操作的情况下可以先通过shell来验证尝试。
scrapy深入之settings和管道
settings

对scrapy项目的settings文件的介绍:
# Scrapy settings for yangguang project## For simplicity, this file contains only settings considered important or# commonly used. You can find more settings consulting the documentation:## https://docs.scrapy.org/en/latest/topics/settings.html# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html# https://docs.scrapy.org/en/latest/topics/spider-middleware.html# 项目名BOT_NAME = 'yangguang'# 爬虫模块所在位置SPIDER_MODULES = ['yangguang.spiders']# 新建爬虫所在位置NEWSPIDER_MODULE = 'yangguang.spiders'# 输出日志等级LOG_LEVEL = 'WARNING'# 设置每次发送请求时携带的headers的user-argent# Crawl responsibly by identifying yourself (and your website) on the user-agent# USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45'# 设置是否遵守 robot协议# Obey robots.txt rulesROBOTSTXT_OBEY = True# 设置最大同时请求发出量# Configure maximum concurrent requests performed by Scrapy (default: 16)#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docs# 设置每次请求间歇时间#DOWNLOAD_DELAY = 3# 一般用处较少# The download delay setting will honor only one of:#CONCURRENT_REQUESTS_PER_DOMAIN = 16#CONCURRENT_REQUESTS_PER_IP = 16# cookie是否开启,默认可以开启# Disable cookies (enabled by default)#COOKIES_ENABLED = False# 控制台组件是否开启# Disable Telnet Console (enabled by default)#TELNETCONSOLE_ENABLED = False# 设置默认请求头,user-argent不能同时放置在此处# Override the default request headers:#DEFAULT_REQUEST_HEADERS = {# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',# 'Accept-Language': 'en',#}# 设置爬虫中间件是否开启# Enable or disable spider middlewares# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html#SPIDER_MIDDLEWARES = {# 'yangguang.middlewares.YangguangSpiderMiddleware': 543,#}# 设置下载中间件是否开启# Enable or disable downloader middlewares# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#DOWNLOADER_MIDDLEWARES = {# 'yangguang.middlewares.YangguangDownloaderMiddleware': 543,#}## Enable or disable extensions# See https://docs.scrapy.org/en/latest/topics/extensions.html#EXTENSIONS = {# 'scrapy.extensions.telnet.TelnetConsole': None,#}# 设置管道是否开启# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { 'yangguang.pipelines.YangguangPipeline': 300,}# 自动限速相关设置# Enable and configure the AutoThrottle extension (disabled by default)# See https://docs.scrapy.org/en/latest/topics/autothrottle.html#AUTOTHROTTLE_ENABLED = True# The initial download delay#AUTOTHROTTLE_START_DELAY = 5# The maximum download delay to be set in case of high latencies#AUTOTHROTTLE_MAX_DELAY = 60# The average number of requests Scrapy should be sending in parallel to# each remote server#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0# Enable showing throttling stats for every response received:#AUTOTHROTTLE_DEBUG = False# HTTP缓存相关设置# Enable and configure HTTP caching (disabled by default)# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings#HTTPCACHE_ENABLED = True#HTTPCACHE_EXPIRATION_SECS = 0#HTTPCACHE_DIR = 'httpcache'#HTTPCACHE_IGNORE_HTTP_CODES = []#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'管道 pipeline
在管道中不仅只有项目创建时的process_item方法,管道中还有open_spider,close_spider方法等,这两个方法就是分别在爬虫开启时和爬虫结束时执行一次。
举例代码:
class YangguangPipeline: def process_item(self, item, spider): print(item) # 如果不return的话,另一个权重较低的pipeline就不会获取到该item return item def open_spider(self, spider): # 这在爬虫开启时执行一次 spider.test = "hello" # 为spider添加了一个属性值,之后在pipeline中的process_item或spider中都可以使用该属性值 def close_spider(self, spider): # 这在爬虫关闭时执行一次 spider.test = ""mongodb的补充
借助pymongo第三方包来操作

scrapy中的crawlspider爬虫
生成crawlspider的命令:
scrapy genspider -t crawl 爬虫名 要爬取的域名


crawlspider的使用
创建爬虫scrapy genspider -t crawl 爬虫名 allow_domain
指定start_url, 对应的响应会经过rules提取url地址
完善rules, 添加Rule
Rule(LinkExtractor(allow=r’ /web/site0/tab5240/info\d+.htm’), callback=‘parse_ item’),
- 注意点:
url地址不完整, crawlspider会自动补充完整之后在请求
parse函数还不能定义, 他有特殊的功能需要实现
callback: 连接提取器提取出来的url地址对应的响应交给他处理
follow: 连接提取器提取出来的url地址对应的响应是否继续被rules来过滤
LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor( allow = (), deny = (), allow_domains = (), deny_domains = (), deny_extensions = None, restrict_xpaths = (), tags = ('a','area'), attrs = ('href'), canonicalize = True, unique = True, process_value = None)主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类:
定义爬虫的规则类。以下对这个类做一个简单的介绍:
class scrapy.spiders.Rule( link_extractor, callback = None, cb_kwargs = None, follow = None, process_links = None, process_request = None)主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
案例 爬取笑话大全网站
分析xiaohua.zolcom.cn 可以得知, 网页的数据是直接嵌在HTML中, 请求网站域名, 服务器直接返回的html标签包含了网页内可见的全部信息. 所以直接对服务器响应的html标签进行解析.
同时翻页爬取数据时,也发现下页的url 已被嵌在html中, 因此借助crawlspider可以非常方便的提取出下一页url.
spider 代码:
import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Ruleimport reclass XhzolSpider(CrawlSpider):name = 'xhzol'allowed_domains = ['xiaohua.zol.com.cn']start_urls = ['http://xiaohua.zol.com.cn/lengxiaohua/1.html']rules = ( # 这里定义从相应中提取符合该正则的url地址,并且可以自动补全, callpack指明哪一个处理函数来处理响应, follow表示从响应中提取出的符合正则的url 是否要继续进行请求 Rule(LinkExtractor(allow=r'/lengxiaohua/\d+\.html'), callback='parse_item', follow=True),)def parse_item(self, response): item = {} # item["title"] = response.xpath("/html/body/div[6]/div[1]/ul/li[1]/span/a/text()").extract_first() # print(re.findall("<span class='article-title'><a target='_blank' href='.*?\d+\.html'>(.*?)</a></span>", response.body.decode("gb18030"), re.S)) # 这里按正则搜索笑话的标题 for i in re.findall(r'<span class="article-title"><a target="_blank" href="/detail\d+/\d+\.html">(.*?)</a></span>', response.body.decode("gb18030"), re.S): item["titles"] = i yield item return itempipeline 代码:
class XiaohuaPipeline: def process_item(self, item, spider): print(item) return item简单的打印来查看运行结果
案例 爬取中国银监会网站的处罚信息
分析网页信息得知,网页的具体数据信息都是网页通过发送Ajax请求,请求后端接口获取到json数据,然后通过js动态的将数据嵌在html中,渲染出来。所以不能直接去请求网站域名,而是去请求后端的api接口。并且通过比对翻页时请求的后端api接口的变化,确定翻页时下页的url。
spider 代码:
import scrapyimport reimport jsonclass CbircSpider(scrapy.Spider): name = 'cbirc' allowed_domains = ['cbirc.gov.cn'] start_urls = ['https://www.cbirc.gov.cn/'] def parse(self, response): start_url = "http://www.cbirc.gov.cn/cbircweb/DocInfo/SelectDocByItemIdAndChild?itemId=4113&pageSize=18&pageIndex=1" yield scrapy.Request( start_url, callback=self.parse1 ) def parse1(self, response): # 数据处理 json_data = response.body.decode() json_data = json.loads(json_data) for i in json_data["data"]["rows"]: item = {} item["doc_name"] = i["docSubtitle"] item["doc_id"] = i["docId"] item["doc_time"] = i["builddate"] item["doc_detail"] = "http://www.cbirc.gov.cn/cn/view/pages/ItemDetail.html?docId=" + str(i["docId"]) + "&itemId=4113&generaltype=" + str(i["generaltype"]) yield item # 翻页, 确定下一页的url str_url = response.request.url page = re.findall(r'.*?pageIndex=(\d+)', str_url, re.S)[0] mid_url = str(str_url).strip(str(page)) page = int(page) + 1 # 请求的url变化就是 page 的增加 if page <= 24: next_url = mid_url + str(page) yield scrapy.Request( next_url, callback=self.parse1 )pipeline 代码:
import csvclass CircplusPipeline: def process_item(self, item, spider): with open('./circ_gb.csv', 'a+', encoding='gb2312') as file: fieldnames = ['doc_id', 'doc_name', 'doc_time', 'doc_detail'] writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writerow(item) return item def open_spider(self, spider): with open('./circ_gb.csv', 'a+', encoding='gb2312') as file: fieldnames = ['doc_id', 'doc_name', 'doc_time', 'doc_detail'] writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writeheader()将数据保存在csv文件中
下载中间件
学习download middleware的使用,下载中间件用于初步处理将调度器发送给下载器的request url 或 初步处理下载器请求后获取的response
同时还有process_exception 方法用于处理当中间件程序抛出异常时进行的异常处理。
下载中间件的简单使用

自定义中间件的类,在类中定义process的三个方法,方法中书写实现代码。注意要在settings中开启,将类进行注册。
代码尝试:
import random# useful for handling different item types with a single interfacefrom itemadapter import is_item, ItemAdapterclass RandomUserArgentMiddleware: # 处理请求 def process_request(self, request, spider): ua = random.choice(spider.settings.get("USER_ARENT_LIST")) request.headers["User-Agent"] = ua[0]class SelectRequestUserAgent: # 处理响应 def process_response(self, request, response, spider): print(request.headers["User=Agent"]) # 需要返回一个response(通过引擎将response交给spider)或request(通过引擎将request交给调度器)或none return responseclass HandleMiddlewareEcxeption: # 处理异常 def process_exception(self, request, exception, spider): print(exception)settings 代码:
DOWNLOADER_MIDDLEWARES = { 'suningbook.middlewares.RandomUserArgentMiddleware': 543, 'suningbook.middlewares.SelectRequestUserAgent': 544, 'suningbook.middlewares.HandleMiddlewareEcxeption': 544,}scrapy 模拟登录
scrapy 携带cookie登录
在scrapy中, start_url不会经过allowed_domains的过滤, 是一定会被请求, 查看scrapy 的源码, 请求start_url就是由start_requests方法操作的, 因此通过自己重写start_requests方法可以为请求start_url 携带上cookie信息等, 实现模拟登录等功能.

通过重写start_requests 方法,为我们的请求携带上cookie信息,来实现模拟登录功能。

补充知识点:
scrapy中 cookie信息是默认开启的,所以默认请求下是直接使用cookie的。可以通过开启COOKIE_DEBUG = True 可以查看到详细的cookie在函数中的传递。
案例 携带cookie模拟登录人人网
通过重写start_requests方法,为请求携带上cookie信息,去访问需要登录后才能访问的页面,获取信息。模拟实现模拟登录的功能。
import scrapyimport reclass LoginSpider(scrapy.Spider): name = 'login' allowed_domains = ['renren.com'] start_urls = ['http://renren.com/975252058/profile'] # 重写方法 def start_requests(self): # 添加上cookie信息,这之后的请求中都会携带上该cookie信息 cookies = "anonymid=klx1odv08szk4j; depovince=GW; _r01_=1; taihe_bi_sdk_uid=17f803e81753a44fe40be7ad8032071b; taihe_bi_sdk_session=089db9062fdfdbd57b2da32e92cad1c2; ick_login=666a6c12-9cd1-433b-9ad7-97f4a595768d; _de=49A204BB9E35C5367A7153C3102580586DEBB8C2103DE356; t=c433fa35a370d4d8e662f1fb4ea7c8838; societyguester=c433fa35a370d4d8e662f1fb4ea7c8838; id=975252058; xnsid=fadc519c; jebecookies=db5f9239-9800-4e50-9fc5-eaac2c445206|||||; JSESSIONID=abcb9nQkVmO0MekR6ifGx; ver=7.0; loginfrom=null; wp_fold=0" cookie = {i.split("=")[0]:i.split("=")[1] for i in cookies.split("; ")} yield scrapy.Request( self.start_urls[0], callback=self.parse, cookies=cookie ) # 打印用户名,验证是否模拟登录成功 def parse(self, response): print(re.findall("该用户尚未开", response.body.decode(), re.S))scrapy模拟登录之发送post请求
借助scrapy提供的FromRequest对象发送Post请求,并且可以设置fromdata,headers,cookies等参数。
案例 scrapy模拟登录github
模拟登录GitHub,访问github.com/login, 获取from参数, 再去请求/session 验证账号密码,最后登录成功
spider 代码:
import scrapyimport reimport randomclass GithubSpider(scrapy.Spider): name = 'github' allowed_domains = ['github.com'] start_urls = ['https://github.com/login'] def parse(self, response): # 先从login 页面的响应中获取出authenticity_token和commit,在请求登录是必需 authenticity_token = response.xpath("//*[@id='login']/div[4]/form/input[1]/@value").extract_first() rand_num1 = random.randint(100000, 999999) rand_num2 = random.randint(1000000, 9999999) rand_num = str(rand_num1) + str(rand_num2) commit = response.xpath("//*[@id='login']/div[4]/form/div/input[12]/@value").extract_first() form_data = dict( commit=commit, authenticity_token=authenticity_token, login="[email protected]", password="tcc062556", timestamp=rand_num, # rusted_device="", ) # form_data["webauthn-support"] = "" # form_data["webauthn-iuvpaa-support"] = "" # form_data["return_to"] = "" # form_data["allow_signup"] = "" # form_data["client_id"] = "" # form_data["integration"] = "" # form_data["required_field_b292"] = "" headers = { "referer": "https://github.com/login", 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'accept-language': 'zh-CN,zh;q=0.9', 'accept-encoding': 'gzip, deflate, br', 'origin': 'https://github.com' } # 借助fromrequest 发送post请求,进行登录 yield scrapy.FormRequest.from_response( response, formdata=form_data, headers=headers, callback=self.login_data ) def login_data(self, response): # 打印用户名验证是否登录成功 print(re.findall("xiangshiersheng", response.body.decode())) # 保存成本地html 文件 with open('./github.html', 'a+', encoding='utf-8') as f: f.write(response.body.decode())总结:
模拟登录三种方式:
1. 携带cookie登录
使用scrapy.Request(url, callback=, cookies={})
将cookies填入,在请求url时会携带cookie去请求。
2. 使用FormRequest
scrapy.FromRequest(url, formdata={}, callback=)
formdata 就是请求体, 在formdata中填入要提交的表单数据
3. 借助from_response
scrapy.FromRequest.from_response(response, formdata={}, callback=)
from_response 会自动从响应中搜索到表单提交的地址(如果存在表单及提交地址)
边栏推荐
- Torch learning notes (2) -- 11 common operation modes of tensor
- Multifunctional web file manager filestash
- English语法_名词 - 分类
- [Godot] add menu button
- 编程中常见的 Foo 是什么意思?
- 2022.02.11
- Have you learned the correct expression posture of programmers on Valentine's day?
- Mysql45 lecture learning notes (II)
- Hard disk monitoring and analysis tool: smartctl
- FBI warning: some people use AI to disguise themselves as others for remote interview
猜你喜欢

平淡的生活里除了有扎破皮肤的刺,还有那些原本让你魂牵梦绕的诗与远方

2022-2028 global marking ink industry research and trend analysis report

Sensor 调试流程
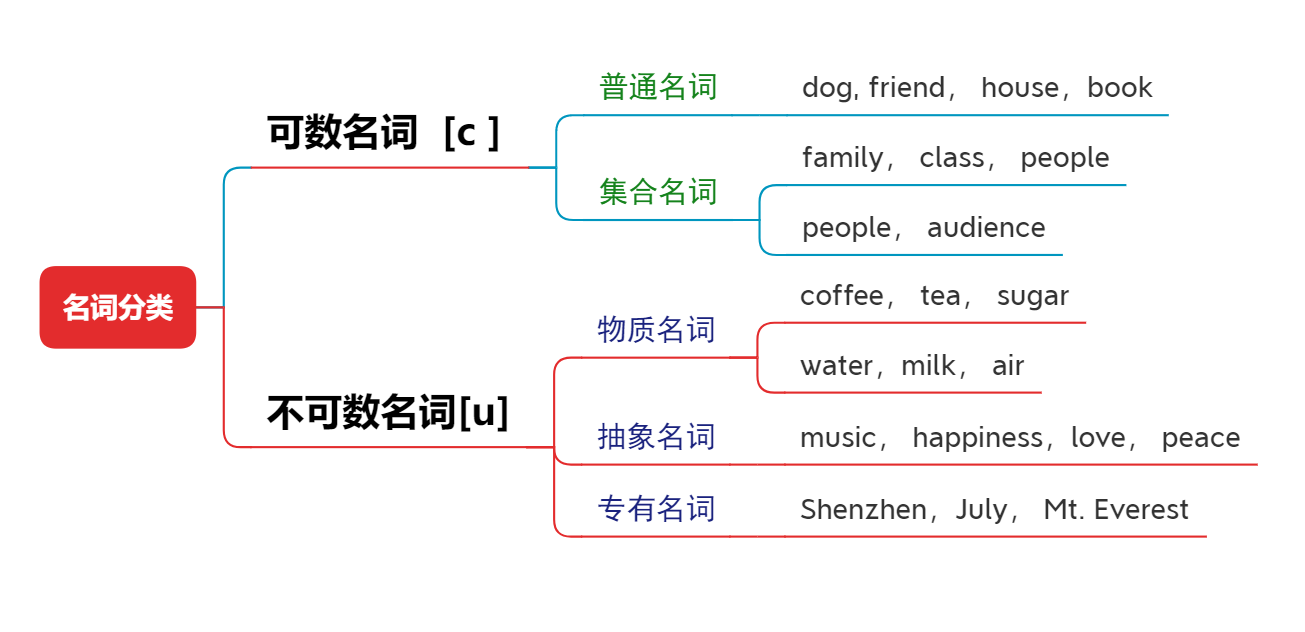
English语法_名词 - 分类
![Bloom filter [proposed by bloom in 1970; redis cache penetration solution]](/img/f9/27a75454b464d59b9b3465d25fe070.jpg)
Bloom filter [proposed by bloom in 1970; redis cache penetration solution]

235. 二叉搜索樹的最近公共祖先【lca模板 + 找路徑相同】

Kratos微服务框架下实现CQRS架构模式
2022-2028 global copper foil (thickness 12 μ M) industry research and trend analysis report

What London Silver Trading software supports multiple languages
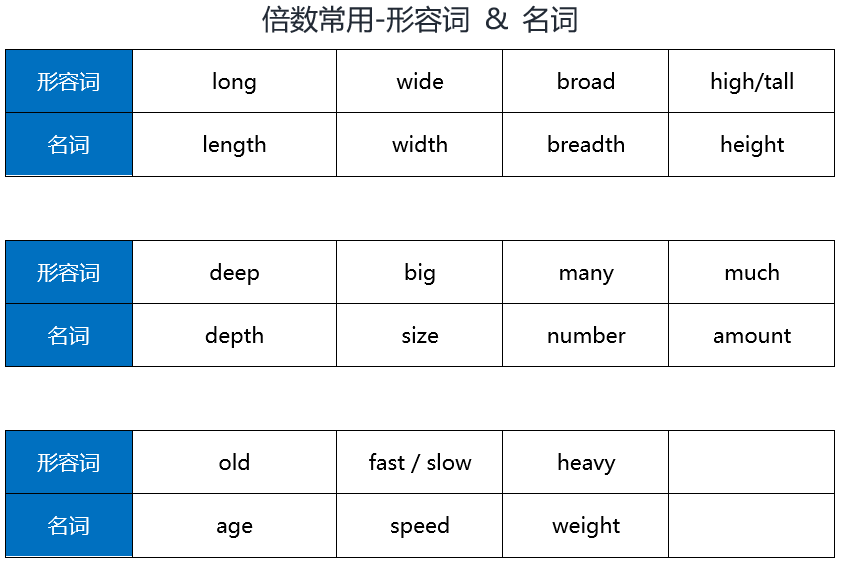
English语法_形容词/副词3级 - 倍数表达
随机推荐
How to disable the clear button of ie10 insert text box- How can I disable the clear button that IE10 inserts into textboxes?
leetcode:11. 盛最多水的容器【双指针 + 贪心 + 去除最短板】
Administrative division code acquisition
Chisel tutorial - 06 Phased summary: implement an FIR filter (chisel implements 4-bit FIR filter and parameterized FIR filter)
English grammar_ Noun classification
简述服务量化分析体系
What is the function of registering DLLs- What does registering a DLL do?
Change is the eternal theme
Database creation, addition, deletion, modification and query
Work Measurement - 1
[Godot] add menu button
[combinatorics] generating function (positive integer splitting | unordered | ordered | allowed repetition | not allowed repetition | unordered not repeated splitting | unordered repeated splitting)
How many convolution methods does deep learning have? (including drawings)
Mysql45 lecture learning notes (II)
Zero length array
Opencv learning notes (continuously updated)
How to analyze the rising and falling rules of London gold trend chart
NFT新的契机,多媒体NFT聚合平台OKALEIDO即将上线
235. Ancêtre public le plus proche de l'arbre de recherche binaire [modèle LCA + même chemin de recherche]
How about the Moco model?