当前位置:网站首页>CV in transformer learning notes (continuously updated)
CV in transformer learning notes (continuously updated)
2022-07-03 18:23:00 【ZRX_ GIS】
List of articles
Why is it cv Chinese research Transformer
Research background
Transformer stay CV The field is just beginning to emerge ,Transformer Put forward in NLP Good results have been achieved in the direction , Its whole Attention structure , It not only enhances the ability of feature extraction , It also maintains the characteristics of parallel computing , It can be done quickly NLP Most tasks in the field , Greatly promote its development . however , It is hardly used in CV Direction . Before that, only Obiect detection Species DETR Large scale use Transformer, Others include Semantic Segmentation It has not been substantially applied in the field of , pure Transformer The structure of the network is not .
Transformer advantage


1、 Parallel operation ;2、 Global vision ;3、 Flexible stacking capability
Transformer+classfiaction
ViT
original text 《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
ViT Historical significance
1、 Show the CV Use pure Transformer Structural possibilities
2、 Pioneering work in this field
Abstract
although Transformer Architecture has become the de facto standard for natural language processing tasks , But its application in computer vision is still limited . In terms of vision , Attention is either used in conjunction with convolutional networks , Or it can be used to replace some components of convolution network , While keeping its overall structure unchanged . We prove this right cnn Dependency is unnecessary , A pure transformer directly applied to image block sequence can perform image classification tasks well . After pre training a large amount of data and transmitting it to multiple small and medium-sized image recognition benchmarks (ImageNet、CIFAR-100、VTAB etc. ) when , Compared with the most advanced convolutional network ,Vision Transformer (ViT) Excellent results were obtained , However, the computing resources required for training are greatly reduced .
Summary :1、Transformer stay NLP Has become a classic ;2, stay CV in ,Attention The mechanism is only used as a supplement ;3、 We use pure Transformer Structure can achieve good results in image classification tasks ;4、 After training on large enough data ,ViT You can get and CNN Of SODA The results are comparable
ViT structure
The core idea : Segmentation rearrangement 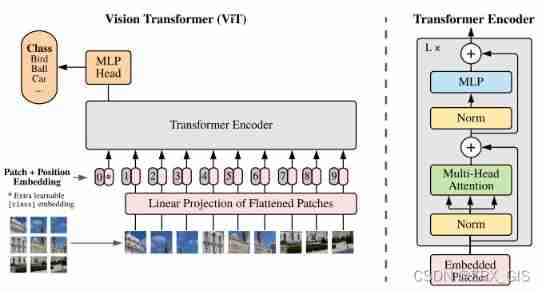
Attention
The core idea : weighted mean ( Calculate similarity )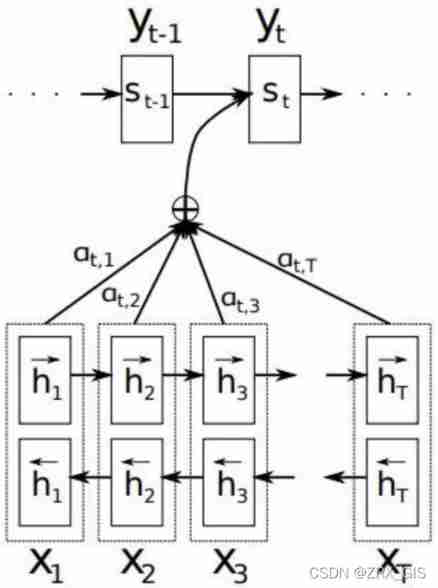
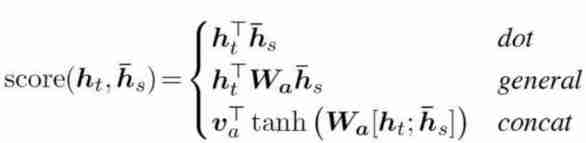
advantage :1、 Parallel operation ;2、 Global vision
MultiHead-Attention
The core idea : Similarity calculation , How many? W(Q,K,A) Just repeat the operation for how many times , result concat once 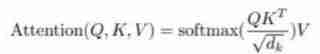
Q:query;K:key;V:Value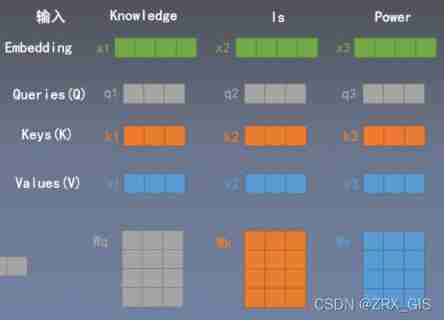
Input adapter
The core idea : Cut the picture directly , Then enter the number into the network
Why Patch0: ** Need a vector that integrates information **: If there is only the vector of the original input , There will be a problem of selection quantity , It's not good to use any vector to classify , It takes a lot of calculation , So join a learnable vector That is to say Patch0 To integrate information .
Location code (Positional Encoding)
After image segmentation and rearrangement, the position information is lost , also Transformer The internal operation of is independent of spatial information , Therefore, it is necessary to encode the location information and retransmit it to the network ,ViT Used a learnable vector Encoding , code vector and patch vector Add directly to form the input .
Training methods
Large scale use Pre-Train, First, pre train on the big data set , Then go to the small data set Fine Tune
After the migration , Need to put the original MLP Head replace , Replace with the number of corresponding categories FC layer ( As in the past )
When dealing with different size inputs, you need to correct Positional Encoding The results are interpolated .
Attention Relationship between distance and network layers
Attention The distance can be equivalent to Conv The size of the receptive field in You can see the deeper the number of layers ,Attention The farther you cross But at the bottom , There are also head It can cover a long distance This shows that they are indeed responsible Global Information Integration
A summary of the paper
Model structure ——Transformer Encoder
Input adapter —— Segment the pictures and rearrange
Location code —— Learnable vector To express
pure Transformer Do classification tasks
Simple input adaptation can be used
A large number of experiments have revealed that pure
Transformer do CV The possibility of .
PVT
Swin Transformer
Transformer+detection
DETR
Deformable DETR
Sparse RCNN
边栏推荐
- How to expand the capacity of golang slice slice
- [untitled]
- [LINUX]CentOS 7 安装MYSQL时报错“No package mysql-server available“No package zabbix-server-mysql availabl
- Administrative division code acquisition
- An academic paper sharing and approval system based on PHP for computer graduation design
- [combinatorics] generating function (commutative property | derivative property | integral property)
- [combinatorics] generating function (positive integer splitting | unordered non repeated splitting example)
- webcodecs
- English语法_形容词/副词3级 - 倍数表达
- Reappearance of ASPP (atlas spatial pyramid pooling) code
猜你喜欢
![AcWing 271. Teacher Yang's photographic arrangement [multidimensional DP]](/img/3d/6d61fefc62063596221f98999a863b.png)
AcWing 271. Teacher Yang's photographic arrangement [multidimensional DP]
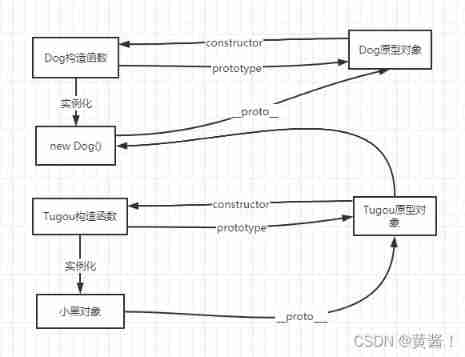
Prototype inheritance..

G1 garbage collector of garbage collector
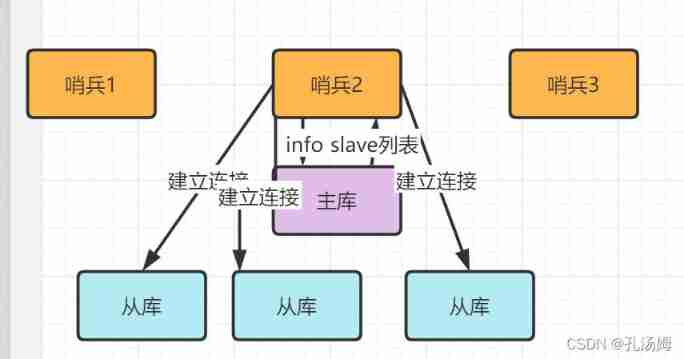
Redis core technology and practice - learning notes (VIII) sentinel cluster: sentinel hung up
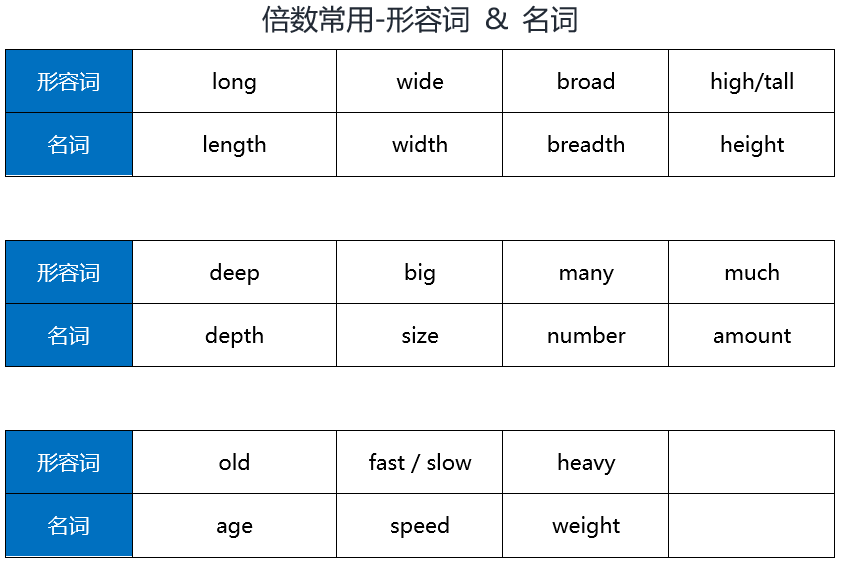
English语法_形容词/副词3级 - 倍数表达
![[Godot] add menu button](/img/44/ef1e6ac25bcbc8cc3ecc00c52f8ee2.jpg)
[Godot] add menu button

PHP MySQL preprocessing statement

NFT新的契机,多媒体NFT聚合平台OKALEIDO即将上线

Redis core technology and practice - learning notes (IX): slicing cluster
English语法_名词 - 分类
随机推荐
[combinatorics] generating function (summation property)
199. Right view of binary tree - breadth search
Computer graduation design PHP makeup sales Beauty shopping mall
Line by line explanation of yolox source code of anchor free series network (6) -- mixup data enhancement
Summary and Reflection on the third week of winter vacation
Redis core technology and practice - learning notes (VIII) sentinel cluster: sentinel hung up
Redis on local access server
PHP MySQL create database
[combinatorics] exponential generating function (proving that the exponential generating function solves the arrangement of multiple sets)
Distributed task distribution framework gearman
Three gradient descent methods and code implementation
2022-2028 global scar care product industry research and trend analysis report
Use of unsafe class
How to quickly view the inheritance methods of existing models in torchvision?
Theoretical description of linear equations and summary of methods for solving linear equations by eigen
On Data Mining
Torch learning notes (1) -- 19 common ways to create tensor
PHP MySQL preprocessing statement
English grammar_ Adjective / adverb Level 3 - multiple expression
Should I be laid off at the age of 40? IBM is suspected of age discrimination, calling its old employees "dinosaurs" and planning to dismiss, but the employees can't refute it