当前位置:网站首页>Common algorithm interview has been out! Machine learning algorithm interview - KDnuggets
Common algorithm interview has been out! Machine learning algorithm interview - KDnuggets
2020-11-06 01:20:00 【On jdon】
If the common algorithm is the common programmer's necessary knowledge , So is a more practical machine learning algorithm ? Or is it a necessary knowledge for data scientists ?
In preparing for an interview in Data Science , It is necessary to have a clear understanding of the various machine learning models - Give a brief description of each ready-made model . ad locum , We summarize various machine learning models by highlighting the main points , To help you communicate complex models .
Linear regression
Linear regression involves the use of the least square method to find “ Best fit line ”. The least squares method involves finding a linear equation , The equation minimizes the sum of squares of residuals . The residual is equal to the actual negative predictive value .
for instance , The red line is a better fit than the green line , Because it's closer to the point , So the residuals are small .
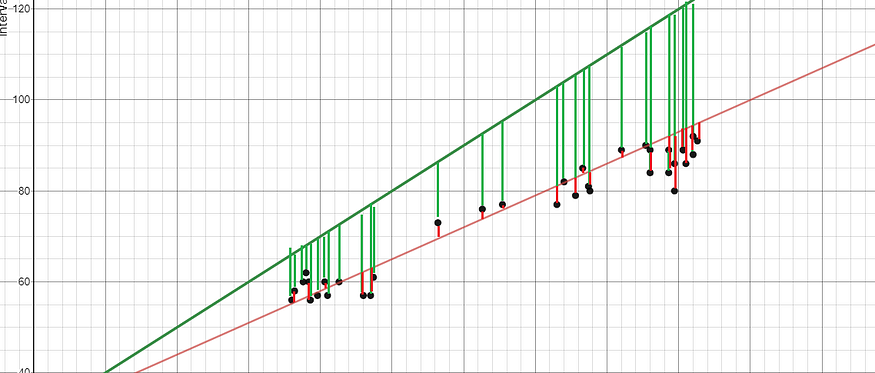
The picture was created by the author .
Ridge Return to
Ridge Return to ( Also known as L2 Regularization ) It's a regression technique , A small amount of deviation can be introduced to reduce over fitting . It works by minimizing the square of residuals And plus Penalty points to achieve this goal , The penalty is equal to λ Times the slope squared .Lambda It means the severity of the punishment .
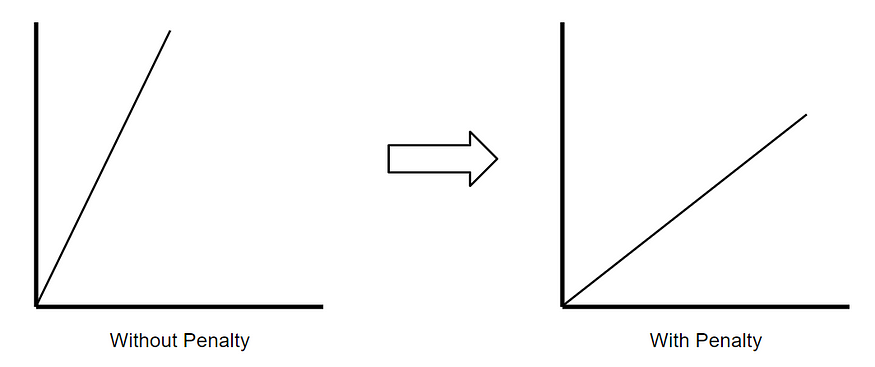
The picture was created by the author .
If there is no punishment , Then the slope of the best fit line becomes steeper , That means it's good for X More sensitive to subtle changes in . By introducing punishment , Best fit line pairs X It becomes less sensitive . Back of the ridge return .
Lasso Return to
Lasso Return to , Also known as L1 Regularization , And Ridge Return to similar . The only difference is , The penalty is calculated using the absolute value of the slope .
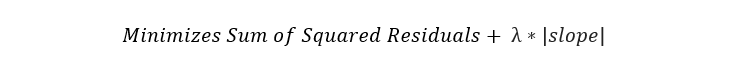
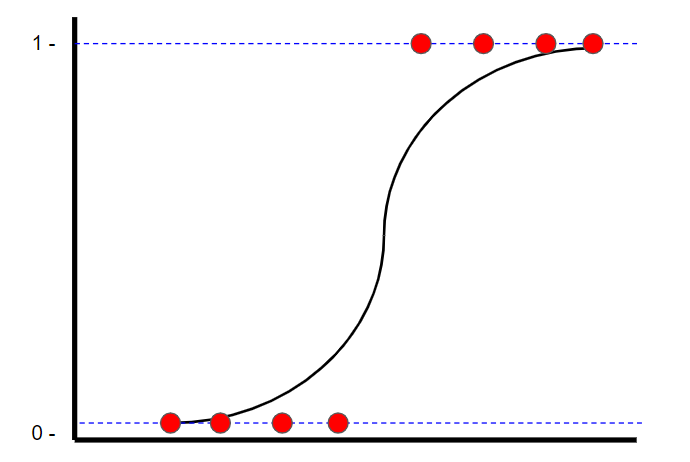
Logical regression
Logistic Regression is a classification technique , You can also find “ The most suitable straight line ”. however , Unlike linear regression , In linear regression , Use the least square to find the best fit line , Logistic regression uses maximum likelihood to find the best fit line ( The logic curve ). This is because y Value can only be 1 or 0. watch StatQuest In the video , Learn how to calculate the maximum likelihood .
The picture was created by the author .
K Nearest neighbor
K Nearest neighbor is a classification technique , Classify the new samples by looking at the nearest classification point , So called “ K lately ”. In the following example , If k = 1, Then unclassified points are classified as blue dots .
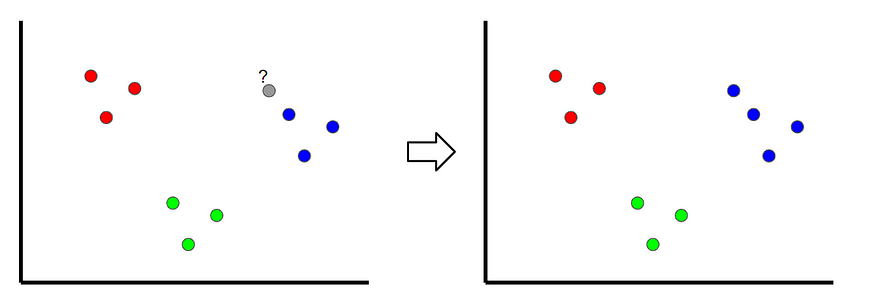
The picture was created by the author .
If k The value of is too low , There may be outliers . however , If it's too high , It is possible to ignore classes with only a few samples .
Naive Bayes
Naive Bayes classifier is a classification technique inspired by Bayes theorem , The following equation is stated :
Because of naive assumptions ( Hence the name ), Variables are independent in the case of a given class , So it can be rewritten as follows P(X | y):
Again , Because we have to solve y, therefore P(X) It's a constant , This means that we can remove it from the equation and introduce proportionality .
therefore , Each one y The probability of value is calculated as given y Conditional probability of x n The product of the .
Support vector machine
Support vector machine is a classification technique , We can find the best boundary called hyperplane , This boundary is used to separate different categories . Find hyperplanes by maximizing the margin between classes .
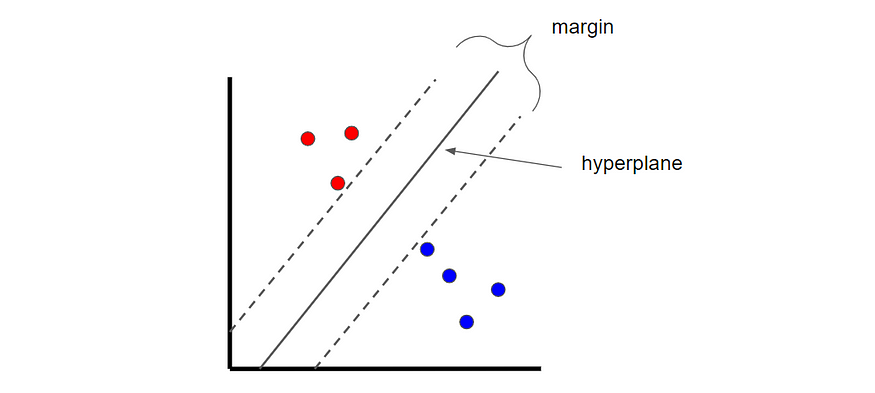
The picture was created by the author .
Decision tree
Decision tree is essentially a series of conditional statements , These conditional statements determine the path taken by the sample before it reaches the bottom . They are intuitive and easy to build , But it's often inaccurate .
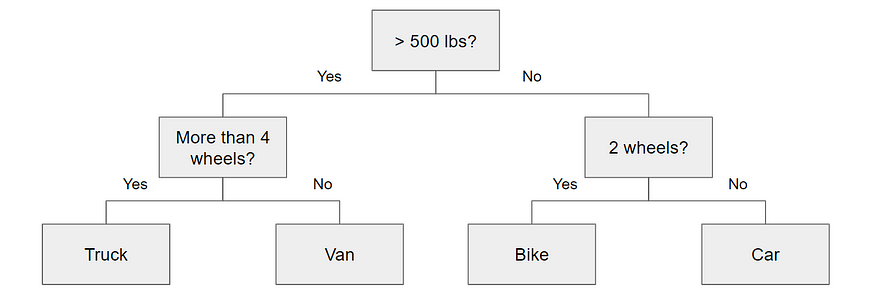
Random forests
Random forest is an integrated technology , This means that it combines multiple models into one model to improve its predictive power . say concretely , It uses bootstrap data sets and random subsets of variables ( Also known as bagging ) Thousands of smaller decision trees have been built . With thousands of smaller decision trees , Random forest use “ The majority wins ” Model to determine the value of the target variable .

for example , If we create a decision tree , The third decision tree , It will predict 0. however , If we rely on all 4 A decision tree model , Then the predicted value will be 1. This is the power of random forests .
AdaBoost
AdaBoost It's an enhancement algorithm , Be similar to “ Random forests ”, But there are two important differences :
- AdaBoost It's not usually made up of trees , It's a forest of stumps ( A stump is a tree with only one node and two leaves ).
- The decision of each stump has a different weight in the final decision . The total error is small ( High accuracy ) The stump has a higher voice .
- The order in which the stumps are created is important , Because each subsequent stump emphasizes the importance of samples that were not correctly classified in the previous stump .
Gradient rise
Gradient Boost And AdaBoost similar , Because it can build multiple trees , Each of these trees was built from the previous tree . And AdaBoost You can build stumps differently ,Gradient Boost Can be built, usually with 8 to 32 A leafy tree .
what's more ,Gradient Boost And AdaBoost The difference is in the way decision trees are constructed . Gradient enhancement starts with the initial prediction , It's usually the average . then , The decision tree is constructed based on the residuals of samples . By using the initial prediction + The learning rate is multiplied by the result of the residual tree to make a new prediction , Then repeat the process .
XGBoost
XGBoost Essentially with Gradient Boost identical , But the main difference is how to construct the residual tree . Use XGBoost, The residual tree can be determined by calculating the similarity score between the leaf and the previous node , To determine which variables are used as roots and nodes .
版权声明
本文为[On jdon]所创,转载请带上原文链接,感谢
边栏推荐
- 中小微企业选择共享办公室怎么样?
- Filecoin主网上线以来Filecoin矿机扇区密封到底是什么意思
- 小程序入门到精通(二):了解小程序开发4个重要文件
- 从海外进军中国,Rancher要执容器云市场牛耳 | 爱分析调研
- 你的财务报告该换个高级的套路了——财务分析驾驶舱
- Computer TCP / IP interview 10 even asked, how many can you withstand?
- 业内首发车道级导航背后——详解高精定位技术演进与场景应用
- 人工智能学什么课程?它将替代人类工作?
- 《Google軟體測試之道》 第一章google軟體測試介紹
- Filecoin的经济模型与未来价值是如何支撑FIL币价格破千的
猜你喜欢
Basic principle and application of iptables
Can't be asked again! Reentrantlock source code, drawing a look together!
Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!

Summary of common algorithms of linked list
JVM memory area and garbage collection
DRF JWT authentication module and self customization
![[JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor](/img/cc/17b647d403c7a1c8deb581dcbbfc2f.jpg)
[JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor
Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)

CCR炒币机器人:“比特币”数字货币的大佬,你不得不了解的知识
Subordination judgment in structured data
随机推荐
(2)ASP.NET Core3.1 Ocelot路由
Tool class under JUC package, its name is locksupport! Did you make it?
阿里云Q2营收破纪录背后,云的打开方式正在重塑
Grouping operation aligned with specified datum
采购供应商系统是什么?采购供应商管理平台解决方案
Technical director, to just graduated programmers a word - do a good job in small things, can achieve great things
How do the general bottom buried points do?
快快使用ModelArts,零基础小白也能玩转AI!
Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!
How to get started with new HTML5 (2)
使用 Iceberg on Kubernetes 打造新一代云原生数据湖
Elasticsearch database | elasticsearch-7.5.0 application construction
Every day we say we need to do performance optimization. What are we optimizing?
C language 100 question set 004 - statistics of the number of people of all ages
Asp.Net Core learning notes: Introduction
Using Es5 to realize the class of ES6
Programmer introspection checklist
多机器人行情共享解决方案
助力金融科技创新发展,ATFX走在行业最前列
数据产品不就是报表吗?大错特错!这分类里有大学问