当前位置:网站首页>[secretly kill little partner pytorch20 days] - [day3] - [example of text data modeling process]
[secretly kill little partner pytorch20 days] - [day3] - [example of text data modeling process]
2022-07-03 21:40:00 【aJupyter】
System tutorial 20 Heaven takes Pytorch
Recently with Brother Zhong 、 Huige Do a little punch in ,20 God pytorch, This is the first 3 God . Welcome to one button and three links .
List of articles
One 、 Prepare the data
imdb The goal of the data set is to predict the emotional tags of movie reviews based on the text content of movie reviews .
The training set has 20000 Film review text , The test set has 5000 Film review text , Both positive and negative comments account for half .
Text data preprocessing is cumbersome , Including Chinese segmentation ( This example does not cover ), Building a dictionary , Encoding conversion , Sequence filling , Building data pipelines and so on .
stay torch Preprocessing text data in generally uses torchtext Or custom Dataset,torchtext Very powerful , Can build text classification , Sequence annotation , Q & a model , Machine translation, etc NLP The data set of the task .
The following is just a demonstration of how to use it to build text classification data sets .
torchtext common API List
torchtext.data.Example : Used to represent a sample , Data and labels
torchtext.vocab.Vocab: glossary , You can import some pre training word vectors
torchtext.data.Datasets: Dataset class ,__getitem__ return Example example , torchtext.data.TabularDataset Is its subclass .
torchtext.data.Field : The processing method used to define the field ( The text field , Label fields ) establish Example At the time of the Preprocessing ,batch Some processing operations during .
torchtext.data.Iterator: iterator , Used to generate batch
torchtext.datasets: Contains common data sets .
## Building a dictionary
word_count_dict = {
}
# Clean the text
def clean_text(text):
lowercase = text.lower().replace("\n"," ")
stripped_html = re.sub('<br />', ' ',lowercase)
cleaned_punctuation = re.sub('[%s]'%re.escape(string.punctuation),'',stripped_html)
return cleaned_punctuation
with open(train_data_path,"r",encoding = 'utf-8') as f:
for line in f:
label,text = line.split("\t")
cleaned_text = clean_text(text)
for word in cleaned_text.split(" "):
word_count_dict[word] = word_count_dict.get(word,0)+1
df_word_dict = pd.DataFrame(pd.Series(word_count_dict,name = "count"))
df_word_dict = df_word_dict.sort_values(by = "count",ascending =False)# ascending =False Descending
df_word_dict = df_word_dict[0:MAX_WORDS-2]
df_word_dict["word_id"] = range(2,MAX_WORDS) # Number 0 and 1 Leave the unknown words separately <unkown> And fill <padding>
word_id_dict = df_word_dict["word_id"].to_dict()
df_word_dict.head(-5)
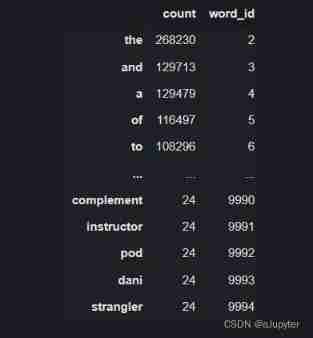
Then we use the constructed Dictionary , Convert text to token Serial number .
tips:
The dictionary is constructed on all training sets
and token Every row of data set is on the dictionary id Number mapping
# transformation token
# Fill in the text
def pad(data_list,pad_length):
padded_list = data_list.copy()
if len(data_list)> pad_length:
padded_list = data_list[-pad_length:]
if len(data_list)< pad_length: # token The length is not enough to make up two 1
padded_list = [1]*(pad_length-len(data_list))+data_list
return padded_list
def text_to_token(text_file,token_file):
with open(text_file,"r",encoding = 'utf-8') as fin,\
open(token_file,"w",encoding = 'utf-8') as fout:
for line in fin:
label,text = line.split("\t")
cleaned_text = clean_text(text)
word_token_list = [word_id_dict.get(word, 0) for word in cleaned_text.split(" ")]
pad_list = pad(word_token_list,MAX_LEN)
# print(pad_list)
# break
out_line = label+"\t"+" ".join([str(x) for x in pad_list])
fout.write(out_line+"\n")
text_to_token(train_data_path,train_token_path)
text_to_token(test_data_path,test_token_path)
And then token The text is segmented according to the sample , Each file holds one sample of data .
tips:
To put it bluntly, it is to put every line token Write to different files
# Split the sample
import os
if not os.path.exists(train_samples_path):
os.mkdir(train_samples_path)
if not os.path.exists(test_samples_path):
os.mkdir(test_samples_path)
def split_samples(token_path,samples_dir):
with open(token_path,"r",encoding = 'utf-8') as fin:
i = 0
for line in fin:
with open(samples_dir+"%d.txt"%i,"w",encoding = "utf-8") as fout:
fout.write(line)
i = i+1
split_samples(train_token_path,train_samples_path)
split_samples(test_token_path,test_samples_path)
print(min(os.listdir(train_samples_path)))
Everything is all set. , We can create Build data set Dataset, Read the contents of the file from the file name list .
import os
import torch
from torch.utils.data import Dataset,DataLoader
class imdbDataset(Dataset):
def __init__(self,samples_dir):
self.samples_dir = samples_dir
self.samples_paths = os.listdir(samples_dir)
def __len__(self):
return len(self.samples_paths)
def __getitem__(self,index):
path = self.samples_dir + self.samples_paths[index]
with open(path,"r",encoding = "utf-8") as f:
line = f.readline()
label,tokens = line.split("\t")
label = torch.tensor([float(label)],dtype = torch.float)
feature = torch.tensor([int(x) for x in tokens.split(" ")],dtype = torch.long)
return (feature,label)
ds_train = imdbDataset(train_samples_path)
ds_test = imdbDataset(test_samples_path)
print(len(ds_train))
print(len(ds_test))
dl_train = DataLoader(ds_train,batch_size = BATCH_SIZE,shuffle = True,num_workers=4)
dl_test = DataLoader(ds_test,batch_size = BATCH_SIZE,num_workers=4)
for features,labels in dl_train:
print(features.shape)
print(labels.shape)
break
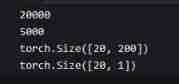
Summary of data preprocessing
1. Prepare the dictionary on the whole training set
2. The training set and test set are translated into token
3. Will be different token And labels are written to different files
4. structure dataset, there dataset 【def getitem(self,index)】 Before returning, turn to tensor, In fact, the data set can also be transformed into tensor, But the latter method needs to be handled batch_size Data , The previous one only needs to be handled 1 Data .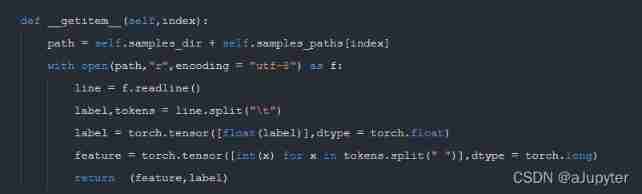
Two 、 Defining models
Use Pytorch There are usually three ways to build models :
- Use nn.Sequential Build models in a hierarchical order
- Inherit nn.Module Base classes build custom models
- Inherit nn.Module Base classes build models and assist in applying model containers (nn.Sequential,nn.ModuleList,nn.ModuleDict) encapsulate .
Here you choose to use the third method to build .
Because the next training cycle in the form of class , We encapsulate the model into torchkeras.Model Class to get something like Keras Functions of medium and high-order model interface .
Model Class actually inherits from nn.Module class .
import torch
from torch import nn
import torchkeras
torch.random.seed()
import torch
from torch import nn
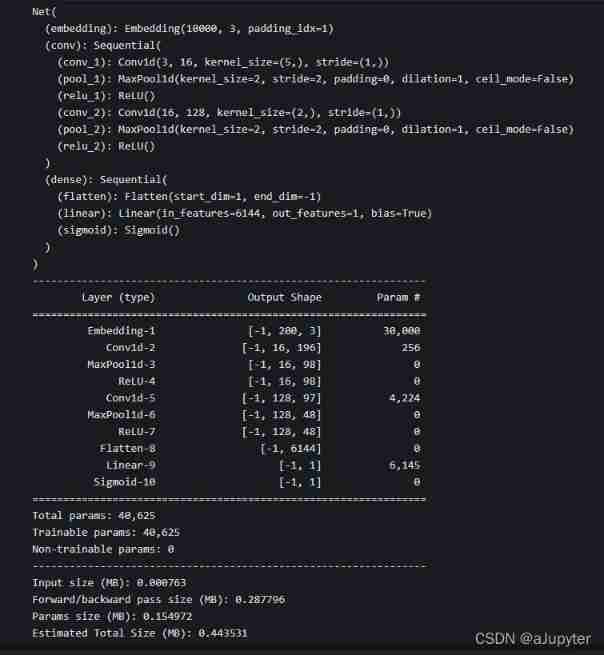
class Net(torchkeras.Model):
def __init__(self):
super(Net, self).__init__()
# Set up padding_idx Parameters will be filled in the training process token Always assign to 0 vector
self.embedding = nn.Embedding(num_embeddings = MAX_WORDS,embedding_dim = 3,padding_idx = 1)
self.conv = nn.Sequential()
self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))
self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_1",nn.ReLU())
self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))
self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_2",nn.ReLU())
self.dense = nn.Sequential()
self.dense.add_module("flatten",nn.Flatten())
self.dense.add_module("linear",nn.Linear(6144,1))
self.dense.add_module("sigmoid",nn.Sigmoid())
def forward(self,x):
x = self.embedding(x).transpose(1,2)
x = self.conv(x)
y = self.dense(x)
return y
model = Net()
print(model)
model.summary(input_shape = (200,),input_dtype = torch.LongTensor)

3、 ... and 、 Training models
Training Pytorch It usually requires the user to write a custom training cycle , The code style of the training cycle varies from person to person .
Yes 3 Class typical training cycle code style : Script form training cycle , Function form training cycle , Class form training cycle .
Here is a form of training cycle .
We imitate Keras A high-order model interface is defined Model, Realization fit, validate,predict, summary Method , It is equivalent to user-defined high-level API.
# Accuracy rate
def accuracy(y_pred,y_true):
y_pred = torch.where(y_pred>0.5,torch.ones_like(y_pred,dtype = torch.float32),
torch.zeros_like(y_pred,dtype = torch.float32))
acc = torch.mean(1-torch.abs(y_true-y_pred))
return acc
model.compile(loss_func = nn.BCELoss(),optimizer= torch.optim.Adagrad(model.parameters(),lr = 0.02),
metrics_dict={
"accuracy":accuracy})
# Sometimes the model does not converge during training , It needs to be tried a few more times
dfhistory = model.fit(20,dl_train,dl_val=dl_test,log_step_freq= 200)
Four 、 Evaluation model
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(dfhistory,"loss")

plot_metric(dfhistory,"accuracy")

# assessment
model.evaluate(dl_test)

5、 ... and 、 Using the model
model.predict(dl_test)
''' tensor([[0.0448], [0.9737], [0.3197], ..., [0.5752], [0.3216], [0.9635]]) '''
6、 ... and 、 Save the model
It is recommended to save the parameters Pytorch Model .
# Save model parameters
torch.save(model.state_dict(), "./data/model_parameter.pkl")
model_clone = Net()
model_clone.load_state_dict(torch.load("./data/model_parameter.pkl"))
model_clone.compile(loss_func = nn.BCELoss(),optimizer= torch.optim.Adagrad(model.parameters(),lr = 0.02),
metrics_dict={
"accuracy":accuracy})
# Evaluation model
model_clone.evaluate(dl_test)
tips:
This set of training 、 assessment 、 How to predict the model , Follow keras 10 Fen is the same , It's worth it torchkeras,nb! But in fact, there is a saying , We have seen the underlying source code two days ago
summary
- Data preprocessing
- Build a dictionary on the entire training set
- Build on the dictionary token
- structure dataset
- Word embedding layer nn.Embedding(num_embeddings = MAX_WORDS,embedding_dim = 3,padding_idx = 1) Parameters embedding_dim
- torchkeras Use
Dig a hole :torchtext Learn to use the tutorial .
边栏推荐
- @Transactional注解失效的场景
- Borui data and Sina Finance released the 2021 credit card industry development report
- Nmap and masscan have their own advantages and disadvantages. The basic commands are often mixed to increase output
- Brief analysis of ref nerf
- Monkey/ auto traverse test, integrate screen recording requirements
- MySQL——索引
- C程序设计的初步认识
- Global and Chinese market of telematics boxes 2022-2028: Research Report on technology, participants, trends, market size and share
- Yyds dry inventory hcie security Day12: concept of supplementary package filtering and security policy
- 抓包整理外篇——————autoResponder、composer 、statistics [ 三]
猜你喜欢

Après 90 ans, j'ai démissionné pour démarrer une entreprise et j'ai dit que j'allais détruire la base de données Cloud.

UC Berkeley proposes a multitask framework slip
使用dnSpy對無源碼EXE或DLL進行反編譯並且修改

Getting started with postman -- built-in dynamic parameters, custom parameters and assertions
Functions and differences between static and Const

How PHP gets all method names of objects

How PHP adds two numbers

Mysql - - Index

MySQL——JDBC

鹏城杯 WEB_WP
随机推荐
The "boss management manual" that is wildly spread all over the network (turn)
Day 9 HomeWrok-ClassHierarchyAnalysis
Talk about daily newspaper design - how to write a daily newspaper and what is the use of a daily newspaper?
Implementation principle of inheritance, encapsulation and polymorphism
使用dnSpy對無源碼EXE或DLL進行反編譯並且修改
[gd32l233c-start] 5. FLASH read / write - use internal flash to store data
Summary of common operation and maintenance commands
Hcie security Day12: supplement the concept of packet filtering and security policy
Global and Chinese market of telematics boxes 2022-2028: Research Report on technology, participants, trends, market size and share
Tidb's initial experience of ticdc6.0
Netfilter ARP log
How PHP drives mongodb
Scientific research document management Zotero
抓包整理外篇——————autoResponder、composer 、statistics [ 三]
Study diary: February 14th, 2022
@Scenario of transactional annotation invalidation
Yyds dry inventory Chapter 4 of getting started with MySQL: data types that can be stored in the data table
treevalue——Master Nested Data Like Tensor
"Designer universe" argument: Data Optimization in the design field ultimately falls on cost, safety and health | chinabrand.com org
Visiontransformer (I) -- embedded patched and word embedded