当前位置:网站首页>【load dataset】
【load dataset】
2022-07-05 11:34:00 【网络星空(luoc)】
文章目录

1.generate data txt file
# coding:utf-8
import os
''' 为数据集生成对应的txt文件 '''
train_txt_path = os.path.join("../..", "..", "Data", "train.txt")
train_dir = os.path.join("../..", "..", "Data", "train")
valid_txt_path = os.path.join("../..", "..", "Data", "valid.txt")
valid_dir = os.path.join("../..", "..", "Data", "valid")
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # 获取 train文件下各文件夹名称
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # 获取各类的文件夹 绝对路径
img_list = os.listdir(i_dir) # 获取类别文件夹下所有png图片的路径
for i in range(len(img_list)):
if not img_list[i].endswith('png'): # 若不是png文件,跳过
continue
label = img_list[i].split('_')[0]
img_path = os.path.join(i_dir, img_list[i])
line = img_path + ' ' + label + '\n'
f.write(line)
f.close()
if __name__ == '__main__':
gen_txt(train_txt_path, train_dir)
gen_txt(valid_txt_path, valid_dir)
2.MyDataset class
# coding: utf-8
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform=None, target_transform=None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs # 最主要就是要生成这个list, 然后DataLoader中给index,通过getitem读取图片数据
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB') # 像素值 0~255,在transfrom.totensor会除以255,使像素值变成 0~1
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.imgs)
3.instance MyDataset
train_data = MyDataset(txt_path=train_txt_path, transform=trainTransform)
valid_data = MyDataset(txt_path=valid_txt_path, transform=validTransform)
4.compute mean
# coding: utf-8
import numpy as np
import cv2
import random
import os
""" 随机挑选CNum张图片,进行按通道计算均值mean和标准差std 先将像素从0~255归一化至 0-1 再计算 """
train_txt_path = os.path.join("../..", "..", "Data/train.txt")
CNum = 2000 # 挑选多少图片进行计算
img_h, img_w = 32, 32
imgs = np.zeros([img_w, img_h, 3, 1])
means, stdevs = [], []
with open(train_txt_path, 'r') as f:
lines = f.readlines()
random.shuffle(lines) # shuffle , 随机挑选图片
for i in range(CNum):
img_path = lines[i].rstrip().split()[0]
img = cv2.imread(img_path)
img = cv2.resize(img, (img_h, img_w))
img = img[:, :, :, np.newaxis]
imgs = np.concatenate((imgs, img), axis=3)
print(i)
imgs = imgs.astype(np.float32)/255.
for i in range(3):
pixels = imgs[:,:,i,:].ravel() # 拉成一行
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
means.reverse() # BGR --> RGB
stdevs.reverse()
print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
print('transforms.Normalize(normMean = {}, normStd = {})'.format(means, stdevs))
5.DataLoder
# pytorch dateset
#import torchvision
#train_data = torchvision.datasets.CIFAR10(root = './data/', train = True, transform = trainTransform, download = True)
#valid_data = torchvision.datasets.CIFAR10(root = './data/', train = False, transform = trainTransform, download = True)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=train_bs, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=valid_bs)
6.net loss optimizer scheduler
#import torchvision.models as models
#net = models.vgg() # 创建一个网络
# ------------------------------------ step 3/5 : 定义损失函数和优化器 ------------------------------------
#criterion = nn.CrossEntropyLoss() # 选择损失函数
#optimizer = optim.SGD(net.parameters(), lr=lr_init, momentum=0.9, dampening=0.1) # 选择优化器
#scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc2_1 = nn.Linear(84, 40)
self.fc3 = nn.Linear(40, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc2_2(x))
x = self.fc3(x)
return x
# 定义权值初始化
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0, 0.01)
m.bias.data.zero_()
net = Net() # 创建一个网络
# ================================ #
# finetune 权值初始化
# ================================ #
# load params
pretrained_dict = torch.load('net_params.pkl')
# 获取当前网络的dict
net_state_dict = net.state_dict()
# 剔除不匹配的权值参数
pretrained_dict_1 = {
k: v for k, v in pretrained_dict.items() if k in net_state_dict}
# 更新新模型参数字典
net_state_dict.update(pretrained_dict_1)
# 将包含预训练模型参数的字典"放"到新模型中
net.load_state_dict(net_state_dict)
# ------------------------------------ step 3/5 : 定义损失函数和优化器 ------------------------------------
# ================================= #
# 按需设置学习率
# ================================= #
# 将fc3层的参数从原始网络参数中剔除
ignored_params = list(map(id, net.fc3.parameters()))
base_params = filter(lambda p: id(p) not in ignored_params, net.parameters())
# 为fc3层设置需要的学习率
optimizer = optim.SGD([
{
'params': base_params},
{
'params': net.fc3.parameters(), 'lr': lr_init*10}], lr_init, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss() # 选择损失函数
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
7. train
在这里插入代码片
边栏推荐
- pytorch-softmax回归
- 跨境电商是啥意思?主要是做什么的?业务模式有哪些?
- COMSOL -- three-dimensional graphics random drawing -- rotation
- 查看多台机器所有进程
- 技术管理进阶——什么是管理者之体力、脑力、心力
- Advanced technology management - what is the physical, mental and mental strength of managers
- How can edge computing be combined with the Internet of things?
- Go language learning notes - first acquaintance with go language
- pytorch-权重衰退(weight decay)和丢弃法(dropout)
- 如何让你的产品越贵越好卖
猜你喜欢
splunk配置163邮箱告警
COMSOL -- establishment of geometric model -- establishment of two-dimensional graphics
COMSOL -- three-dimensional graphics random drawing -- rotation

11. (map data section) how to download and use OSM data
comsol--三维图形随便画----回转
![[crawler] Charles unknown error](/img/82/c36b225d0502f67cd04225f39de145.png)
[crawler] Charles unknown error
12. (map data) cesium city building map
iTOP-3568开发板NPU使用安装RKNN Toolkit Lite2
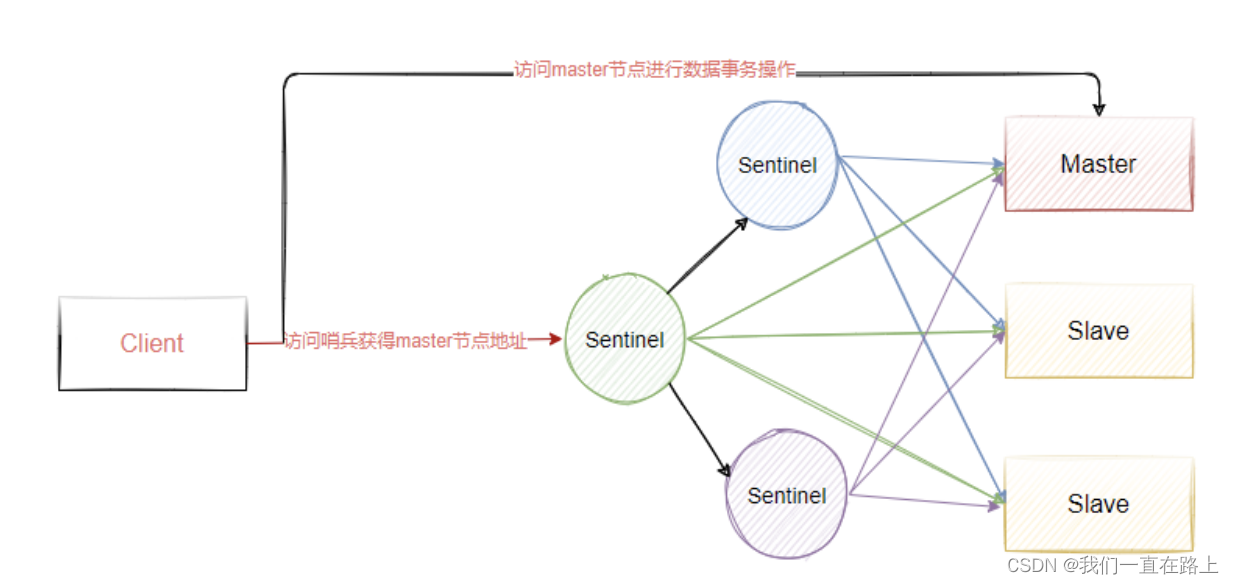
redis主从中的Master自动选举之Sentinel哨兵机制
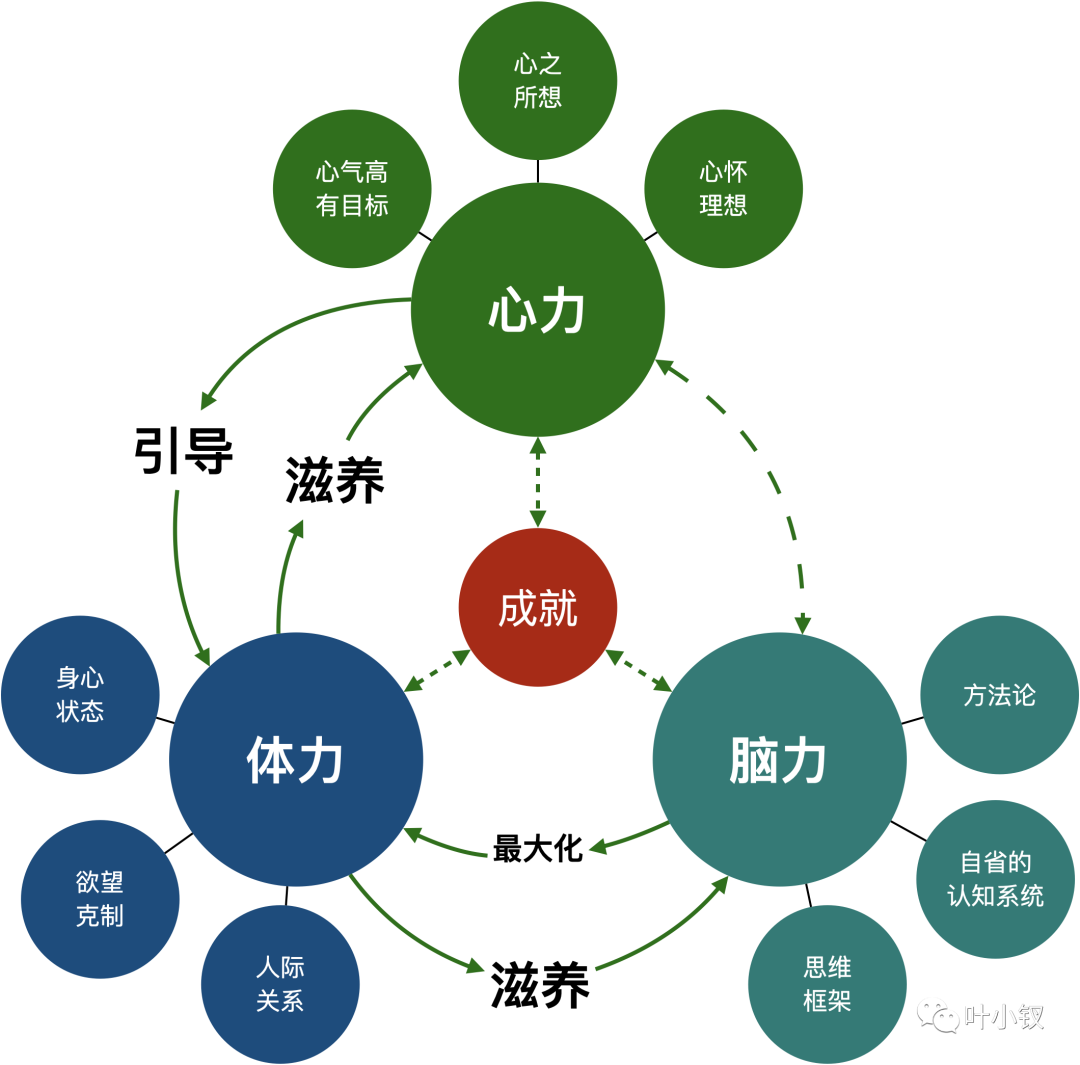
技术管理进阶——什么是管理者之体力、脑力、心力
随机推荐
Zcmu--1390: queue problem (1)
View all processes of multiple machines
[leetcode] wild card matching
13.(地图数据篇)百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换
Go language learning notes - first acquaintance with go language
7 themes and 9 technology masters! Dragon Dragon lecture hall hard core live broadcast preview in July, see you tomorrow
阻止浏览器后退操作
Programmers are involved and maintain industry competitiveness
龙蜥社区第九次运营委员会会议顺利召开
Go language learning notes - analyze the first program
COMSOL -- 3D casual painting -- sweeping
[there may be no default font]warning: imagettfbbox() [function.imagettfbbox]: invalid font filename
spark调优(一):从hql转向代码
iTOP-3568开发板NPU使用安装RKNN Toolkit Lite2
shell脚本文件遍历 str转数组 字符串拼接
FFmpeg调用avformat_open_input时返回错误 -22(Invalid argument)
C operation XML file
Ziguang zhanrui's first 5g R17 IOT NTN satellite in the world has been measured on the Internet of things
Redis集群的重定向
ACID事务理论