当前位置:网站首页>Entropy and full connection layer
Entropy and full connection layer
2022-07-03 23:50:00 【onlywishes】
entropy

Entropy is the expected value of information , It is a measure of the certainty of random variables . The greater the entropy , The more uncertain the value of the variable , Otherwise, the more certain it is .

import torch
a = torch.full([4],1/4.)
print(-(a*torch.log2(a)).sum()) #a,b,c Suppose four options choose the right probability
#tensor(2.) # The more obvious entropy is, the less unexpected it is , The greater the entropy, the greater the uncertainty
b = torch.tensor([0.1,0.1,0.1,0.7])
print(-(b*torch.log2(b)).sum())
#tensor(1.3568)
c = torch.tensor([0.001,0.001,0.001,0.999])
print(-(c*torch.log2(c)).sum())
#tensor(0.0313)Cross entropy

The relative entropy is also known as KL The divergence ,KL distance , It's a measure of the distance between two random distributions . Write it down as DKL(p||q)DKL(p||q). It measures when the true distribution is p when , Hypothetical distribution q Invalidity of
For two distributions p( Real sample distribution ),q( Model to be estimated ) All are (0-1) Yes
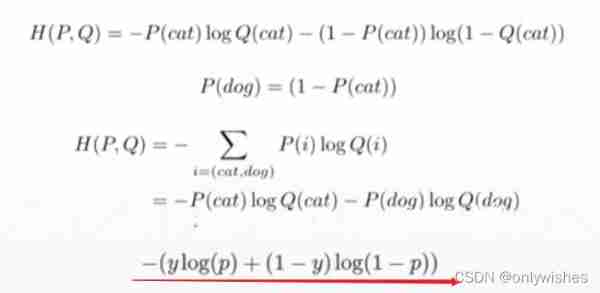
Yes H(p,q)= H(p) + Dkl(p|q ) , When p When known , You can put H(p) As a constant , At this time, cross entropy and KL Distance is equivalent in behavior , All reflect the distribution p,q The degree of similarity . Minimizing cross entropy is equal to minimizing KL distance . They will all be in p=q Get the minimum H(p)(p=q when KL A distance of 0)

Fully connected layer
nn.Linear(input,output,bias=TRUE)
It contains w The transpose , and b( Personal understanding )
Used to set up the full connection layer in the network , It should be noted that the input and output of the full connection layer are two-dimensional tensors
The general shape is [batch_size, size], Unlike the convolution layer, the input and output are required to be four-dimensional tensors
input: Enter the size of the two-dimensional tensor
output: Output the size of the two-dimensional tensor
If not used nn.Linear, Create two dimensions tensor The input and output of is the opposite , namely 【output,input】 To transpose
import torch
import torch.nn as nn
x = torch.randn(1,784)
print(x.shape) #torch.Size([1, 784])
layer1 = nn.Linear(784,200) # The first is in, The second is out
layer2 = nn.Linear(200,200)
layer3 = nn.Linear(200,10)
x = layer1(x)
print(x.shape) #torch.Size([1, 200]) , Dimension reduction
x = layer2(x)
print(x.shape) #torch.Size([1, 200]) , feature extraction
x = layer3(x)
print(x.shape) #torch.Size([1, 10]) , Reduced to 10nn.Relu vs F.relu

nn.Relu Class methods are used ,F.relu The function method is used , Pay attention to the case of letters
relu Medium inplace The default is FALSE
inplace = False when , The value of the input object will not be modified , Instead, it returns a newly created object
inplace = True when , Will modify the value of the input object , So the printed object has the same storage address , Save space and time for repeated application and memory release , Just pass the original address , More efficient
import torch
import torch.nn as nn
from torch.nn import functional as F
x = torch.randn(1,10)
x = F.relu(x,inplace=True)
print(x) #tensor([[0.0000, 0.0000, 0.0000, 0.0000, 0.9487, 1.0720, 0.0000, 0.0000, 0.3956, 0.0000]])
layer = nn.ReLU()
x = layer(x)
print(x) #tensor([[0.0000, 0.0000, 0.0000, 0.0000, 0.9487, 1.0720, 0.0000, 0.0000, 0.3956, 0.0000]])
About activation functions relu
sigmoid and tanh yes “ Saturation activation function ”, and ReLU And its variants are “ Unsaturated activation function ”. Use “ Unsaturated activation function ” There are two advantages :
1.“ Unsaturated activation function ” Can solve the so-called “ The gradient disappears ” problem .
2. It can speed up convergence .
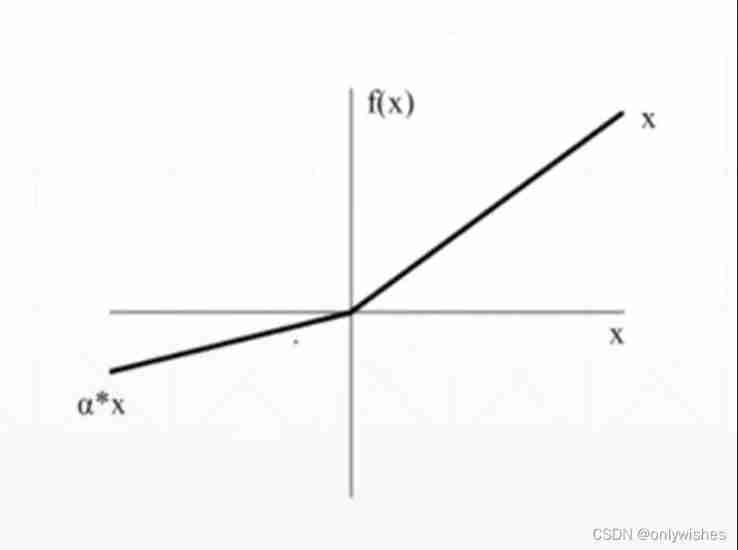
leaky relu
ReLU Is to set all negative values to zero ,Leaky ReLU Is to give all negative values a non-zero slope , Default 0.01
Usage and relu identical , Angle can be set
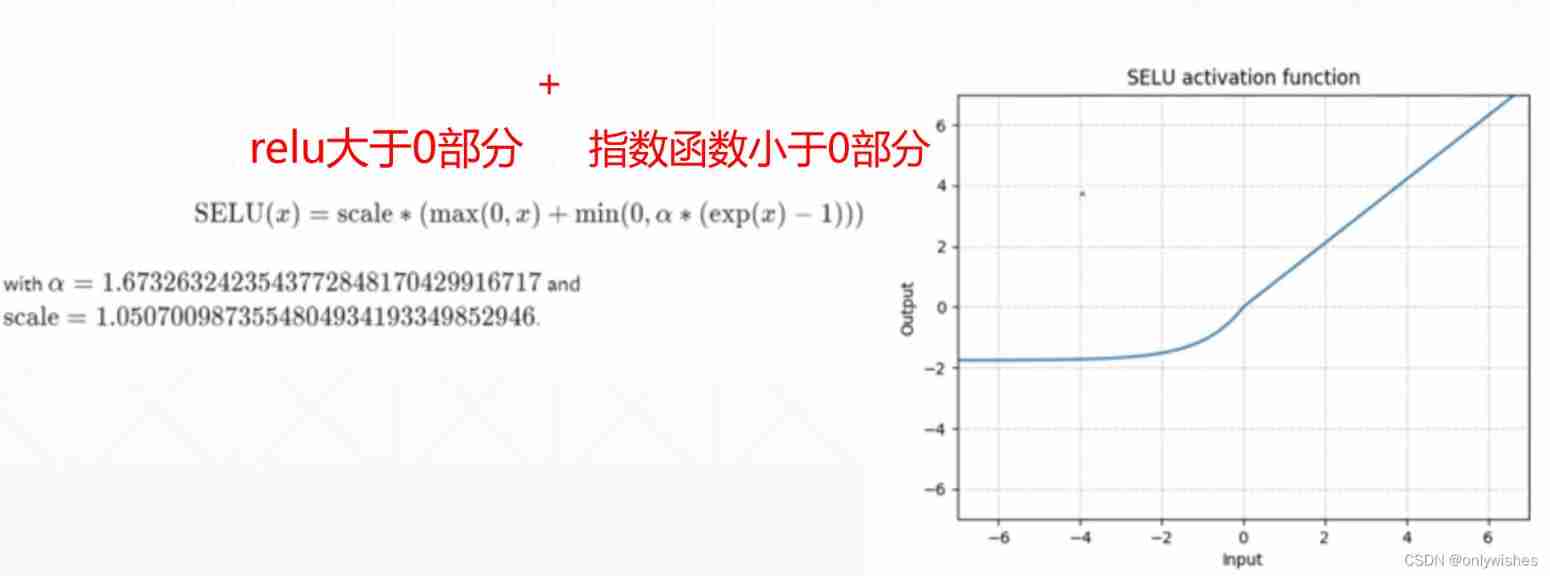
SELU function
It's a composite function
Softplus
take relu function x Axis approach 0 Partial smoothing

Use GPU Speed up
device = torch.device('cuda:0') # Use equipment , You can choose to move what you need to calculate to the equipment you need .
# Will be accelerated to GPU
o = nn.CrossEntropyLoss().to(device) # Use .to() Method specification GPU Speed up , Will return inference, His type depends on the original type
t = nn.CrossEntropyLoss().cuda() # Use .cuda() Method
Calculation accuracy
logits = torch.rand(4,10)
pred = F.softmax(logits,dim=1)
pred_label = pred.argmax(dim=1)
print(pred_label) #tensor([5, 5, 2, 6])
p = logits.argmax(dim=1)
print(p) #tensor([5, 5, 2, 6])
label = torch.tensor([3,9,2,0])
correct = torch.eq(pred_label,label) #
print(correct) #tensor([False, False, True, False])
i = correct.sum().float().item()/4 # Calculation accuracy ,item Get the elements inside
print(i) #0.25边栏推荐
- P1656 bombing Railway
- 2022 chemical automation control instrument examination content and chemical automation control instrument simulation examination
- Make small tip
- Design of logic level conversion in high speed circuit
- Gossip about redis source code 83
- I would like to ask how the top ten securities firms open accounts? Is it safe to open an account online?
- Sword finger offer day 4 (Sword finger offer 03. duplicate numbers in the array, sword finger offer 53 - I. find the number I in the sorted array, and the missing numbers in sword finger offer 53 - ii
- Idea integrates Microsoft TFs plug-in
- 2020.2.14
- Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
猜你喜欢
Solve the problem that the kaggle account registration does not display the verification code
Unity shader visualizer shader graph

Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?

Tencent interview: can you find the number of 1 in binary?
Selenium check box
EPF: a fuzzy testing framework for network protocols based on evolution, protocol awareness and coverage guidance

Interpretation of corolla sub low configuration, three cylinder power configuration, CVT fuel saving and smooth, safety configuration is in place
Yyds dry goods inventory three JS source code interpretation - getobjectbyproperty method

Introducing Software Testing

NLP Chinese corpus project: large scale Chinese natural language processing corpus
随机推荐
Gossip about redis source code 81
Schematic diagram of crystal oscillator clock and PCB Design Guide
The first game of the new year, many bug awards submitted
Recursive least square adjustment
Gorilla/mux framework (RK boot): add tracing Middleware
Private project practice sharing populate joint query in mongoose makes the template unable to render - solve the error message: syntaxerror: unexpected token r in JSON at
Similarities and differences of text similarity between Jaccard and cosine
D28:maximum sum (maximum sum, translation)
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Iclr2022: how does AI recognize "things I haven't seen"?
Idea set class header comments
JarPath
The difference between single power amplifier and dual power amplifier
Gossip about redis source code 83
[note] IPC traditional interprocess communication and binder interprocess communication principle
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Selenium library 4.5.0 keyword explanation (4)
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
P1629 postman delivering letter
Interesting 10 CMD commands