当前位置:网站首页>数学之美 第六章——信息的度量和作用
数学之美 第六章——信息的度量和作用
2022-08-03 19:58:00 【拾柒要上岸!】
目录
信息熵
- 提出者
- 1948年,香农在他著名的论文“通信的数学原理”中提出了“信息嫡”
- 用途
- 解决了信息的度量问题,并且量化出信息的作用。
- 信息量
- 一条信息的信息量与其不确定性有着直接的关系。
- 比如说,我们要搞清楚一件非常非常不确定的事,或是我们一无所知的事情,就需要了解大量的信息。相反,如果已对某件事了解较多,则不需要太多的信息就能把它搞清楚。所以,从这个角度来看,可以认为,信息量就等于不确定性的多少。
- 单位:比特
- 定义:

- 信息量的比特数和所有可能情况的对数函数log有关。( log32 = 5, log64 = 6。)
- 变量的不确定性越大,嫡也就越大,要把它搞清楚,所需信息量也就越大。
- 例1:
- 哪支球队是冠军
- 等概率情况下
- 可以把球队编上号,从1到32,然后提问:“冠军球队在1—16号中吗?”假如他告诉我猜对了,我会接着问:“冠军在1—8号中吗?”假如他告诉我猜错了,我自然知道冠军队在9—16号中。这样只需要5次,我就能知道哪支球队是冠军。所以,谁是世界杯冠军这条消息的信息量只值5元钱。即5比特
- 不等概率情况下
- 有些读者会发现实际上可能不需要猜5次就能猜出谁是冠军,因为像西班牙、巴西、德国、意大利这样的球队夺得冠军的可能性比日本、南非、韩国等球队大得多。因此,第一次猜测时不需要把32支球队等分成两个组,而可以把少数几支最可能的球队分成一组,把其他球队分成另一组。然后猜冠军球队是否在那几支热门队中。重复这样的过程,根据夺冠概率对余下候选球队分组,直至找到冠军队。这样,也许3次或4次就猜出结果。因此,当每支球队夺冠的可能性(概率)不等时,“谁是世界杯冠军”的信息量比5比特少。
- 准确信息量
- 等概率情况下
- 哪支球队是冠军
- 例2:
- 一本50万字的中文书平均有多少信息量。
- 信息熵
- 假如每个字等概率
- 那么大约需要13比特(即13位二进制数)表示一个汉字。
- 不考虑上下文的相关性,而只考虑每个汉字的独立概率
- 每个汉字的信息嫡大约也只有8—9比特
- 考虑上下文相关性
- 每个汉字的信息嫡就只有5比特左右
- 一本50万字的中文书,信息量大约是250万比特
- 每个汉字的信息嫡就只有5比特左右
- 假如每个字等概率
- 冗余度
压缩文件的大小- 采用较好的算法进行压缩,整本书可以存成一个320KB的文件。
- 如果直接用两字节的国标编码存储这本书,大约需要1MB大小,是压缩文件的3倍。
- 如果一本书重复的内容很多,它的信息量就小,冗余度就大。
- 不同语言的冗余度差别很大,而汉语在所有语言中冗余度是相对小的。
- 信息熵
- 一本50万字的中文书平均有多少信息量。
- 一条信息的信息量与其不确定性有着直接的关系。

信息的作用
- 消除系统的不确定性
- 信息是消除系统不确定性的唯一办法(在没有获得任何信息前,一个系统就像是一个黑盒子,引入信息,就可以了解黑盒子系统的内部结构)

- 一个事物内部会存有随机性,也就是不确定性,假定为U,信息为I
- I >U
- 从外部消除这个不确定性
- I<U
- 这些信息可以消除一部分不确定性,也就是说新的不确定性
- 这些信息可以消除一部分不确定性,也就是说新的不确定性
- 如果没有信息﹐任何公式或者数字的游戏都无法排除不确定性。
- I >U
- 一个事物内部会存有随机性,也就是不确定性,假定为U,信息为I

条件熵
- 知道的信息越多,随机事件的不确定性就越小
- 也指已知某个变量之后,变量X的嫡
- X的熵
- 定义在Y的条件下的X的熵
- 定义在Y,Z条件下的X的熵
- X的熵



互信息
- 提出者
- 香农
- 概念
- 两个随机事件“相关性”的量化度量
- 定义
- 假定有两个随机事件X和Y
- 随机事件X的不确定性或者说嫡H(X)在知道随机事件Y条件下的不确定性,或者说条件嫡H(X|Y)之间的差异,即
- 互信息是一个取值在0到min(H(X),H(Y))之间的函数
- 当X和Y完全相关时,它的取值是H(X),同时H(X)=H(Y)
- 当二者完全无关时,它的取值是0。
- 假定有两个随机事件X和Y
- 应用
- 度量一些语言现象的相关性
- 机器翻译中词义的二义性
- 例如"bush"这个词既可被翻译为灌木丛,也可以被翻译为美国总统布什。利用互信息的方法是,分别从大量文本中找与“布什"和“灌木丛"各自互信息最大的词语,在翻译时再看上下文哪一类的相关词更多,即可确认翻译为哪种意思。
- 迁移学习
- 强化学习迁移的一个阻碍是,两个不同任务之间的动作空间、状态空间等不一致。通过互信息可以对不同任务的空间进行转化,达到迁移强化学习的目的

相对熵
- 用来衡量相关性,但和变量的互信息不同,它用来衡量两个取值为正数的函数的相似性
- 定义
- 相对熵不对称
- 为了让它对称,詹森和香农提出一种新的相对嫡的计算方法,将上面的不等式两边取平均,即

- 结论
- 1.对于两个完全相同的函数,它们的相对嫡等于零。
- 2.相对嫡越大,两个函数差异越大;反之,相对嫡越小,两个函数差异越小。
- 3.对于概率分布或者概率密度函数,如果取值均大于零,相对嫡可以度量两个随机分布的差异性。
- 应用
- 信号处理
- 如果两个随机信号,它们的相对嫡越小,说明这两个信号越接近,否则信号的差异越大。
- 衡量两段信息的相似程度
- 比如说如果一篇文章是照抄或者改写另一篇,那么这两篇文章中词频分布的相对嫡就非常小,接近于零。
- 在Google的自动问答系统中,我们采用了上面的詹森–香农度量来衡量两个答案的相似性。
- 衡量两个常用词(在语法和语义上)在不同文本中的概率分布,看它们是否同义
- 词频率–逆向文档频率
- 信号处理



联系
- 对于统计语言模型,模型越好,预测得越准,说明当前文字的不确定性越小。因此统计语言模型的好坏可以直接用信息嫡来进行衡量,信息嫡正是对于不确定性的衡量。当有了上下文条件时,相关条件也会对帮助消除不确定性,因此可以用条件嫡来衡量。如再考虑训练语料和真实应用文本的偏差,就需再引用相对嫡的概念。
边栏推荐
- tensorflow-gpu2.4.1安装配置详细步骤
- matplotlib画polygon, circle
- 调用EasyCVR接口时视频流请求出现404,并报错SSL Error,是什么原因?
- MySQL Basics
- Hinton2022年RobotBrains访谈记录
- Jingdong cloud released a new generation of distributed database StarDB 5.0
- Matlab paper illustration drawing template No. 42 - bubble matrix diagram (correlation coefficient matrix diagram)
- 群辉查看硬盘存储占用的方式
- 那些年我写过的语言
- FreeRTOS Intermediate
猜你喜欢
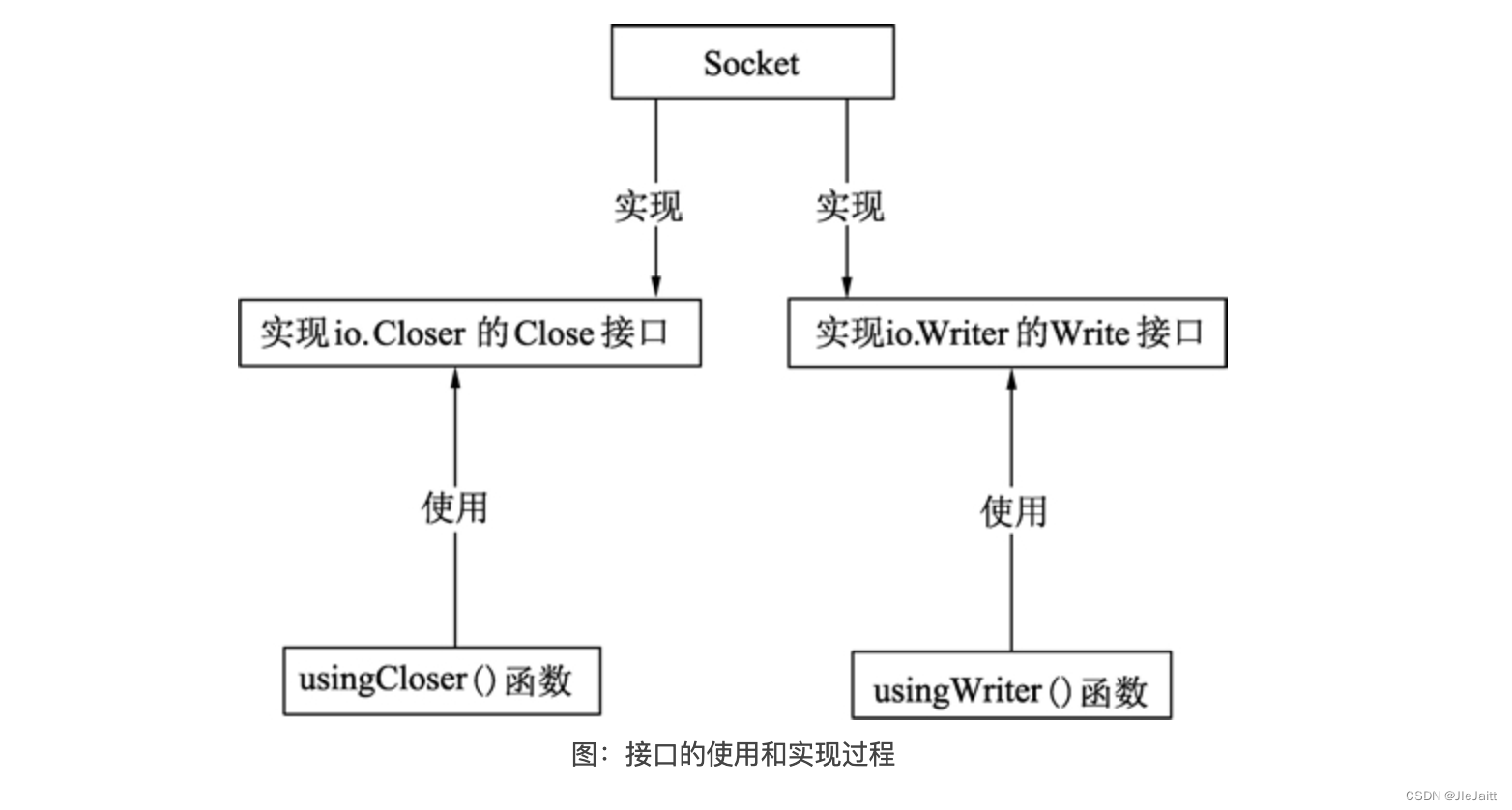
Go语言类型与接口的关系
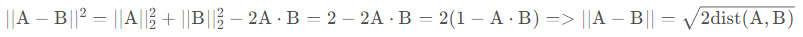
余弦距离介绍
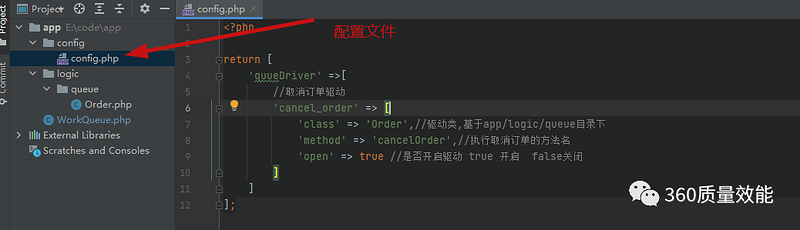
利用 rpush 和 blpop 实现 Redis 消息队列

建模该从哪一步开始?给你分析,给零基础的你一些学习建议
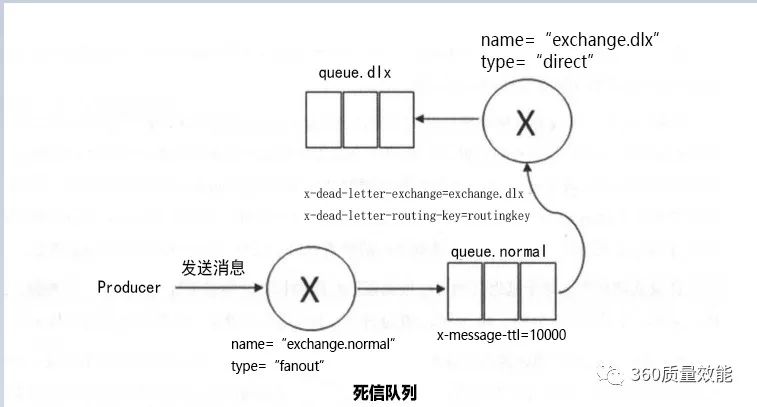
Golang死信队列的使用
ECCV2022 | 用于视频问题回答的视频图Transformer
Node version switching tool NVM and npm source manager nrm
RNA-ATTO 390|RNA-ATTO 425|RNA-ATTO 465|RNA-ATTO 488|RNA-ATTO 495|RNA-ATTO 520近红外荧光染料标记核糖核酸RNA

高效目标检测:动态候选较大程度提升检测精度(附论文下载)

调用EasyCVR接口时视频流请求出现404,并报错SSL Error,是什么原因?
随机推荐
多模态 参考资料汇总
微导纳米IPO过会:年营收4.28亿 君联与高瓴是股东
ECCV 2022 Oral | 满分论文!视频实例分割新SOTA: IDOL
Go语言类型与接口的关系
【leetcode】剑指 Offer II 009. 乘积小于 K 的子数组(滑动窗口、双指针)
php截取中文字符串实例
1161 最大层内元素和——Leetcode天天刷【BFS】(2022.7.31)
Go语言为任意类型添加方法
Kettle 读取 Excel 数据输出到 Oracle 详解
【飞控开发高级教程4】疯壳·开源编队无人机-360 度翻滚
net-snmp私有mib动态加载到snmpd
Statistical machine learning 】 【 linear regression model
LeetCode 622. Designing Circular Queues
In-depth understanding of JVM-memory structure
信使mRNA甲基化偶联3-甲基胞嘧啶(m3C)|mRNA-m3C
剑指 Offer II 044. 二叉树每层的最大值-dfs法
Line the last time the JVM FullGC make didn't sleep all night, collapse
【leetcode】剑指 Offer II 008. 和大于等于 target 的最短子数组(滑动窗口,双指针)
Detailed steps for tensorflow-gpu2.4.1 installation and configuration
傅里叶变换(深入浅出)