当前位置:网站首页>[technical dry goods] how to ensure the idempotency of the interface?
[technical dry goods] how to ensure the idempotency of the interface?
2022-07-25 20:40:00 【Full stack programmer webmaster】
Hello everyone , I meet you again , I'm the king of the whole stack .
Preface
Interface idempotence problem , For developers , It's a public issue that has nothing to do with language . This article shares some practical solutions to these problems , Most of the content I have practiced in the project , A reference for those in need .
I don't know if you've ever come across these scenes :
- Sometimes we're filling in certain
form Formswhen , The Save button was accidentally pressed twice , There are two duplicate data in the table , It's just id Dissimilarity . - We are in the project to solve
Interface timeoutproblem , It's usually introducedRetry mechanism. The first request interface timed out , The requester failed to get the returned result in time ( At this point, it may have been successful ), To avoid returning incorrect results ( In this case, it is impossible to return to failure directly ?), The request is then retried several times , This also creates duplicate data . - mq When a consumer reads a message , Sometimes it reads
Repeat the message( As for the reason, let's not say , Interested partners , You can talk to me in private ), If not handled well , It also produces duplicate data .
you 're right , These are all idempotent problems .
Interface idempotence The result of one request or multiple requests is the result of the same operation , It won't have side effects due to multiple clicks .
This kind of problem often occurs in the interface :
insertoperation , In this case, multiple requests , There may be duplicate data .updateoperation , If you just update the data , such as :update user set status=1 where id=1, There is no problem . If there's a calculation , such as :update user set status=status+1 where id=1, In this case, multiple requests , May cause data errors .
So how do we guarantee the idempotency of interfaces ? This article will tell you the answer .
1. insert before select
Usually , In the interface where the data is stored , We want to prevent duplicate data , Usually in insert front , First, according to name or code Field select Here's the data . If the data already exists , execute update operation , If it doesn't exist , To perform insert operation .
This solution may be when we are usually preventing duplicate data , The most used solution . But this scheme is not suitable for concurrent scenarios , In a concurrent scenario , It should be used together with other schemes , Otherwise, duplicate data will also be generated . I'll mention it here , It's to avoid people stepping on the pit .
2. Add pessimism lock
In the payment scenario , user A My account balance is 150 element , I want to transfer out 100 element , Under normal circumstances, users A All that's left is 50 element . In general ,sql That's true :
update user amount = amount-100 where id=123;If the same request appears more than once , May cause users to A The balance becomes negative . This situation , user A I'm going to cry . At the same time , System developers may also cry , Because it's a very serious system bug.
To solve this problem , You can put a pessimistic lock on it , Will the user A That line of data is locked , Only one request is allowed to acquire a lock at the same time , Update data , Other requests wait .
In general, it is through the following sql Lock single line data :
select * from user id=123 for update;The specific process is as follows :
Specific steps :
- Multiple requests based on id Query user information .
- Judge whether the balance is insufficient 100, If the balance is insufficient , Then return the insufficient balance directly .
- If the balance is sufficient , Through for update Query user information again , And try to get the lock .
- Only the first request can get the row lock , The rest have no requests to acquire locks , Then wait for the next chance to acquire the lock .
- After the first request gets the lock , Judge whether the balance is insufficient 100, If the balance is enough , Is to update operation .
- If the balance is insufficient , The description is a repeat request , Then directly return to success .
Here's the thing to watch out for : If you are using mysql database , The storage engine must use innodb, Because it supports transactions . Besides , here id Fields must be primary keys or unique indexes , Or it'll lock the whole watch .
Pessimistic locks need to lock a row of data during the same transaction operation , If the transaction takes a long time , There will be a lot of requests waiting , Affect interface performance .
Besides , It's hard for the interface to guarantee the same return value for every request , So it's not suitable for idempotent design scenarios , But it can be used in anti heavy scenes .
By the way, here , Anti weight design and Idempotent design , There is a difference . Anti duplication design is mainly to avoid duplicate data , There are not many requirements for interface return . Idempotent design can avoid duplicate data , It also requires that each request return the same result .
3. Lock in optimism
Since pessimistic locks have performance problems , To improve interface performance , We can use the optimistic lock . You need to add a timestamp perhaps version Field , Here we use version Field as an example .
Query the data before updating it :
select id,amount,version from user id=123; If the data exists , Let's say we find version be equal to 1, Reuse id and version Fields update data as query criteria :
update user set amount=amount+100,version=version+1
where id=123 and version=1; While updating the data version+1, Then judge this time update The number of rows affected by the operation , If it is greater than 0, The update is successful , If it is equal to 0, This update does not change the data .
Because of the first request version be equal to 1 It can be successful , After successful operation version become 2 了 . At this time, if concurrent requests come over , Do the same thing again sql:
update user set amount=amount+100,version=version+1
where id=123 and version=1; The update Operations don't really update data , Final sql The number of rows affected by the execution result of is 0, because version Has become a 2 了 ,where Medium version=1 It's definitely not going to meet the conditions . But to ensure interface idempotency , Interface can return success directly , because version The value has been modified , Then we must have succeeded once before , It's followed by repeated requests .
The specific process is as follows :
Specific steps :
- First, according to id Query user information , contain version Field
- according to id and version Field value as where Parameters of the condition , Update user information , meanwhile version+1
- Determine the number of rows affected by the operation , If it affects 1 That's ok , It is a request , You can do other data operations .
- If it affects 0 That's ok , The description is a repeat request , Then directly return to success .
4. Add unique index
In most cases , To prevent duplicate data , We all add a unique index to the table , This is a very simple , And effective solutions .
alter table `order` add UNIQUE KEY `un_code` (`code`); With a unique index , The first request data can be inserted successfully . But the same request later , When inserting data, it will report Duplicate entry '002' for key 'order.un_code abnormal , Indicates that there is a conflict in the unique index .
Although throwing anomalies has no effect on the data , No false data . But to ensure interface idempotency , We need to catch the exception , Then return to success .
If it is java The program needs to capture :DuplicateKeyException abnormal , If used spring The framework also needs to capture :MySQLIntegrityConstraintViolationException abnormal .
The specific flow chart is as follows :
Specific steps :
- The user initiates the request through the browser , The server collects data .
- Insert the data into mysql
- Judge whether the execution is successful , If it works , Then operate other data ( There may be other business logic ).
- If execution fails , Catch unique index conflict exception , Go straight back to success .
5. Build a weight watch
Sometimes not all scenarios in the table are allowed to generate duplicate data , Only certain scenes are not allowed . Now , Add a unique index directly to the table , It's obviously not appropriate .
In this case , We can go through Build a weight watch To solve the problem .
The table can contain only two fields :id and unique index , The unique index can be multiple fields, such as :name、code And so on , for example :susan_0001.
The specific flow chart is as follows :
Specific steps :
- The user initiates the request through the browser , The server collects data .
- Insert the data into mysql Counterweight gauge
- Judge whether the execution is successful , If it works , Then do mysql Other data operations ( There may be other business logic ).
- If execution fails , Catch unique index conflict exception , Go straight back to success .
Here's the thing to watch out for : The anti duplication table and the business table must be in the same database , And the operation should be in the same transaction .
6. According to the state machine
Most of the time, business tables are stateful , For example, the order form has :1- Place an order 、2- Paid 、3- complete 、4- Revocation, etc . If the values of these states are regular , According to the business node is just from small to large , We can use it to ensure the idempotency of the interface .
If id=123 Your order status is Paid , Now it's going to be complete state .
update `order` set status=3 where id=123 and status=2; On the first request , The status of the order is Paid , The value is 2, So the update Statement can update data normally ,sql The number of rows affected by the execution result is 1, The order status becomes 3.
The same request came later , Do the same thing again sql when , Because the order status becomes 3, Reuse status=2 As a condition , Unable to find the data that needs to be updated , So the final sql The number of rows affected by the execution result is 0, It doesn't really update the data . But to ensure interface idempotency , The number of rows affected is 0 when , Interface can also return success directly .
The specific flow chart is as follows :
Specific steps :
- The user initiates the request through the browser , The server collects data .
- according to id And the current state as conditions , Update to the next state
- Determine the number of rows affected by the operation , If it affects 1 That's ok , Indicates that the current operation is successful , You can do other data operations .
- If it affects 0 That's ok , The description is a repeat request , Go straight back to success .
The main special attention is , The scheme is limited to the ones to be updated
The table has status fields, And it's just about to be updatedStatus fieldThis special case of , Not all scenarios apply .
7. Add distribution lock
As a matter of fact, what I mentioned before Add unique index perhaps Add weight watch , The essence is to use database Of Distributed lock , It is also a kind of distributed lock . But because of Database distributed lock My performance is not very good , We can use :redis or zookeeper.
In view of the fact that many companies now use the distributed configuration center apollo or nacos, It's rarely used zookeeper 了 , We use redis As an example, introduce distributed lock .
At present, there are mainly three ways to achieve redis Distributed locks for :
- setNx command
- set command
- Redission frame
Each has its own advantages and disadvantages , I won't talk about the specific implementation details , Interested friends can chat with me on wechat .
The specific flow chart is as follows :
Specific steps :
- The user initiates the request through the browser , The server will collect data , And generate the order number code As the only business field .
- Use redis Of set command , Put the order code Set to redis in , At the same time, set the timeout .
- Judge whether the setting is successful , If the setting is successful , The description is the first request , Then data operation is performed .
- If the setup fails , The description is a repeat request , Then directly return to success .
Here's the thing to watch out for : Distributed locks must have a reasonable expiration time , If the setting is too short , Unable to effectively prevent duplicate requests . If the setting is too long , It could be wasted
redisStorage space , It depends on the actual business situation .
8. obtain token
In addition to the above options , There's a last use token The plan . This scheme is a little different from all previous schemes , It takes two requests to complete a business operation .
- First request for
token - Second request with this
token, Complete business operations .
The specific flow chart is as follows :
First step , First get token.
The second step , Do specific business operations .
Specific steps :
- When the user visits the page , The browser automatically initiates the acquisition token request .
- Server generation token, Save to redis in , And then back to the browser .
- When a user makes a request through a browser , Take with you token.
- stay redis Query the token Whether there is , If it doesn't exist , The description is the first request , Do the following data operation .
- If there is , The description is a repeat request , Then directly return to success .
- stay redis in token After the expiration time , Automatically deleted .
The above scheme is designed for idempotent .
If it's weight proof design , The flow chart needs to be changed :
Here's the thing to watch out for :token It has to be the only one in the world .
Publisher : Full stack programmer stack length , Reprint please indicate the source :https://javaforall.cn/111566.html Link to the original text :https://javaforall.cn
边栏推荐
- Leetcode-6130: designing digital container systems
- Technology cloud report: what is the difference between zero trust and SASE? The answer is not really important
- During the interview, I was asked how to remove the weight of MySQL, and who else wouldn't?
- leetcode-6130:设计数字容器系统
- Leetcode-6126: designing a food scoring system
- [today in history] July 3: ergonomic standards act; The birth of pioneers in the field of consumer electronics; Ubisoft releases uplay
- Open source SPL enhances mangodb computing
- How to realize reliable transmission with UDP?
- Vulnhub | dc: 5 | [actual combat]
- MPI学习笔记(二):矩阵相乘的两种实现方法
猜你喜欢

Working principle of radar water level gauge and precautions for installation and maintenance

LeetCode通关:哈希表六连,这个还真有点简单
Has baozi ever played in the multi merchant system?

【高等数学】【1】函数、极限、连续

leetcode-919:完全二叉树插入器

Leetcode-6125: equal row and column pairs
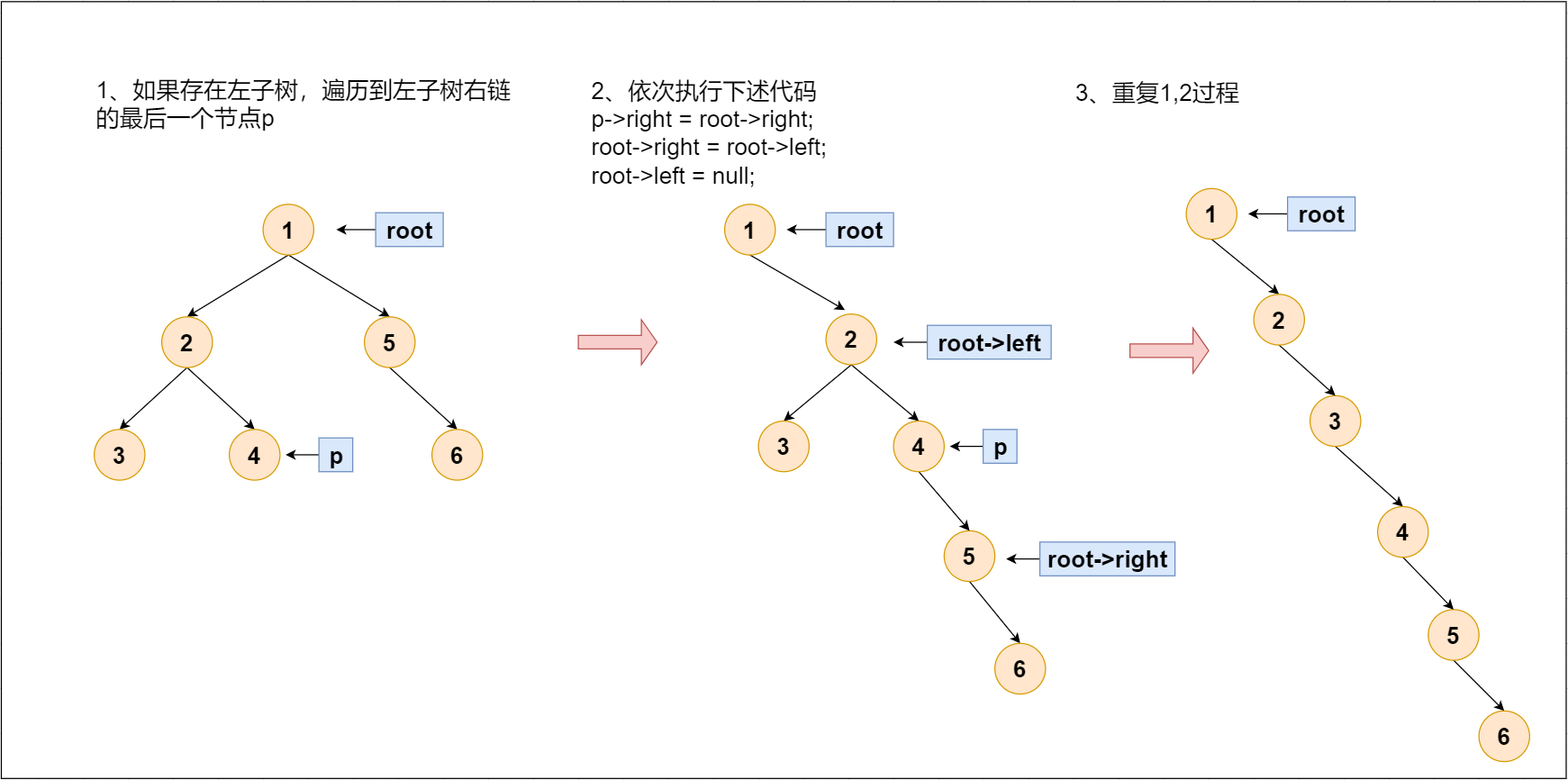
Leetcode-114: expand binary tree into linked list
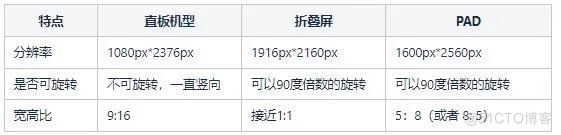
Vivo official website app full model UI adaptation scheme
Leetcode customs clearance: hash table six, this is really a little simple

【高等数学】【5】定积分及应用
随机推荐
Vivo official website app full model UI adaptation scheme
[workplace rules] it workplace rules | poor performance
How much memory does bitmap occupy in the development of IM instant messaging?
Compilation and operation of program
Leetcode-919: complete binary tree inserter
Unity VS—— VS中默认调试为启动而不是附加到Unity调试
Embedded development: embedded foundation -- threads and tasks
[today in history] July 4: the first e-book came out; The inventor of magnetic stripe card was born; Palm computer pioneer was born
476-82(322、64、2、46、62、114)
Introduction to several scenarios involving programming operation of Excel in SAP implementation project
leetcode-919:完全二叉树插入器
Cloud native, Intel arch and cloud native secret computing three sig online sharing! See you today | issues 32-34
Go language go language built-in container
[MCU] 51 MCU burning those things
RF, gbdt, xgboost feature selection methods "recommended collection"
Interpretation of filter execution sequence source code in sprigboot
Is QQ 32-bit or 64 bit software (where to see whether the computer is 32-bit or 64 bit)
Brush questions with binary tree (4)
【TensorRT】动态batch进行推理
JS作用域与作用域链