当前位置:网站首页>Titanic 预测问题
Titanic 预测问题
2022-07-31 06:01:00 【西岸贤】
前言
本文的主要内容是 Titanic 预测问题,文中包括数据集介绍、实验环境配置、实验过程、实验代码以及实验结果这几个部分,该实验采用了支持向量机(SVM)、随机森林算法(RFC)和反向传播算法(BP,也称为BP神经网络),通过对乘客信息的分析,了解具备哪些特征的乘客更容易存活,建立机器学习模型并预测乘客的生还情况。
一、数据集介绍
Titanic数据集包含训练数据集 train.csv 和测试数据集 test.csv ,可以点此下载。
打开 train.csv 文件后如下图所示,它包含乘客编号、存活情况、舱位等级、姓名、性别、年龄、与该乘客一起上船的兄弟姐妹或者配偶的数量、与该乘客一起上船的父母或者子女的数量、船票信息、船票价格、舱位编号以及登船港口(登船港口主要有3个,其中 C 代表 Cherbourg,Q 代表 Queenstown,S 代表 Southampton)。它的乘客编号是从1-891共891项数据。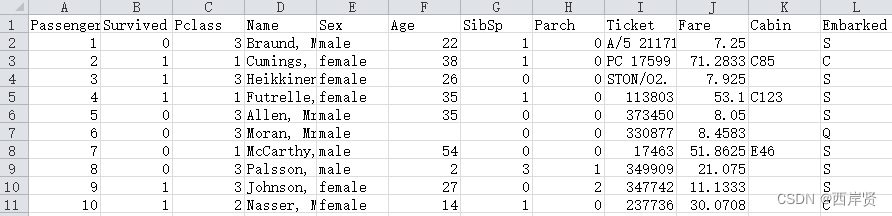
打开 test.csv 文件后如下图所示,同样包含以上几项信息,它的乘客编号是从892-1309共418项数据。
使用下面的代码就可以查看训练集和测试集上的具体数据信息及其空缺情况描述。
import pandas as pd
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
print(df_train.info())
print(df_train.describe())
print(df_test.info())
print(df_test.describe())
训练集上的数据信息汇总如下图所示。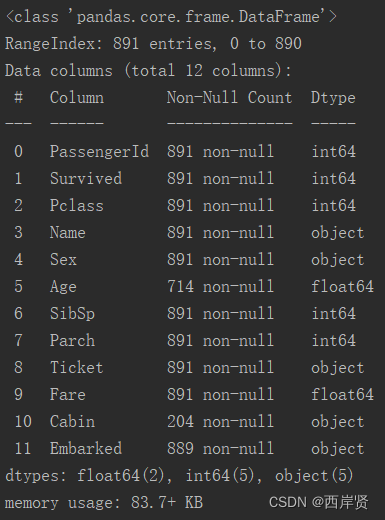
由上面的汇总信息可以看到,Age/Cabin/Embarked是有缺失的,可以依次采用平均值填充、添加新类别“Missing”来填充和出现次数最多的值填充这三项空缺。
测试集上的数据信息汇总如下图所示。
同样由上面的汇总信息可以看到,Age/Fare/Cabin是有缺失的,可以依次采用平均值填充、出现次数最多的值填充和添加新类别“Missing”来填充这三项空缺。
二、环境配置
在实验 基于 PyTorch 的 cifar-10 图像分类 环境配置的基础上再安装如下几个库。
安装 pandas 库使用下面的命令。
conda install pandas
安装 seaborn 库使用下面的命令。
conda install seaborn
安装 sklearn 库可不是直接用 conda install sklearn 命令安装的,安装该库使用的是下面的命令。
conda install -c anaconda scikit-learn
到这里,本次实验使用的库和环境就配置完成了。
三、实验过程
前面已经提到数据集中的有些内容是有缺失的,因此首先要对缺失的内容进行填补,具体的填补代码如下。
def fillna_data(df_train, df_test): # 填充缺失的数据值
df_train['Age'] = df_train['Age'].fillna(df_train['Age'].mean())
df_test['Age'] = df_test['Age'].fillna(df_test['Age'].mean()) # 对训练集和测试集中的"Age"栏数据进行平均值填充
df_train['Cabin'] = df_train['Cabin'].fillna('Missing')
df_test['Cabin'] = df_test['Cabin'].fillna('Missing') # 对训练集和测试集中的"Cabin"栏数据添加新类别"Missing"来填充
df_train['Embarked'] = df_train['Embarked'].fillna(
df_train['Embarked'].mode()[0]) # 用出现频率最多的类别填充训练集中的"Embarked"属性
df_test['Fare'] = df_test['Fare'].fillna(
df_test['Fare'].mode()[0]) # 用出现频率最多的类别填充测试集中的"Fare"属性
return df_train, df_test
df_train, df_test = fillna_data(df_train, df_test) # 得到填充后的数据集 df_train 和 df_test
填充之后先绘制存活率和舱位等级的柱状图,代码如下。
# 绘制存活率和舱位等级的柱状图
sns.barplot(x='Pclass', y='Survived', data=df_train,
palette="Set1",
errwidth=1.2,
errcolor="0.1",
capsize=0.05,
alpha=0.6)
plt.show()
存活率和舱位等级的柱状图如下图所示。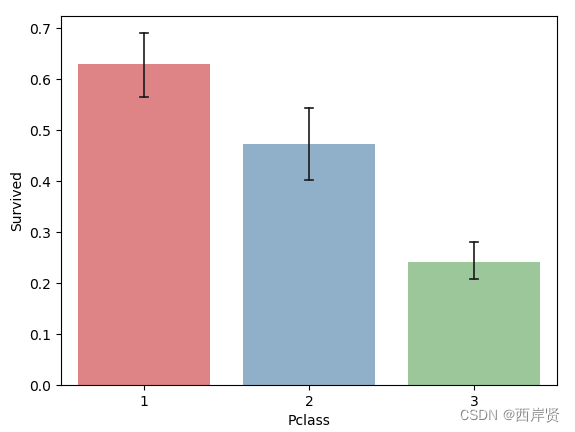
由上图可以清楚地看到,存活率和舱位等级还是有很大关系的,舱位等级越高,存活率越高,反之亦然。
接着绘制性别和存活率的柱状图,代码如下。
# 绘制存活率和性别的柱状图
sns.barplot(x='Sex', y='Survived', data=df_train,
capsize=0.05,
errwidth=1.2,
errcolor='0.1',
alpha=0.6)
plt.show()
存活率和性别的柱状图如下图所示。
由上图可以清楚地看到,存活率和性别也是有关的,女性的存活比例是远高于男性的。
绘制存活率与性别及不同年龄段的柱状图,代码如下。
# 绘制存活率与性别及不同年龄段的柱状图
women = df_train[df_train["Sex"] == "female"]
men = df_train[df_train["Sex"] == "male"]
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
ax = sns.distplot(men[men['Survived'] == 1].Age, label='Survived', ax=axes[0], kde=False)
ax.set_title('Male')
_ax = sns.distplot(women[women['Survived'] == 1].Age, label='Survived', ax=axes[1], kde=False)
_ax.set_title('Female')
plt.show()
存活率与性别及不同年龄段的柱状图如下图所示。
可以看到,不管是男性还是女性,40岁以下的存活率是要比40岁以上的人群存活率高的。
绘制存活率与乘客家属数量的折线图,代码如下。
# 绘制存活率与乘客家属数量的折线图
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4)) # 创建1行2列,大小为10*4的画布
ax = sns.lineplot(x='SibSp', y='Survived', data=df_train, ax=axes[0], label='SibSp') # 兄弟姐妹或配偶数量
ax = sns.lineplot(x='Parch', y='Survived', data=df_train, ax=axes[0], label='Parch') # 父母或者子女的数量
relatives = df_train['SibSp'] + df_train['Parch'] # 叠加两个属性
_ax = sns.lineplot(x=relatives, y=df_train['Survived'], ax=axes[1], label='Relatives')
plt.show()
存活率与乘客家属数量的折线图如下图所示。
由上图可知,当乘客在船上的兄弟姐妹或配偶数量为1时存活率最大,当乘客在船上的父母或者子女的数量为3时存活率最大,合并两个属性之后,亲属数量为3时存活率最大。
绘制存活率与登船港口的折线图,代码如下。
print(df_train['Embarked'].value_counts()) # 统计各登船港口的人数
# 绘制存活率与登船港口的折线图
sns.pointplot(x='Embarked', y='Survived', data=df_train, order=None)
plt.show()
下图是各登船港口的人数统计。
存活率与登船港口的折线图如下图所示。
登船港口与存活率有比较明显的关系,从C港登船的乘客的存活率明显高于其他两个港口登船的乘客。
四、实验代码
本实验采用了支持向量机、随机森林算法和反向传播算法,各个方法所用到的代码如下。
1.支持向量机
支持向量机(Support Vector Machine, SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器。下面是支持向量机的代码。
# 声明:本代码并非自己编写,代码来源在文末已给出博文链接
import numpy as np # 数值计算及分析
import pandas as pd # 解决数据分析任务
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 绘制图表更为集成化、绘图风格具有更高的定制性
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import cross_val_score
df_train = pd.read_csv('train.csv') # 读取训练数据
df_test = pd.read_csv('test.csv') # 读取测试数据
def fillna_data(df_train, df_test): # 填充缺失的数据值
df_train['Age'] = df_train['Age'].fillna(df_train['Age'].mean())
df_test['Age'] = df_test['Age'].fillna(df_test['Age'].mean()) # 对训练集和测试集中的"Age"栏数据进行平均值填充
df_train['Cabin'] = df_train['Cabin'].fillna('Missing')
df_test['Cabin'] = df_test['Cabin'].fillna('Missing') # 对训练集和测试集中的"Cabin"栏数据添加新类别"Missing"来填充
df_train['Embarked'] = df_train['Embarked'].fillna(
df_train['Embarked'].mode()[0]) # 用出现频率最多的类别填充训练集中的"Embarked"属性
df_test['Fare'] = df_test['Fare'].fillna(
df_test['Fare'].mode()[0]) # 用出现频率最多的类别填充测试集中的"Fare"属性
return df_train, df_test
df_train, df_test = fillna_data(df_train, df_test) # 得到填充后的数据集 df_train 和 df_test
id_test = df_test.loc[:, 'PassengerId'] # 保存乘客ID信息
# 去除无关特征
# 去掉了下面出现的特征,即对 Pclass/Sex/Age/Embarked 进行分析
df_train = df_train.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'])
df_test = df_test.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'])
# 对数据集中的字符串数据进行编码处理
def preprocess_data(train, test):
# 使用one-hot编码将登船港口"Embarked"进行转换
# 训练集
Embarked = pd.get_dummies(train['Embarked'], prefix='Embarked')
tmp_train = pd.concat([train, Embarked], axis=1)
tmp_train.drop(columns=['Embarked'], inplace=True)
# 测试集
Embarked = pd.get_dummies(test['Embarked'], prefix='Embarked')
tmp_test = pd.concat([test, Embarked], axis=1)
tmp_test.drop(columns=['Embarked'], inplace=True)
# 将年龄归一化
tmp_train['Age'] = (tmp_train['Age'] - tmp_train['Age'].min()) / (tmp_train['Age'].max() - tmp_train['Age'].min())
tmp_test['Age'] = (tmp_test['Age'] - tmp_test['Age'].min()) / (tmp_test['Age'].max() - tmp_test['Age'].min())
# 将船票价格归一化
if 'Fare' in tmp_train.columns:
tmp_train['Fare'] = (tmp_train['Fare'] - tmp_train['Fare'].min()) / (
tmp_train['Fare'].max() - tmp_train['Fare'].min())
if 'Fare' in tmp_test.columns:
tmp_test['Fare'] = (tmp_test['Fare'] - tmp_test['Fare'].min()) / (
tmp_test['Fare'].max() - tmp_test['Fare'].min())
# 将性别Sex这一特征从字符串映射至数值,0代表女性,1代表男性
gender_class = {
'female': 0, 'male': 1}
tmp_train['Sex'] = tmp_train['Sex'].map(gender_class)
tmp_test['Sex'] = tmp_test['Sex'].map(gender_class)
return tmp_train, tmp_test
data_train, data_test = preprocess_data(df_train, df_test) # 调用函数进行处理,得到data_train和data_test
label_train = data_train.loc[:, 'Survived'] # 提取训练集中Survived这列数据,因为其不能作为训练参数
data_train = data_train.drop(columns=['Survived'])
# 建立模型用的训练数据集和测试数据集
train_X, test_X, train_y, test_y = train_test_split(data_train, label_train, train_size=.8)
# 构建SVM模型并进行训练
clf_SVM = svm.SVC(C=2, gamma=0.4, kernel='rbf')
clf_SVM.fit(train_X, train_y) # 训练SVM模型
pred_SVM = clf_SVM.predict(test_X) # 模型预测
# print(confusion_matrix(test_y, pred_SVM)) # 输出混淆矩阵
print('SVM Model classification report:')
print(classification_report(test_y, pred_SVM)) # 输出分类报告
# 评估模型,输出训练集和测试集上的准确性
train_acc_SVM = cross_val_score(clf_SVM, train_X, train_y, cv=10, scoring='accuracy')
test_acc_SVM = cross_val_score(clf_SVM, test_X, test_y, cv=10, scoring='accuracy')
print('Accuracy of SVM Model:')
print('Train Accuracy: %f' % (train_acc_SVM.mean()))
print('Test Accuracy: %f' % (test_acc_SVM.mean()))
2.随机森林算法
随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。下面是随机森林算法的代码。
# 声明:本代码并非自己编写,代码来源在文末已给出博文链接
import numpy as np # 数值计算及分析
import pandas as pd # 解决数据分析任务
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 绘制图表更为集成化、绘图风格具有更高的定制性
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import cross_val_score
df_train = pd.read_csv('train.csv') # 读取训练数据
df_test = pd.read_csv('test.csv') # 读取测试数据
def fillna_data(df_train, df_test): # 填充缺失的数据值
df_train['Age'] = df_train['Age'].fillna(df_train['Age'].mean())
df_test['Age'] = df_test['Age'].fillna(df_test['Age'].mean()) # 对训练集和测试集中的"Age"栏数据进行平均值填充
df_train['Cabin'] = df_train['Cabin'].fillna('Missing')
df_test['Cabin'] = df_test['Cabin'].fillna('Missing') # 对训练集和测试集中的"Cabin"栏数据添加新类别"Missing"来填充
df_train['Embarked'] = df_train['Embarked'].fillna(
df_train['Embarked'].mode()[0]) # 用出现频率最多的类别填充训练集中的"Embarked"属性
df_test['Fare'] = df_test['Fare'].fillna(
df_test['Fare'].mode()[0]) # 用出现频率最多的类别填充测试集中的"Fare"属性
return df_train, df_test
df_train, df_test = fillna_data(df_train, df_test) # 得到填充后的数据集 df_train 和 df_test
id_test = df_test.loc[:, 'PassengerId'] # 保存乘客ID信息
# 去除无关特征
# 去掉了下面出现的特征,即对 Pclass/Sex/Age/Embarked 进行分析
df_train = df_train.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'])
df_test = df_test.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'])
# 对数据集中的字符串数据进行编码处理
def preprocess_data(train, test):
# 使用one-hot编码将登船港口"Embarked"进行转换
# 训练集
Embarked = pd.get_dummies(train['Embarked'], prefix='Embarked')
tmp_train = pd.concat([train, Embarked], axis=1)
tmp_train.drop(columns=['Embarked'], inplace=True)
# 测试集
Embarked = pd.get_dummies(test['Embarked'], prefix='Embarked')
tmp_test = pd.concat([test, Embarked], axis=1)
tmp_test.drop(columns=['Embarked'], inplace=True)
# 将年龄归一化
tmp_train['Age'] = (tmp_train['Age'] - tmp_train['Age'].min()) / (tmp_train['Age'].max() - tmp_train['Age'].min())
tmp_test['Age'] = (tmp_test['Age'] - tmp_test['Age'].min()) / (tmp_test['Age'].max() - tmp_test['Age'].min())
# 将船票价格归一化
if 'Fare' in tmp_train.columns:
tmp_train['Fare'] = (tmp_train['Fare'] - tmp_train['Fare'].min()) / (
tmp_train['Fare'].max() - tmp_train['Fare'].min())
if 'Fare' in tmp_test.columns:
tmp_test['Fare'] = (tmp_test['Fare'] - tmp_test['Fare'].min()) / (
tmp_test['Fare'].max() - tmp_test['Fare'].min())
# 将性别Sex这一特征从字符串映射至数值,0代表女性,1代表男性
gender_class = {
'female': 0, 'male': 1}
tmp_train['Sex'] = tmp_train['Sex'].map(gender_class)
tmp_test['Sex'] = tmp_test['Sex'].map(gender_class)
return tmp_train, tmp_test
data_train, data_test = preprocess_data(df_train, df_test) # 调用函数进行处理,得到data_train和data_test
label_train = data_train.loc[:, 'Survived'] # 提取训练集中Survived这列数据,因为其不能作为训练参数
data_train = data_train.drop(columns=['Survived'])
# 建立模型用的训练数据集和测试数据集
train_X, test_X, train_y, test_y = train_test_split(data_train, label_train, train_size=.8)
# 构建模型并进行训练
clf_RFC = RandomForestClassifier()
clf_RFC.fit(train_X, train_y) # 训练随机森林分类器模型
pred_RFC = clf_RFC.predict(test_X) # 模型预测
# print(confusion_matrix(test_y, pred_RFC)) # 输出混淆矩阵
print('RFC Model classification report:')
print(classification_report(test_y, pred_RFC)) # 输出分类报告
# 评估模型,输出训练集和测试集上的准确性
train_acc_RFC = cross_val_score(clf_RFC, train_X, train_y, cv=10, scoring='accuracy')
test_acc_RFC = cross_val_score(clf_RFC, test_X, test_y, cv=10, scoring='accuracy')
print('Accuracy of RFC Model:')
print('Train Accuracy: %f' % (train_acc_RFC.mean()))
print('Test Accuracy: %f' % (test_acc_RFC.mean()))
# 输出各个特征在随机森林中的重要性
keys = ['Pclass', 'Sex', 'Age', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
values = clf_RFC.feature_importances_
feature_importances_dict = dict(zip(keys, values))
print('------随机森林算法中,各个特征的重要性------')
for k, v in feature_importances_dict.items():
print(f'{
k} : {
v*100:.2f}%')
3.反向传播算法
反向传播算法,简称 BP 算法,适合于多层神经元网络的一种学习算法,它建立在梯度下降法的基础上,BP 网络的输入输出关系实质上是一种映射关系,即一个 n 输入 m 输出的 BP 神经网络所完成的功能是从 n 维欧氏空间向 m 维欧氏空间中一有限域的连续映射,这一映射具有高度非线性。它的信息处理能力来源于简单非线性函数的多次复合,因此具有很强的函数复现能力。下面是反向传播算法的代码。
# 声明:本代码并非自己编写,代码来源在文末已给出博文链接
import numpy as np # 数值计算及分析
import pandas as pd # 解决数据分析任务
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 绘制图表更为集成化、绘图风格具有更高的定制性
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import cross_val_score
df_train = pd.read_csv('train.csv') # 读取训练数据
df_test = pd.read_csv('test.csv') # 读取测试数据
def fillna_data(df_train, df_test): # 填充缺失的数据值
df_train['Age'] = df_train['Age'].fillna(df_train['Age'].mean())
df_test['Age'] = df_test['Age'].fillna(df_test['Age'].mean()) # 对训练集和测试集中的"Age"栏数据进行平均值填充
df_train['Cabin'] = df_train['Cabin'].fillna('Missing')
df_test['Cabin'] = df_test['Cabin'].fillna('Missing') # 对训练集和测试集中的"Cabin"栏数据添加新类别"Missing"来填充
df_train['Embarked'] = df_train['Embarked'].fillna(
df_train['Embarked'].mode()[0]) # 用出现频率最多的类别填充训练集中的"Embarked"属性
df_test['Fare'] = df_test['Fare'].fillna(
df_test['Fare'].mode()[0]) # 用出现频率最多的类别填充测试集中的"Fare"属性
return df_train, df_test
df_train, df_test = fillna_data(df_train, df_test) # 得到填充后的数据集 df_train 和 df_test
id_test = df_test.loc[:, 'PassengerId'] # 保存乘客ID信息
# 去除无关特征
# 去掉了下面出现的特征,即对 Pclass/Sex/Age/Embarked 进行分析
df_train = df_train.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'])
df_test = df_test.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'])
# 对数据集中的字符串数据进行编码处理
def preprocess_data(train, test):
# 使用one-hot编码将登船港口"Embarked"进行转换
# 训练集
Embarked = pd.get_dummies(train['Embarked'], prefix='Embarked')
tmp_train = pd.concat([train, Embarked], axis=1)
tmp_train.drop(columns=['Embarked'], inplace=True)
# 测试集
Embarked = pd.get_dummies(test['Embarked'], prefix='Embarked')
tmp_test = pd.concat([test, Embarked], axis=1)
tmp_test.drop(columns=['Embarked'], inplace=True)
# 将年龄归一化
tmp_train['Age'] = (tmp_train['Age'] - tmp_train['Age'].min()) / (tmp_train['Age'].max() - tmp_train['Age'].min())
tmp_test['Age'] = (tmp_test['Age'] - tmp_test['Age'].min()) / (tmp_test['Age'].max() - tmp_test['Age'].min())
# 将船票价格归一化
if 'Fare' in tmp_train.columns:
tmp_train['Fare'] = (tmp_train['Fare'] - tmp_train['Fare'].min()) / (
tmp_train['Fare'].max() - tmp_train['Fare'].min())
if 'Fare' in tmp_test.columns:
tmp_test['Fare'] = (tmp_test['Fare'] - tmp_test['Fare'].min()) / (
tmp_test['Fare'].max() - tmp_test['Fare'].min())
# 将性别Sex这一特征从字符串映射至数值,0代表女性,1代表男性
gender_class = {
'female': 0, 'male': 1}
tmp_train['Sex'] = tmp_train['Sex'].map(gender_class)
tmp_test['Sex'] = tmp_test['Sex'].map(gender_class)
return tmp_train, tmp_test
data_train, data_test = preprocess_data(df_train, df_test) # 调用函数进行处理,得到data_train和data_test
label_train = data_train.loc[:, 'Survived'] # 提取训练集中Survived这列数据,因为其不能作为训练参数
data_train = data_train.drop(columns=['Survived'])
# 建立模型用的训练数据集和测试数据集
train_X, test_X, train_y, test_y = train_test_split(data_train, label_train, train_size=.8)
# 构建模型并进行训练
mlp = MLPClassifier(hidden_layer_sizes=(64, 32), activation='relu', solver='adam', max_iter=800)
# 两个隐藏层,第一层为64个神经元,第二层为32个神经元
mlp.fit(train_X, train_y) # 训练神经网络
pred_BP = mlp.predict(test_X) # 模型预测
# print(confusion_matrix(test_y, pred_BP)) # 输出混淆矩阵
print('BP Model classification report:')
print(classification_report(test_y, pred_BP)) # 输出分类报告
# 评估模型,输出训练集和测试集上的准确性
train_acc_BP = mlp.score(train_X, train_y)
test_acc_BP = mlp.score(test_X, test_y)
print('Accuracy of BP Model:')
print('Train Accuracy: %f' % (train_acc_BP))
print('Test Accuracy: %f' % (test_acc_BP))
五、实验结果
分别运行上面的代码,控制台就会输出对应方法的分类报告及其训练集和测试集上的准确率。
支持向量机方法的分类报告和准确率如下图所示。
随机森林算法的分类报告如下图所示。
随机森林算法训练集和测试集上的准确率如下图所示。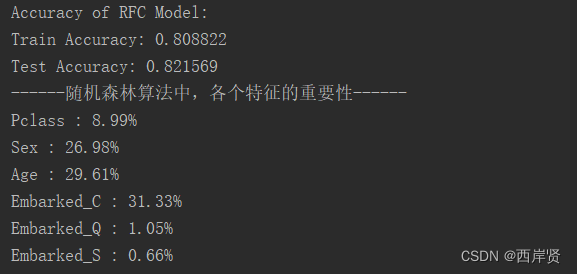
反向传播算法的分类报告和准确率如下图所示。
上面各图中评估指标的解释如下:
precision,精确率(也称差准率),即所有被预测为正的样本中实际为正的样本的概率,其公式如下。
recall,召回率(也称查全率),即实际为正的样本中被预测为正样本的概率,其公式如下。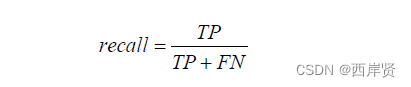
f1-score,即f1分数,也就是精确率和召回率的调和平均数,它是为了综合两者的表现,在两者之间找一个平衡点,其公式如下。
accuracy,准确率,即预测正确的结果占总样本的百分比,其公式如下。
上面公式中 TP(True Positive)代表实际为正例且判断为正例;TN(True Negative) 代表实际为负例且判断为负例;FP(False Positive) 代表实际为负例且判断为正例; FN(False Negative) 代表实际为正例且判断为负例。
此外,support 是各分类样本的数量或测试集样本的总数量;macro avg,即宏平均值,也就是所有标签结果的平均值;weighted avg,即加权平均值,也就是所有标签结果的加权平均值。由以上图中的参数对比可知,这三种方法得到的结果是相差不大的。
总结
以上就是 Titanic 预测问题的所有内容了,在做该实验之前,应当首先了解一下故事的背景以及数据集中每一列所代表的含义,这对于做好该实验比较重要,同时,通过运行代码绘制一些柱状图或是折线图来更加直观的判断该因素是否和存活率有关也是比较重要的方法。
参考博文:
逻辑回归应用之Kaggle泰坦尼克之灾
机器学习-分析Titanic数据集(本实验代码来源)
边栏推荐
猜你喜欢
Postgresql source code learning (34) - transaction log ⑩ - full page write mechanism

浅析瀑布流布局原理及实现方式

剑指offer(一)

Core Tower Electronics won the championship in the Wuhu Division of the 11th China Innovation and Entrepreneurship Competition
Redux state management

【云原生】3.3 Kubernetes 中间件部署实战

那些破釜沉舟入局Web3.0的互联网精英都怎么样了?
芯塔电子斩获第十一届中国双创大赛芜湖赛区桂冠
搭建zabbix监控及邮件报警(超详细教学)

【C语言项目合集】这十个入门必备练手项目,让C语言对你来说不再难学!
随机推荐
Chapter 17: go back to find the entrance to the specified traverse, "ma bu" or horse stance just look greedy, no back to search traversal, "ma bu" or horse stance just look recursive search NXM board
电压源的电路分析知识分享
postgresql源码学习(34)—— 事务日志⑩ - 全页写机制
In-depth analysis of z-index
4-1-7 二叉树及其遍历 家谱处理 (30 分)
浅析v-model语法糖的实现原理与细节知识及如何让你开发的组件支持v-model
Explain the example + detail the difference between @Resource and @Autowired annotations (the most complete in the entire network)
运行 npm 会弹出询问 “你要如何打开这个文件?“
tidyverse笔记——dplyr包
js原型详解
从 Google 离职,前Go 语言负责人跳槽小公司
文件 - 02 上传文件:上传临时文件到服务器
Conditional statements of shell (test, if, case)
使用powerDesigner反向工程生成Entity
【编程题】【Scratch三级】2022.03 冬天下雪了
2. (1) Chained storage of stack, operation of chain stack (illustration, comment, code)
TypeScript编译(tsconfig.json)
【科普向】5G核心网架构和关键技术
Detailed explanation of js prototype
【并发编程】ReentrantLock的lock()方法源码分析