当前位置:网站首页>文献阅读十——Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learn
文献阅读十——Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learn
2022-08-04 22:47:00 【江_小_白】
系列文章目录
- 谣言检测文献阅读一—A Review on Rumour Prediction and Veracity Assessment in Online Social Network
- 谣言检测文献阅读二—Earlier detection of rumors in online social networks using certainty‑factor‑based convolutional neural networks
- 谣言检测文献阅读三—The Future of False Information Detection on Social Media:New Perspectives and Trends
- 谣言检测文献阅读四—Reply-Aided Detection of Misinformation via Bayesian Deep Learning
- 谣言检测文献阅读五—Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection
- 谣言检测文献阅读六—Tracing Fake-News Footprints: Characterizing Social Media Messages by How They Propagate
- 谣言检测文献阅读七—EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
- 谣言检测文献阅读八—Detecting breaking news rumors of emerging topics in social media
- 谣言检测文献阅读九—人工智能视角下的在线社交网络虚假信息 检测、传播与控制研究综述
- 文献阅读十——Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learn
前言
文章:Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learning
发表会议:The Web Conference 2019 - Proceedings of the World Wide Web Conference, WWW 2019 (A 类会议论文)
时间:2019年
摘要
分析表明,谣言的泛滥通常是由故意推动的信息宣传活动成的,其目的是塑造对相关新闻事件的集体意见。在本文中,我们试图用自身来对抗这种混乱,使自动谣言检测更加稳健和有效。我们的想法是受到源自生成对抗网络(GAN)的对抗性学习方法的启发。我们提出了一种GAN式的方法,即设计一个生成器来产生不确定或冲突的声音,使原来的对话线程复杂化,以便给鉴别器施加压力,使其从增强的、更具挑战性的例子中学习更强的谣言指示性表示。与传统的数据驱动的谣言检测方法(深度学习方法)不同,我们的方法可以通过这种对抗性训练捕捉到低频但更强的非凡的模式(non-trivial)。在两个Twitter基准数据集上进行的广泛实验表明,我们的谣言检测方法比最先进的方法取得了更好的结果。
1 介绍
造谣者经常通过社交网络开展信息宣传活动,宣传有争议的模因(meme)、虚假新闻等
注:meme 模因:一种文化或行为系统的要素,可以通过非遗传手段(尤其是模仿行为)在人群之间传播
然而,现有的数据驱动的方法通常依赖于寻找指示性的反应,如怀疑和不同意的意见来检测。谣言制造者可以利用宣传活动来左右公众意见( entangle public opinions)或影响集体立场,使其得到广泛传播和扩大。这对数据驱动方法提出了重大的技术挑战,因为文本模式和其他显式特征变得难以区分。各种相互冲突和不确定的声音共存会严重干扰有用特征的学习(或提取)。图1展示了一个关于“沙特阿拉伯斩首第一位女性机器人公民”的谣言宣传活动的案例,展示了流行的表示怀疑和不同意的指示模式,如“假新闻”、“不确定”、“没有真相”是如何被宣传的帖子淹没的。因此,迫切需要开发一个更强大的谣言检测特征学习器。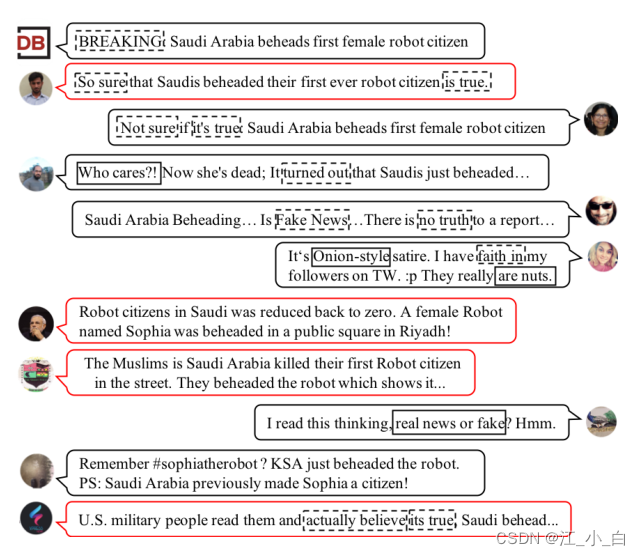 图1:在一次宣传活动中,对关于“沙特阿拉伯斩首其第一位女性机器人公民”的谣言的回应样本。社交机器人的活动被标记为红色框。左侧列出了支持性反应,右侧列出了否认(或不确定)反应。现有方法捕获的模式用虚线矩形标记,可能缺失的模式用实心矩形标记。
图1:在一次宣传活动中,对关于“沙特阿拉伯斩首其第一位女性机器人公民”的谣言的回应样本。社交机器人的活动被标记为红色框。左侧列出了支持性反应,右侧列出了否认(或不确定)反应。现有方法捕获的模式用虚线矩形标记,可能缺失的模式用实心矩形标记。
在本文中,我们利用信息运动机制提出了一种全新的谣言检测方法并以可控的方式进行推广,以实现更稳健、更有效的检测。我们看似违反直觉的想法受到生成对抗网络的启发或被称为 GAN,其中判别分类器学习区分实例是否来自真实世界,并训练生成模型,通过生成近似真实的示例来混淆判别器。
我们通过模仿竞选宣传,包括带有不确定和冲突声音的误导基层对话(grassroots conversations),训练生成器输出具有挑战性的示例,从而推动我们的鉴别器从此类困难示例中加强特征学习,以捕捉更多的判别模式。
直观地说,为什么这样一种GAN风格的方法在特征学习方面做得更好?如图1所示,各种用户参与可以轻松打破过去的数据驱动方法,这些方法通常在响应帖子时采用重复模式。由于活动的影响,在对谣言的回应中经常出现的“假新闻”或“不真实”等高频模式以及在非谣言的回应中出现的“真实/确定”等高频模式变得不那么具有判别性。因此,判别器自适应地调整为专注于捕捉相对低频的模式,如 "洋葱式 “(onion-style)和 “坚果式(be nuts 傻里傻气)”,这些模式与高频模式一样重要,而在现有的特征学习方法中却被忽略。(As a result, the discriminator is adjusted adaptively to focus on capturing the relatively low-frequency patterns, such as “onion-style” and “be nuts”, which are expected non-trivial as high-frequency ones while used to be ignored in existing feature learning methods)为了保留原始高频模式的判别能力,我们用生成的类似运动的例子和原始例子在增强的训练数据上训练判别器。
创新点:
- 据我们所知,这是第一种使用基于文本的GAN风格框架进行谣言检测的生成方法,在这种框架中,我们使文本生成器和鉴别器相互增强,以增强谣言指示模式的表示学习。
- 我们将谣言传播建模为生成信息活动,用于生成令人困惑的训练示例,以鉴别器挑战的检测能力的。
- 在 GAN 风格的框架下,我们加强了我们的鉴别器,它在一组由生成器补充的更具挑战性的例子上进行训练,专注于学习低频但有鉴别力的模式。
- 我们通过实验证明,我们的模型比基于两个公共基准数据集的最先进的基线更强大和有效,用于 Twitter 上的谣言检测任务。
2 问题陈述
对于可靠的特征提取,在 Twitter 谣言检测任务中,声明通常由一组与声明相关的帖子(即推文)表示,这些帖子可以通过 Twitter 的搜索功能收集。我们将谣言数据集表示为 X {X} X,其中每个 X = ( y , x 1 x 2 . . . x T ) X = (y, x_1x_2 ... x_T ) X=(y,x1x2...xT) 是表示给定声明的元组:X 由真实标签 y ∈ {N , R} 组成声明(即非谣言或谣言)和一系列相关帖子 x 1 , x 2 . . . x T x_1,x_2 . .. x_T x1,x2...xT ,其中每个 x t x_t xt 可以表示一个帖子或更一般地表示时间间隔内的一批帖子,并以时间步长 t 进行索引。因此,可以将声明视为相关帖子的时间序列。为清楚起见,我们将实例(声明)X 写为 X y X_y Xy,即 X R X_R XR 表示谣言, X N X_N XN 表示非谣言。
emsp;信息活动对现有的谣言检测模型提出了挑战,因为表明真实性的频繁模式变得扭曲和误导。我们的基本思想是在生成对抗学习机制的启发下加强谣言指示特征的表示学习。我们提出了一个 GAN 风格的模型,其中生成器尝试通过生成硬示例来促进活动,而鉴别器旨在识别稳健的特征以克服生成器带来的困难。与最近用于多模态假新闻检测的事件对抗模型 [18] 和用于早期检测的神经用户响应生成器 [16] 不同,我们的想法和采用的机制有很大不同。
3 谣言检测的生成对抗学习
3.1 有争议的示例生成
我们的生成模型旨在针对给定的声明产生不确定或相互冲突的声音,从而使过去依赖于重复模式的谣言和非谣言的区分变得更加困难。
一种直接的方法是通过一些规则模板扭曲或复杂化原始数据示例中表达的观点。例如,我们可以
- 将“真的吗?”、“是真的吗?”、“不确定”等询问表达加入到回复帖子中;
- 通过在“be”动词后添加“not”来否定其帖子的立场;
- 在关键字的某些部分应用反义词替换,例如,用“真”代替“假”,用“错”代替“对”等。但是,很难将这些规则概括为正式产生任何有争议的声音。一种通用的方法是将我们的生成器转换为可训练的模型,该模型可以涵盖各种表达变化。
注:这些方法都是改变原本的意思,我们可以研究不改变原意的方法进行攻击(没找到怎么说好)或者减少“噪声”
为此,我们设计了两个生成器,一个用于扭曲非谣言使其看起来像一个谣言,另一个用于“粉饰”谣言使其看起来像一个非谣言: 1) G N → R G_N→R GN→R 对非谣言声明产生怀疑或反对的声音; 2) G R → N G_R→N GR→N 产生支持谣言的声音。我们定义了一个函数 f g f_g fg 来制定我们的生成模型: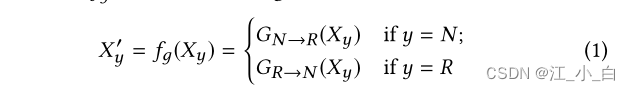 其中 X y X_y Xy 是来自训练集的原始实例,可以是谣言或非谣言, X y ′ X'_y Xy′是带有生成器的变换实例,而标签保持不变。
其中 X y X_y Xy 是来自训练集的原始实例,可以是谣言或非谣言, X y ′ X'_y Xy′是带有生成器的变换实例,而标签保持不变。
考虑到每个实例中帖子的时间序列结构,我们使用序列到序列模型 [11, 17] 进行生成转换,如图 2 所示。我们通过 RNN 将输入序列 X y X_y Xy 编码为隐藏向量编码器,然后通过 RNN 解码器从中生成转换后的序列 X y ′ X'_y Xy′。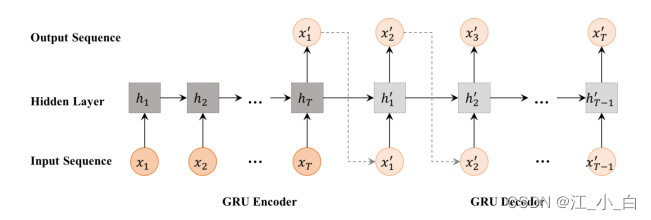 GRU-RNN 编码器: 我们按照 [12] 中描述的类似时间分割将相关帖子分批成时间间隔,并将每个批次视为时间序列中的一个单元。使用 RNN,我们将每个输入单元 x t ∈ X y x_t ∈ X_y xt∈Xy 映射到一个隐藏向量 h t h_t ht中,我们使用 GRU [4] 来存储隐藏表示:
GRU-RNN 编码器: 我们按照 [12] 中描述的类似时间分割将相关帖子分批成时间间隔,并将每个批次视为时间序列中的一个单元。使用 RNN,我们将每个输入单元 x t ∈ X y x_t ∈ X_y xt∈Xy 映射到一个隐藏向量 h t h_t ht中,我们使用 GRU [4] 来存储隐藏表示: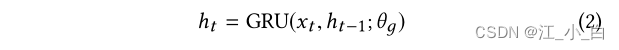 x t x_t xt 是表示为从落入第 t 个时间步的帖子计算的词汇单词的 tf*idf 值的向量的输入单元, h t − 1 h_{t-1} ht−1 指的是先前的隐藏状态, 和 θ g θ_g θg 表示 GRU 的所有参数。GRU-RNN 编码器的最后一个时间步 h T h_T hT 的输出是 X y X_y Xy 的隐藏表示
x t x_t xt 是表示为从落入第 t 个时间步的帖子计算的词汇单词的 tf*idf 值的向量的输入单元, h t − 1 h_{t-1} ht−1 指的是先前的隐藏状态, 和 θ g θ_g θg 表示 GRU 的所有参数。GRU-RNN 编码器的最后一个时间步 h T h_T hT 的输出是 X y X_y Xy 的隐藏表示
GRU-RNN解码器: 每个单元都是使用GRU和softmax输出函数顺序生成的(each unit is sequentially generated using GRU followed by a softmax output function)。在每个步骤t中,softmax输出层通过计算词汇单词的分布,将通过GRU获得的隐藏状态 h ′ t h′_t h′t映射到一批POST的目标表示 x ′ t + 1 x′_{t+1} x′t+1
构建one-hot词汇表(5000),然后根据softmax计算最大概率,寻找转换后的单词
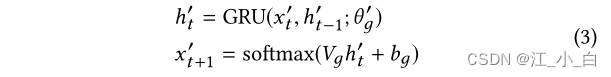 其中 h ′ t − 1 h′_{t−1} h′t−1是GRU译码器的先前隐藏状态, θ ′ g θ′_g θ′g表示GRU2内的所有参数, V g V_g Vg和 b g b_g bg是输出层的可训练参数。
其中 h ′ t − 1 h′_{t−1} h′t−1是GRU译码器的先前隐藏状态, θ ′ g θ′_g θ′g表示GRU2内的所有参数, V g V_g Vg和 b g b_g bg是输出层的可训练参数。
3.2 GAN式对抗性学习模型
在这个编码器-解码器框架中, f g ( X y ) f_g(X_y) fg(Xy)定义了生成有争议的帖子的代表策略,这些帖子是用来混淆基于输入 X y X_y Xy的判别器的。一个关键的问题是如何控制生成器来生成所需的。为此,我们用鉴别器的性能作为奖励来指导生成器。在介绍鉴别器之前,让我们介绍一下我们的GAN式模型的结构和控制机制,如图3所示,它由一个对抗性学习模块和两个重建模块(一个用于谣言,另一个用于非谣言)组成。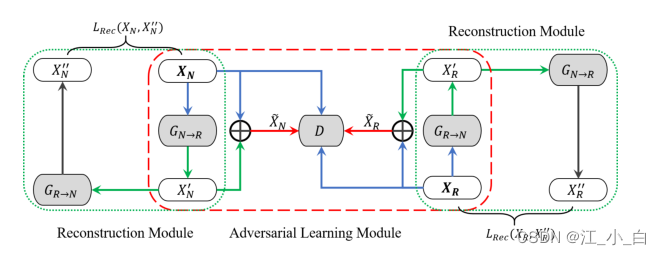 图3:我们的GAN式谣言检测模型的概述。 G N → R G_N→R GN→R(或 G R → N G_R→N GR→N)是一个生成器。D表示判别器
图3:我们的GAN式谣言检测模型的概述。 G N → R G_N→R GN→R(或 G R → N G_R→N GR→N)是一个生成器。D表示判别器
对抗性学习模块: 在我们的模型中,鼓励生成器产生类似运动的实例来欺骗鉴别器,这样鉴别器就可以专注于学习更多的判别性特征。这样的目标表明训练目标类似于对抗性学习。我们将对抗性损失表述为基于生成器增加的训练数据的判别器损失的负值。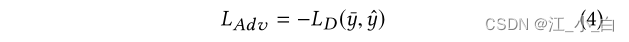 其中, L D ( − ) L_D(-) LD(−)是真实类概率分布 y ˉ \bar{y} yˉ与判别器预测的类分布 y ^ \hat{y} y^之间的损失( L D ( − ) L_D(-) LD(−)的具体形式见公式11)。
其中, L D ( − ) L_D(-) LD(−)是真实类概率分布 y ˉ \bar{y} yˉ与判别器预测的类分布 y ^ \hat{y} y^之间的损失( L D ( − ) L_D(-) LD(−)的具体形式见公式11)。
我们将生成的示例和原始示例结合起来,通过取它们的并集( X ~ y ⋃ X y \tilde{X}_y\bigcup X_y X~y⋃Xy)来扩充训练集,其中 X ~ y = X y ⊕ X y ′ \tilde{X}_y=X_y⊕ X'_y X~y=Xy⊕Xy′是原始示例和生成示例的元素相加。注意,元素相加具有抵消有影响的高频模式的效果,并提高重要的低频模式被选择的机会。同时,我们不想在原始示例中严重削弱这些有用的功能。因此,如图3所示,原始示例 X y X_y Xy与 X ~ y \tilde{X}_y X~y组合用于训练。
重建模块: 生成器可能会通过更改故事的某些基本方面,将原始示例扭曲到意外的方向。例如,“沙特斩首机器人公民”的主题可能会被扭曲为“沙特为卡塔尔挖掘运河”,这是不相干的,也是没有帮助的。为了避免这种情况,我们引入了一种重构机制,使生成过程可逆。其思想是,通过两个方向相反的生成器,有意见的声音(opinionated voices)将是可逆的,以最大限度地减少信息保真度的损失。我们将重建函数定义如下: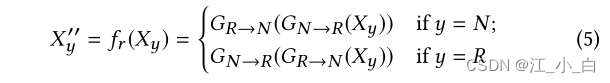 其中 X y ′ ′ X''_y Xy′′是通过两个相反的生成器从原始实例 X y X_y Xy 重建的实例。我们将 X y ′ ′ X''_y Xy′′和 X y X_y Xy之间的差异表示为重建损失:
其中 X y ′ ′ X''_y Xy′′是通过两个相反的生成器从原始实例 X y X_y Xy 重建的实例。我们将 X y ′ ′ X''_y Xy′′和 X y X_y Xy之间的差异表示为重建损失: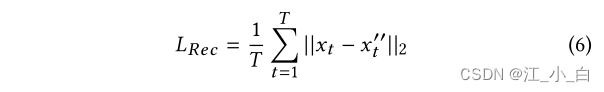 ∣ ∣ ⋅ ∣ ∣ 2 || · ||_2 ∣∣⋅∣∣2 是向量的 L2 范数。
∣ ∣ ⋅ ∣ ∣ 2 || · ||_2 ∣∣⋅∣∣2 是向量的 L2 范数。
优化目标: 我们的GAN式对抗学习的总体损失函数定义为 L A d v L_{Adv} LAdv和 L R e c L_{Rec} LRec的线性插值: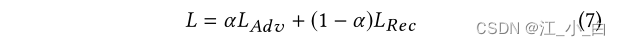 其中α是对抗损失和重建损失之间的权衡系数。对抗性学习的目标采用最小-最大形式:
其中α是对抗损失和重建损失之间的权衡系数。对抗性学习的目标采用最小-最大形式: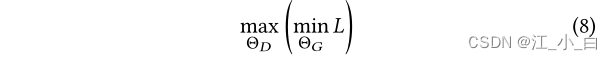 其中, Θ G = { θ k , θ ′ k , V k , b k } Θ_G=\{θ_k,θ′_k,V_k,b_k\} ΘG={ θk,θ′k,Vk,bk}是生成器的参数, Θ D Θ_D ΘD是鉴别器的参数,将在下一节中详细介绍。在最小-最大过程中,我们首先通过最小化对抗损失 L A d v L_{Adv} LAdv(即最大鉴别器损失 L D L_D LD)和重建损失 L R e c L_{Rec} LRec来优化 Θ G Θ_G ΘG,以生成混乱但可逆的示例;然后,我们通过最大化对抗损失 L A d v L_{Adv} LAdv(即最小化鉴别器损失 L D L_D LD)优化用于分类的鉴别器参数 Θ D Θ_D ΘD,并注意到 L R e c L_{Rec} LRec独立于 Θ D Θ_D ΘD。
其中, Θ G = { θ k , θ ′ k , V k , b k } Θ_G=\{θ_k,θ′_k,V_k,b_k\} ΘG={ θk,θ′k,Vk,bk}是生成器的参数, Θ D Θ_D ΘD是鉴别器的参数,将在下一节中详细介绍。在最小-最大过程中,我们首先通过最小化对抗损失 L A d v L_{Adv} LAdv(即最大鉴别器损失 L D L_D LD)和重建损失 L R e c L_{Rec} LRec来优化 Θ G Θ_G ΘG,以生成混乱但可逆的示例;然后,我们通过最大化对抗损失 L A d v L_{Adv} LAdv(即最小化鉴别器损失 L D L_D LD)优化用于分类的鉴别器参数 Θ D Θ_D ΘD,并注意到 L R e c L_{Rec} LRec独立于 Θ D Θ_D ΘD。
3.3 谣言鉴别器
我们基于RNN谣言检测模型(马静 2016)构建了鉴别器。给定一个实例(原始或生成),RNN模型首先使用GRU将第t步的相关帖子 x t x_t xt映射到隐藏向量 s t s_t st: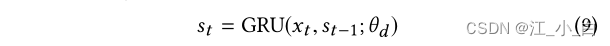 然后输入到softmax层中对实例进行分类:
然后输入到softmax层中对实例进行分类: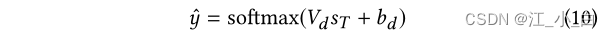 其中 y ^ \hat{y} y^是两类上预测概率的向量, V d V_d Vd是输出层的权重矩阵, b d b_d bd是可训练偏差。
其中 y ^ \hat{y} y^是两类上预测概率的向量, V d V_d Vd是输出层的权重矩阵, b d b_d bd是可训练偏差。
判别器的损失定义为预测类和真实类分布之间的平方误差: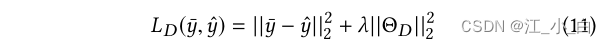 其中 y ˉ \bar{y} yˉ 和 y ^ \hat{y} y^分别是真值和预测类别概率分布, Θ D = { θ d , V d , b d } Θ_D =\{θ_d ,V_d ,b_d\} ΘD={ θd,Vd,bd} 是判别器参数,λ 是权衡系数。
其中 y ˉ \bar{y} yˉ 和 y ^ \hat{y} y^分别是真值和预测类别概率分布, Θ D = { θ d , V d , b d } Θ_D =\{θ_d ,V_d ,b_d\} ΘD={ θd,Vd,bd} 是判别器参数,λ 是权衡系数。
3.4 生成对抗训练算法
算法 1 展示了我们的 GAN 风格框架中生成器和判别器的迭代训练过程。与用于获得更好生成器的原始 GAN不同,我们的目标是增强鉴别器以使其更具辨别力和泛化性。 生成器和判别器使用小批量的随机梯度体面交替训练。在每个 epoch 中,都会生成有争议的示例并将其扩充到原始训练数据中。我们用公式8对生成器和判别器进行优化,该公式通过算法1中的步骤8-11执行最小-最大博弈。
生成器和判别器使用小批量的随机梯度体面交替训练。在每个 epoch 中,都会生成有争议的示例并将其扩充到原始训练数据中。我们用公式8对生成器和判别器进行优化,该公式通过算法1中的步骤8-11执行最小-最大博弈。
在训练中,我们用均匀分布初始化模型参数;我们迭代训练,直到达到最大 epoch 数,设置为 200;我们将词汇量固定为 5,000,隐藏向量的大小为 100,并使用保留数据集调整超参数 α、λ 和 ε。
边栏推荐
猜你喜欢








随机推荐
SQL Server 调用 WebService
puzzle(022.1)黑白迭代
祝福一路顺风
【3D建模制作技巧分享】ZBrush模型制作流程:地精
Leaflets of three bouquet of roses
Pytest学习-Fixture
养殖虚拟仿真软件提供高沉浸式的虚拟场景互动操作体验学习
单片机原理[一] 学好单片机必会的五张图
三个多月、40余场面试浓缩为6000字
各行各业都受到重创,游戏行业却如火如荼,如何加入游戏模型师职业
Operations on std::vector
深度学习 RNN架构解析
力扣19-删除链表的倒数第 N 个结点——链表
[Mock Interview - 10 Years of Work] Are more projects an advantage?
【3D建模制作技巧分享】ZBrush如何使用Z球
智慧养老整体解决方案
xss总结
【游戏建模模型制作全流程】在ZBrush中雕刻恶魔城男性角色模型
Use ngrok to optimize web pages on raspberry pi (1)
备战9月,美团50道软件测试经典面试题及答案汇总