当前位置:网站首页>【GCN-RS】UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation (CIKM‘21)
【GCN-RS】UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation (CIKM‘21)
2022-06-22 06:54:00 【chad_ lee】
UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation (CIKM’21 Huawei Noah Ark )
( I forgot to send the article in the draft box , For more than two months )
The article analyzes LightGCN Three shortcomings of , And a kind of Extremely simplified GCN Recommended model , Almost degree weighted MF, No, message passing、aggregation, With two auxiliary loss Introduce graph structure information into MF, To put Amazon-Book The data set exploded , The velocity is LightGCN Of 15 times , The effect is improved 60%, It can be said that the road is simple , Recover one's original simplicity , The feeling is MF+ItemCF Model fusion . At the same time, there is also the idea of false labels in it .
LightGCN Three major shortcomings
One disadvantage : The edge weight of message aggregation is counterintuitive
LightGCN Message aggregation for :
e u ( l + 1 ) = 1 d u + 1 e u ( l ) + ∑ k ∈ N ( u ) 1 d u + 1 d k + 1 e k ( l ) e i ( l + 1 ) = 1 d i + 1 e i ( l ) + ∑ v ∈ N ( i ) 1 d v + 1 d i + 1 e v ( l ) \begin{aligned} &e_{u}^{(l+1)}=\frac{1}{d_{u}+1} e_{u}^{(l)}+\sum_{k \in \mathcal{N}(u)} \frac{1}{\sqrt{d_{u}+1} \sqrt{d_{k}+1}} e_{k}^{(l)} \\ &e_{i}^{(l+1)}=\frac{1}{d_{i}+1} e_{i}^{(l)}+\sum_{v \in \mathcal{N}(i)} \frac{1}{\sqrt{d_{v}+1} \sqrt{d_{i}+1}} e_{v}^{(l)} \end{aligned} eu(l+1)=du+11eu(l)+k∈N(u)∑du+1dk+11ek(l)ei(l+1)=di+11ei(l)+v∈N(i)∑dv+1di+11ev(l)
Dot product :
e u ( l + 1 ) ⋅ e i ( l + 1 ) = α u i ( e u ( l ) ⋅ e i ( l ) ) + ∑ k ∈ N ( u ) α i k ( e i ( l ) ⋅ e k ( l ) ) + ∑ v ∈ N ( i ) α u v ( e u ( l ) ⋅ e v ( l ) ) + ∑ k ∈ N ( u ) ∑ v ∈ N ( i ) α k v ( e k ( l ) ⋅ e v ( l ) ) \begin{gathered} e_{u}^{(l+1)} \cdot e_{i}^{(l+1)}=\alpha_{u i}\left(e_{u}^{(l)} \cdot e_{i}^{(l)}\right)+\sum_{k \in \mathcal{N}(u)} \alpha_{i k}\left(e_{i}^{(l)} \cdot e_{k}^{(l)}\right)+ \\ \sum_{v \in \mathcal{N}(i)} \alpha_{u v}\left(e_{u}^{(l)} \cdot e_{v}^{(l)}\right)+\sum_{k \in \mathcal{N}(u)} \sum_{v \in \mathcal{N}(i)} \alpha_{k v}\left(e_{k}^{(l)} \cdot e_{v}^{(l)}\right) \end{gathered} eu(l+1)⋅ei(l+1)=αui(eu(l)⋅ei(l))+k∈N(u)∑αik(ei(l)⋅ek(l))+v∈N(i)∑αuv(eu(l)⋅ev(l))+k∈N(u)∑v∈N(i)∑αkv(ek(l)⋅ev(l))
And the weight α \alpha α:
α u i = 1 ( d u + 1 ) ( d i + 1 ) α i k = 1 d u + 1 d k + 1 ( d i + 1 ) α u v = 1 d v + 1 d i + 1 ( d u + 1 ) α k v = 1 d u + 1 d k + 1 d v + 1 d i + 1 \begin{aligned} \alpha_{u i} &=\frac{1}{\left(d_{u}+1\right)\left(d_{i}+1\right)} \\ \alpha_{i k} &=\frac{1}{\sqrt{d_{u}+1} \sqrt{d_{k}+1}\left(d_{i}+1\right)} \\ \alpha_{u v} &=\frac{1}{\sqrt{d_{v}+1} \sqrt{d_{i}+1}\left(d_{u}+1\right)} \\ \alpha_{k v} &=\frac{1}{\sqrt{d_{u}+1} \sqrt{d_{k}+1} \sqrt{d_{v}+1} \sqrt{d_{i}+1}} \end{aligned} αuiαikαuvαkv=(du+1)(di+1)1=du+1dk+1(di+1)1=dv+1di+1(du+1)1=du+1dk+1dv+1di+11
therefore α i k \alpha_{ik} αik Is used to model item-item Of the relationship , But for a user, goods i i i And objects k k k The weight of is asymmetric ( 1 d k + 1 \frac{1}{\sqrt{d_{k}+1}} dk+11 for k k k, 1 d i + 1 \frac{1}{d_{i}+1} di+11 for i i i). Accordingly, for modeling user-user Relationship , There are also unequal weights .
Such unreasonable weight assignments may mislead the model training and finally result in sub-optimal performance.
But I don't think this is the key issue , For data e u ∗ e i e_u*e_i eu∗ei unequal , For data e u ∗ e k e_u*e_k eu∗ek And inequality , But the two train together , Isn't it equal ?
Disadvantages two : Message aggregation has a small amount of information
All types of messages are aggregated , It does not distinguish between message types , No distinction is made between importance , There may also be noise , It should be different relationships Give different importance .
But I don't think this is the key issue , There are not already in the message transmission 1 d u + 1 d k + 1 \frac{1}{\sqrt{d_{u}+1} \sqrt{d_{k}+1}} du+1dk+11 As a weight of importance ? The author's later weight of importance is essentially the same as this . The corresponding solution to this problem should be attentive The aggregation of .
Disadvantages three :Over-smoothing
That's the point .
UltraGCN Study User-Item Graph
When GCN After infinite layers of messaging , The characterization of the last two layers should be the same :
e u = lim l → ∞ e u ( l + 1 ) = lim l → ∞ e u ( l ) e_{u}=\lim _{l \rightarrow \infty} e_{u}^{(l+1)}=\lim _{l \rightarrow \infty} e_{u}^{(l)} eu=l→∞limeu(l+1)=l→∞limeu(l)
So message aggregators can write :
e u = 1 d u + 1 e u + ∑ i ∈ N ( u ) 1 d u + 1 d i + 1 e i e_{u}=\frac{1}{d_{u}+1} e_{u}+\sum_{i \in \mathcal{N}(u)} \frac{1}{\sqrt{d_{u}+1} \sqrt{d_{i}+1}} e_{i} eu=du+11eu+i∈N(u)∑du+1di+11ei
Simplify :
e u = ∑ i ∈ N ( u ) β u , i e i , β u , i = 1 d u d u + 1 d i + 1 e_{u}=\sum_{i \in \mathcal{N}(u)} \beta_{u, i} e_{i}, \quad \beta_{u, i}=\frac{1}{d_{u}} \sqrt{\frac{d_{u}+1}{d_{i}+1}} eu=i∈N(u)∑βu,iei,βu,i=du1di+1du+1
So the above formula is the representation when all nodes converge . The author wants to communicate without displaying messages , Optimize directly to this state :

So the goal of optimization is to minimize the gap between the two sides of the equation , In other words, maximize the inner product of both sides :
max ∑ i ∈ N ( u ) β u , i e u ⊤ e i , ∀ u ∈ U \max \sum_{i \in \mathcal{N}(u)} \beta_{u, i} e_{u}^{\top} e_{i}, \quad \forall u \in U maxi∈N(u)∑βu,ieu⊤ei,∀u∈U
This is equivalent to maximizing e u e_u eu and e i e_i ei Cosine similarity of . For the sake of optimization , Also join sigmoid and negative log likelihood, therefore loss:
L C = − ∑ u ∈ U ∑ i ∈ N ( u ) β u , i log ( σ ( e u ⊤ e i ) ) \mathcal{L}_{C}=-\sum_{u \in U} \sum_{i \in \mathcal{N}(u)} \beta_{u, i} \log \left(\sigma\left(e_{u}^{\top} e_{i}\right)\right) LC=−u∈U∑i∈N(u)∑βu,ilog(σ(eu⊤ei))
But there are also over- smoothing The problem of , Would it be good if all the connected points were the same length ? So negative sampling can solve over- smoothing:
L C = − ∑ ( u , i ) ∈ N + β u , i log ( σ ( e u ⊤ e i ) ) − ∑ ( u , j ) ∈ N − β u , j log ( σ ( − e u ⊤ e j ) ) \mathcal{L}_{C}=-\sum_{(u, i) \in N^{+}} \beta_{u, i} \log \left(\sigma\left(e_{u}^{\top} e_{i}\right)\right)-\sum_{(u, j) \in N^{-}} \beta_{u, j} \log \left(\sigma\left(-e_{u}^{\top} e_{j}\right)\right) LC=−(u,i)∈N+∑βu,ilog(σ(eu⊤ei))−(u,j)∈N−∑βu,jlog(σ(−eu⊤ej))
here β u , i \beta_{u,i} βu,i The function is to control degree A little bit smaller , The impact will be greater ,degree The bigger the point, the smaller the impact .( This discord LightGCN The edge weight of ?)
hold RS Task as link prediction Mission , The main part of the model loss Also need not BPR loss, use BCE Loss:
L O = − ∑ ( u , i ) ∈ N + log ( σ ( e u ⊤ e i ) ) − ∑ ( u , j ) ∈ N − log ( σ ( − e u ⊤ e j ) ) \mathcal{L}_{O}=-\sum_{(u, i) \in N^{+}} \log \left(\sigma\left(e_{u}^{\top} e_{i}\right)\right)-\sum_{(u, j) \in N^{-}} \log \left(\sigma\left(-e_{u}^{\top} e_{j}\right)\right) LO=−(u,i)∈N+∑log(σ(eu⊤ei))−(u,j)∈N−∑log(σ(−eu⊤ej))
L = L O + λ L C \mathcal{L}=\mathcal{L}_{O}+\lambda \mathcal{L}_{C} L=LO+λLC
The model here is recorded as U l t r a G C N B a s e UltraGCN_{Base} UltraGCNBase, Intuitively understanding is in MF Based on the model , Let model reinforcement remember connected edges .
UltraGCN Study Item-Item Graph
GCN The model passes messages , Also learned implicitly item-item、user-user The relationship between , Here is how to learn item-item Relationship .
Construct a item-item Co-occurrence matrix G ∈ R ∣ I ∣ × ∣ I ∣ G \in \mathcal{R}^{|I| \times|I|} G∈R∣I∣×∣I∣:
G = A ⊤ A \begin{aligned} &G=A^{\top} A \end{aligned} G=A⊤A
G i , j G_{i,j} Gi,j Representative items i And objects j The co-occurrence times of . Define an item i and j The coefficient of ω i , j \omega_{i, j} ωi,j:
ω i , j = G i , j g i − G i , i g i g j , g i = ∑ k G i , k \omega_{i, j}=\frac{G_{i, j}}{g_{i}-G_{i, i}} \sqrt{\frac{g_{i}}{g_{j}}}, \quad g_{i}=\sum_{k} G_{i, k} ωi,j=gi−Gi,iGi,jgjgi,gi=k∑Gi,k
But compared with adjacency graph A A A , chart G G G very dense, You can't learn everything , The noise will be greater than the information .
Since the picture is too dense, Then make it sparse: according to ω i , j \omega_{i, j} ωi,j, Only the most similar K A neighbor item S ( i ) S(i) S(i) .
Compared with direct learning item-item Relationship , The article is ingenious augment positive user-item pairs to capture item-item relationships:
L I = − ∑ ( u , i ) ∈ N + ∑ j ∈ S ( i ) ω i , j log ( σ ( e u ⊤ e j ) ) \mathcal{L}_{I}=-\sum_{(u, i) \in N^{+}} \sum_{j \in S(i)} \omega_{i, j} \log \left(\sigma\left(e_{u}^{\top} e_{j}\right)\right) LI=−(u,i)∈N+∑j∈S(i)∑ωi,jlog(σ(eu⊤ej))
This is not to take ItemCF As a fake tag !
therefore UltraGCN Of loss Namely :
L = L O + λ L C + γ L I \mathcal{L}=\mathcal{L}_{O}+\lambda \mathcal{L}_{C}+\gamma \mathcal{L}_{I} L=LO+λLC+γLI
Here the model is very flexible , Any relationship can be learned :user-item, item-item, user-user, Knowledge map, etc . But here user-user The graph structure has no obvious improvement , because users’ interests are much broader than items’ attributes. Why does this go south 《Multi-behavior Recommendation with Graph Convolutional Networks》 Also used and explained .
UltraGCN Separate the relationships , Study alone , The effect must be better than GCN-based CF Mixed in with message passing The effect is good .
therefore UltraGCN and WRMF It's like , If at first WRMF We can use graph structure to give weight , There is no present GCN What happened to the model .
experimental result
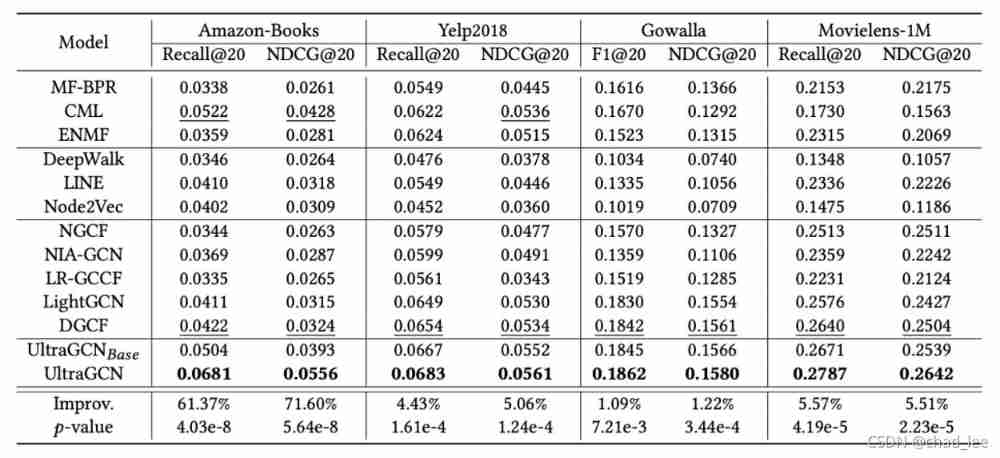

In addition, it also compares SCF, LCFN, NBPO, BGCF, and SGL-ED.
边栏推荐
- [M32] single chip microcomputer SVN setting ignore file
- CNN模型合集 | Resnet变种-WideResnet解读
- sessionStorage 和 localStorage 的使用
- How can we effectively alleviate anxiety? See what ape tutor says
- Generate string mode
- Armadillo安装
- Flink core features and principles
- MySQL ifnull processing n/a
- Cactus Song - March to C live broadcast (3)
- Data security practice guide - data collection security management
猜你喜欢
![Leetcode: interview question 08.12 Eight queens [DFS + backtrack]](/img/d0/e28af1a457f433b35972fd807b8ad7.png)
Leetcode: interview question 08.12 Eight queens [DFS + backtrack]

Introduction to 51 Single Chip Microcomputer -- digital clock

On the pit of delegatecall of solidity

In depth analysis of 20million OP events stolen by optimization (including code)

OpenGL - Draw Triangle
5g terminal identification Supi, suci and IMSI analysis

一个算子在深度学习框架中的旅程
关于solidity的delegatecall的坑
leetcode:面试题 08.12. 八皇后【dfs + backtrack】
Tpflow V6.0.6 正式版发布
随机推荐
自然语言处理理论和应用
六月集训(第22天) —— 有序集合
Single cell paper record (part6) -- space: spatial gene enhancement using scrna seq
Armadillo安装
MySQL Niuke brush questions
Pytest data parameterization & data driven
Rebuild binary tree
Databricks from open source to commercialization
Introduction to 51 Single Chip Microcomputer -- timer and external interrupt
Error encountered while importing keras typeerror: descriptors cannot not be created directly If this call came from a _
安装boost
PgSQL batch insert
Neuron+eKuiper 实现工业物联网数据采集、清理与反控
Detailed tutorial on connecting MySQL with tableau
Don't throw away the electric kettle. It's easy to fix!
【M32】单片机 xxx.map 文件简单解读
Laravel excel 3.1 column width setting does not work
SQL injection vulnerability (x) secondary injection
Leetcode: interview question 08.12 Eight queens [DFS + backtrack]
Cactus Song - online operation (4)