当前位置:网站首页>Detailed explanation of PPOCR detector configuration file parameters
Detailed explanation of PPOCR detector configuration file parameters
2022-08-05 10:49:00 【HUAWEI CLOUD】
@[toc]
配置文件参数介绍
以 rec_chinese_lite_train_v2.0.yml 为例
Global
| 字段 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| use_gpu | 设置代码是否在gpu运行 | true | \ |
| epoch_num | 最大训练epoch数 | 500 | \ |
| log_smooth_window | log队列长度,每次打印输出队列里的中间值 | 20 | \ |
| print_batch_step | 设置打印log间隔 | 10 | \ |
| save_model_dir | 设置模型保存路径 | output/{算法名称} | \ |
| save_epoch_step | 设置模型保存间隔 | 3 | \ |
| eval_batch_step | 设置模型评估间隔 | 2000 或 [1000, 2000] | 2000 表示每2000次迭代评估一次,[1000, 2000]表示从1000次迭代开始,每2000次评估一次 |
| cal_metric_during_train | 设置是否在训练过程中评估指标,此时评估的是模型在当前batch下的指标 | true | \ |
| load_static_weights | 设置预训练模型是否是静态图模式保存(目前仅检测算法需要) | true | \ |
| pretrained_model | 设置加载预训练模型路径 | ./pretrain_models/CRNN/best_accuracy | \ |
| checkpoints | 加载模型参数路径 | None | 用于中断后加载参数继续训练 |
| use_visualdl | 设置是否启用visualdl进行可视化log展示 | False | 教程地址 |
| infer_img | 设置预测图像路径或文件夹路径 | ./infer_img | \ |
| character_dict_path | 设置字典路径 | ./ppocr/utils/ppocr_keys_v1.txt | 如果为空,则默认使用小写字母+数字作为字典 |
| max_text_length | 设置文本最大长度 | 25 | \ |
| use_space_char | 设置是否识别空格 | True | \ |
| label_list | 设置方向分类器支持的角度 | [‘0’,‘180’] | 仅在方向分类器中生效 |
| save_res_path | 设置检测模型的结果保存地址 | ./output/det_db/predicts_db.txt | 仅在检测模型中生效 |
Optimizer
| 字段 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| name | 优化器类名 | Adam | 目前支持Momentum,Adam,RMSProp, 见[ppocr/optimizer/optimizer.py](file:/D:/cv/PaddleOCR-release-2.5/ppocr/optimizer/optimizer.py) |
| beta1 | 设置一阶矩估计的指数衰减率 | 0.9 | \ |
| beta2 | 设置二阶矩估计的指数衰减率 | 0.999 | \ |
| clip_norm | 所允许的二范数最大值 | \ | |
| lr | 设置学习率decay方式 | - | \ |
| name | 学习率decay类名 | Cosine | 目前支持Linear,Cosine,Step,Piecewise, 见[ppocr/optimizer/learning_rate.py](file:/D:/cv/PaddleOCR-release-2.5/ppocr/optimizer/learning_rate.py) |
| learning_rate | 基础学习率 | 0.001 | \ |
| regularizer | 设置网络正则化方式 | - | \ |
| name | 正则化类名 | L2 | 目前支持L1,L2, 见[ppocr/optimizer/regularizer.py](file:/D:/cv/PaddleOCR-release-2.5/ppocr/optimizer/regularizer.py) |
| factor | 正则化系数 | 0.00001 | \ |
Architecture
在PaddleOCR中,网络被划分为Transform,Backbone,Neck和Head四个阶段
| 字段 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| model_type | 网络类型 | rec | 目前支持rec,det,cls |
| algorithm | 模型名称 | CRNN | 支持列表见[algorithm_overview](file:/D:/cv/PaddleOCR-release-2.5/doc/doc_ch/algorithm_overview.md) |
| Transform | 设置变换方式 | - | 目前仅rec类型的算法支持, 具体见[ppocr/modeling/transforms](file:/D:/cv/PaddleOCR-release-2.5/ppocr/modeling/transforms) |
| name | 变换方式类名 | TPS | 目前支持TPS |
| num_fiducial | TPS控制点数 | 20 | 上下边各十个 |
| loc_lr | 定位网络学习率 | 0.1 | \ |
| model_name | 定位网络大小 | small | 目前支持small,large |
| Backbone | 设置网络backbone类名 | - | 具体见[ppocr/modeling/backbones](file:/D:/cv/PaddleOCR-release-2.5/ppocr/modeling/backbones) |
| name | backbone类名 | ResNet | 目前支持MobileNetV3,ResNet |
| layers | resnet层数 | 34 | 支持18,34,50,101,152,200 |
| model_name | MobileNetV3 网络大小 | small | 支持small,large |
| Neck | 设置网络neck | - | 具体见[ppocr/modeling/necks](file:/D:/cv/PaddleOCR-release-2.5/ppocr/modeling/necks) |
| name | neck类名 | SequenceEncoder | 目前支持SequenceEncoder,DBFPN |
| encoder_type | SequenceEncoder编码器类型 | rnn | 支持reshape,fc,rnn |
| hidden_size | rnn内部单元数 | 48 | \ |
| out_channels | DBFPN输出通道数 | 256 | \ |
| Head | 设置网络Head | - | 具体见[ppocr/modeling/heads](file:/D:/cv/PaddleOCR-release-2.5/ppocr/modeling/heads) |
| name | head类名 | CTCHead | 目前支持CTCHead,DBHead,ClsHead |
| fc_decay | CTCHead正则化系数 | 0.0004 | \ |
| k | DBHead二值化系数 | 50 | \ |
| class_dim | ClsHead输出分类数 | 2 | \ |
Loss
| 字段 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| name | 网络loss类名 | CTCLoss | 目前支持CTCLoss,DBLoss,ClsLoss |
| balance_loss | DBLossloss中是否对正负样本数量进行均衡(使用OHEM) | True | \ |
| ohem_ratio | DBLossloss中的OHEM的负正样本比例 | 3 | \ |
| main_loss_type | DBLossloss中shrink_map所采用的loss | DiceLoss | 支持DiceLoss,BCELoss |
| alpha | DBLossloss中shrink_map_loss的系数 | 5 | \ |
| beta | DBLossloss中threshold_map_loss的系数 | 10 | \ |
PostProcess
| 字段 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| name | 后处理类名 | CTCLabelDecode | 目前支持CTCLoss,AttnLabelDecode,DBPostProcess,ClsPostProcess |
| thresh | DBPostProcess中分割图进行二值化的阈值 | 0.3 | \ |
| box_thresh | DBPostProcess中对输出框进行过滤的阈值,低于此阈值的框不会输出 | 0.7 | \ |
| max_candidates | DBPostProcess中输出的最大文本框数量 | 1000 | |
| unclip_ratio | DBPostProcess中对文本框进行放大的比例 | 2.0 | \ |
Metric
| 字段 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| name | 指标评估方法名称 | CTCLabelDecode | 目前支持DetMetric,RecMetric,ClsMetric |
| main_indicator | 主要指标,用于选取最优模型 | acc | 对于检测方法为hmean,识别和分类方法为acc |
Dataset
| 字段 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| dataset | 每次迭代返回一个样本 | - | - |
| name | dataset类名 | SimpleDataSet | 目前支持SimpleDataSet和LMDBDataSet |
| data_dir | 数据集图片存放路径 | ./train_data | \ |
| label_file_list | 数据标签路径 | ["./train_data/train_list.txt"] | dataset为LMDBDataSet时不需要此参数 |
| ratio_list | 数据集的比例 | [1.0] | 若label_file_list中有两个train_list,且ratio_list为[0.4,0.6],则从train_list1中采样40%,从train_list2中采样60%组合整个dataset |
| transforms | 对图片和标签进行变换的方法列表 | [DecodeImage,CTCLabelEncode,RecResizeImg,KeepKeys] | 见[ppocr/data/imaug](file:/D:/cv/PaddleOCR-release-2.5/ppocr/data/imaug) |
| loader | dataloader相关 | - | |
| shuffle | 每个epoch是否将数据集顺序打乱 | True | \ |
| batch_size_per_card | 训练时单卡batch size | 256 | \ |
| drop_last | 是否丢弃因数据集样本数不能被 batch_size 整除而产生的最后一个不完整的mini-batch | True | \ |
| num_workers | 用于加载数据的子进程个数,若为0即为不开启子进程,在主进程中进行数据加载 | 8 | \ |
边栏推荐
- 【C语言指针】用指针提升数组的运算效率
- This notebook of concurrent programming knowledge points strongly recommended by Ali will be a breakthrough for you to get an offer from a big factory
- OpenHarmony如何查询设备类型
- Use KUSTO query statement (KQL) to query LOG on Azure Data Explorer Database
- 多线程(进阶) - 2.5w字总结
- 第四章:activiti RuntimeService设置获和取流程变量,及与taskService的区别,开始和完成任务时设置流程变量[通俗易懂]
- The host computer develops C# language: simulates the STC serial port assistant to receive the data sent by the microcontroller
- API 网关简述
- 【加密解密】明文加密解密-已实现【已应用】
- PCB布局必知必会:教你正确地布设运算放大器的电路板
猜你喜欢

The century-old Nordic luxury home appliance brand ASKO smart wine cabinet in the three-temperature area presents the Chinese Valentine’s Day, and tastes the love of the delicacy
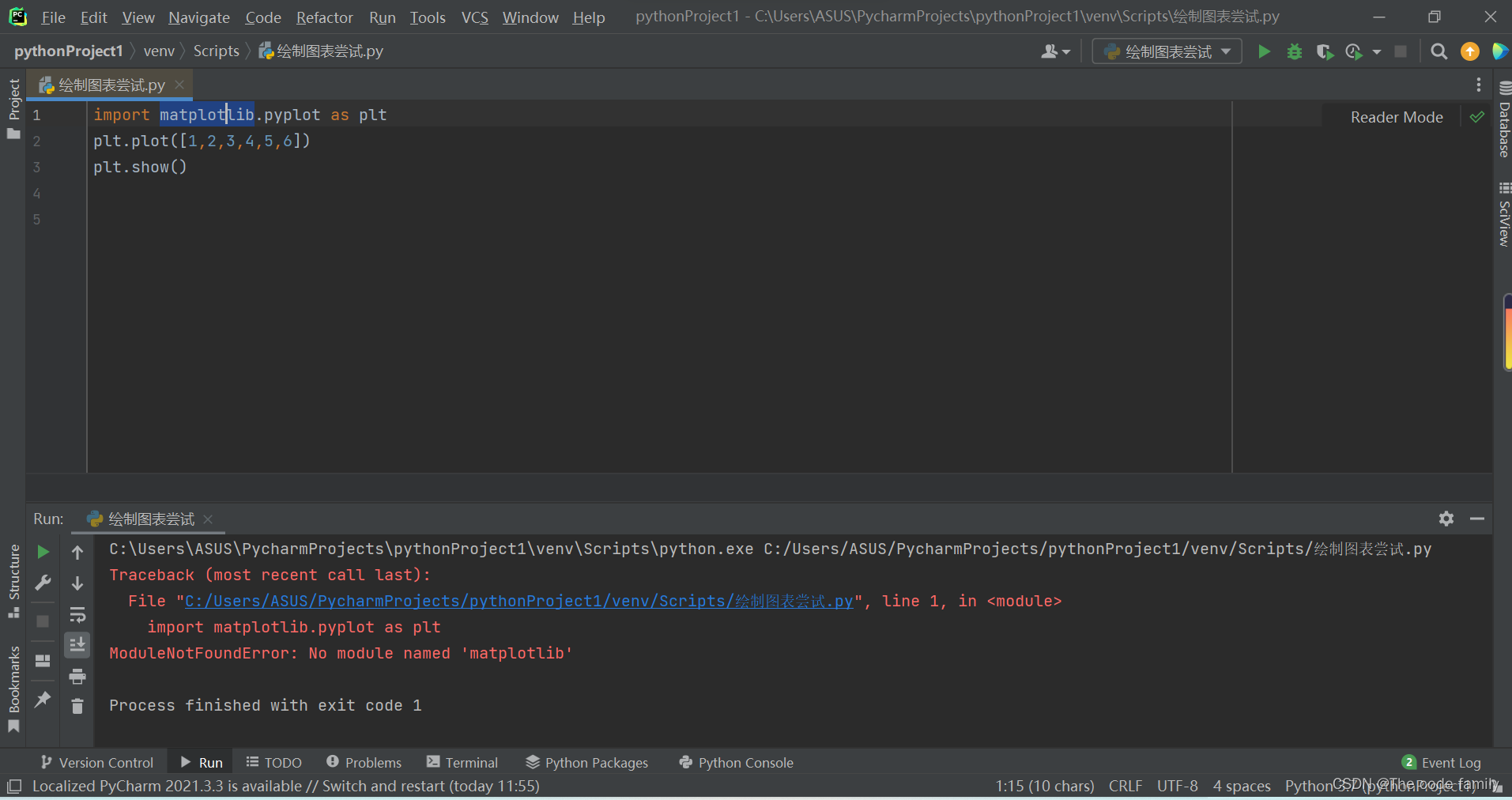
数据可视化(一)

Complete image segmentation efficiently based on MindSpore and realize Dice!

three objects are arranged in a spherical shape around the circumference
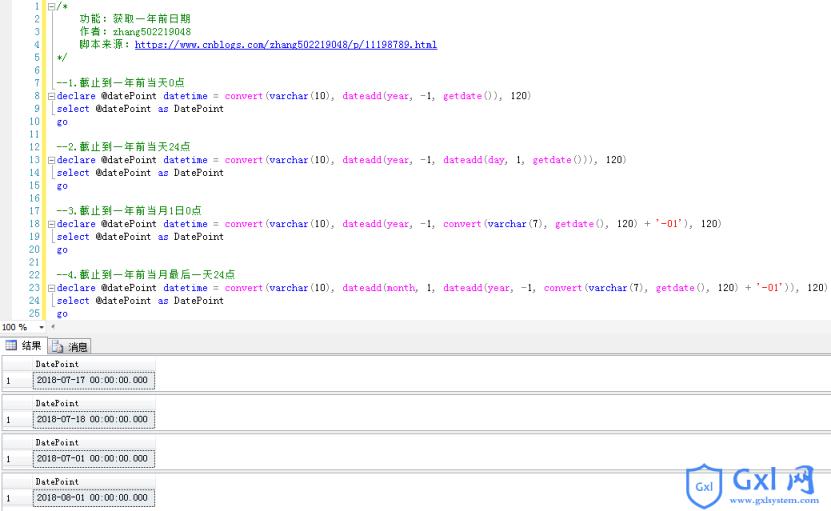
sqlserver编写通用脚本实现获取一年前日期的方法
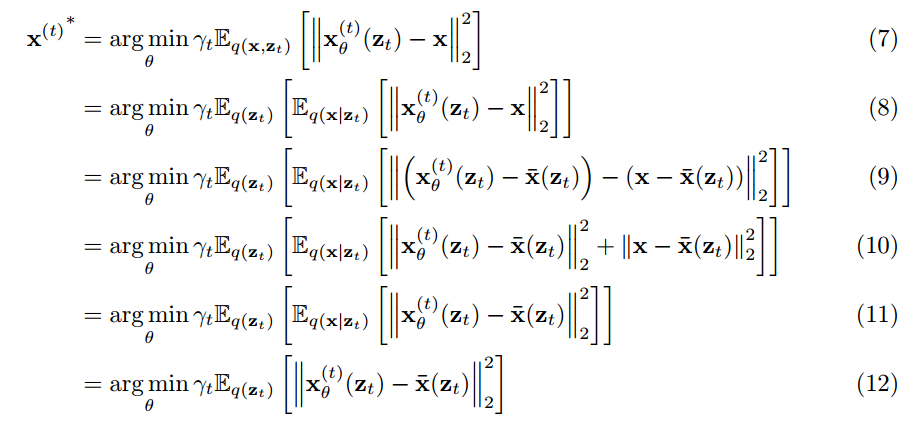
012_SSS_ Improving Diffusion Model Efficiency Through Patching
2022 Huashu Cup Mathematical Modeling Question A Optimization Design Ideas for Ring Oscillators Code Sharing
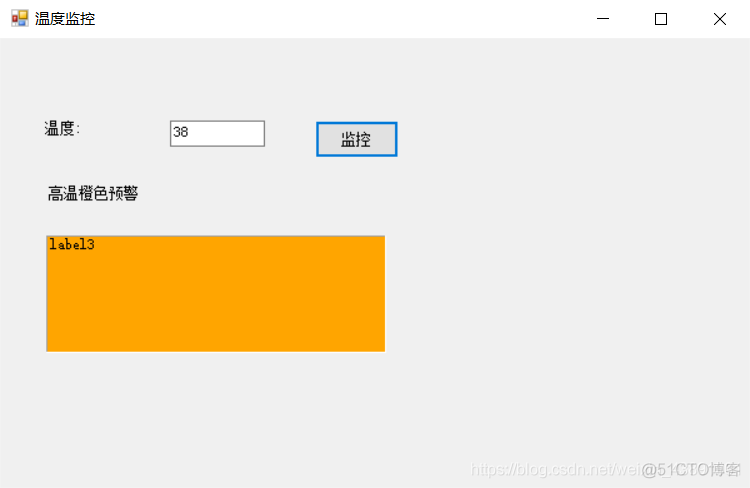
【 temperature warning program DE development 】 event driven model instance
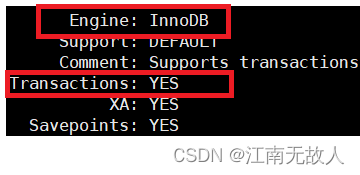
MySQL transactions
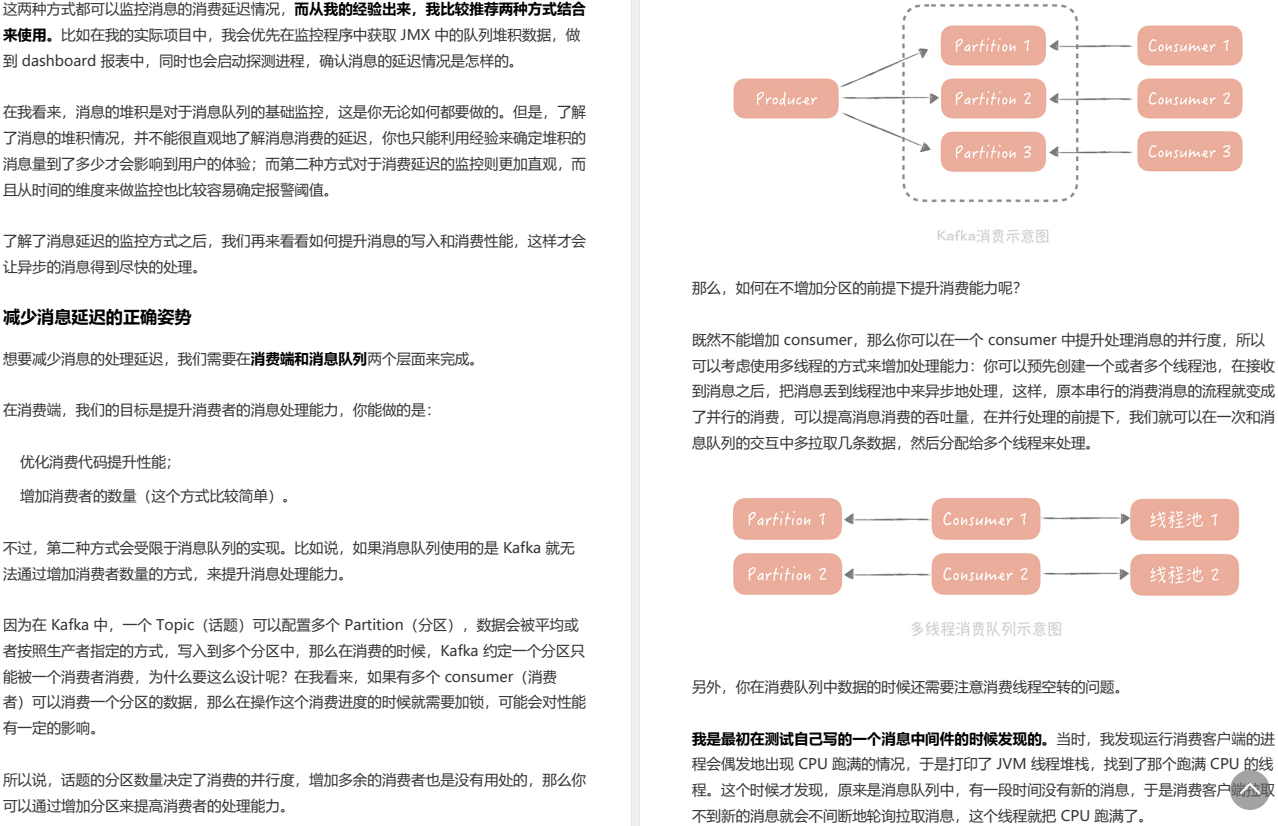
化繁为简!阿里新产亿级流量系统设计核心原理高级笔记(终极版)
随机推荐
FPGA:基础入门按键控制LED灯
智能算力的枢纽如何构建?中国云都的淮海智算中心打了个样
OpenHarmony如何查询设备类型
导火索:OAuth 2.0四种授权登录方式必读
Huawei's lightweight neural network architecture GhostNet has been upgraded again, and G-GhostNet (IJCV22) has shown its talents on the GPU
Leetcode刷题——623. 在二叉树中增加一行
第六章:activiti流程分流判断之排它网关和并行网关
Use KUSTO query statement (KQL) to query LOG on Azure Data Explorer Database
Import Excel/CSV from Sub Grid within Dynamics 365
RT-Thread记录(一、RT-Thread 版本、RT-Thread Studio开发环境 及 配合CubeMX开发快速上手)
SQL Outer Join Intersection, Union, Difference Query
FPGA:基础入门LED灯闪烁
上位机开发C#语言:模拟STC串口助手接收单片机发送数据
Technical dry goods | Hausdorff distance for image segmentation based on MindSpore
Login function and logout function (St. Regis Takeaway)
第八章:activiti多用户任务分配
负载均衡应用场景
解决【命令行/终端】颜色输出问题
The query that the user's test score is greater than the average score of a single subject
如何修改管理工具client_encoding