当前位置:网站首页>【ARIXV2204】Neighborhood attention transformer
【ARIXV2204】Neighborhood attention transformer
2022-07-28 05:01:00 【AI frontier theory group @ouc】

thank B standing “ The alchemy workshop of saury ” Explanation , The analysis here combines many explanations .
The paper :https://arxiv.org/abs/2204.07143
Code :https://github.com/SHI-Labs/Neighborhood-Attention-Transformer
This paper is very simple , In fact, ideas have also appeared in previous papers . First look at the picture below , standard VIT Of attention Calculation is global , Like the red one in the first picture token And the blue ones token Will be global and all token Calculate .swin Are the two figures in the middle , First step token Feature interaction is limited to local windows . Step 2 the window has shift, but token The feature interaction of is still in the local window . The last figure is proposed in this paper neighborhood attention transformer, NAT, all attention Is calculated in 7X7 In the neighborhood of . Looks like convolution equally , Just in one kernel Operate within the scope . But and convolution The difference is ,NAT It's calculation attention, So every one value The weight is determined according to the input value , Instead of a fixed value after training as in convolution kernel .

The author also gives attention Figure of calculation . As shown in the figure below , about CHW Input matrix of ,Query It's a certain place 1XC Vector , key It's a 3x3xC Matrix , The two matrices are multiplied element by element ( Different sizes broadcast ), The result is 3x3xC, Last in C Sum this dimension , obtain 3X3 The similarity matrix of . Use this matrix to value Assign weights , Finally merged into one 1x1xC Vector , Namely attention Calculated results of .

The author also analyzes the computational complexity , It can be seen that , Because calculating attention in local neighborhood , The calculation complexity is greatly reduced , and swin It's basically the same .

The overall architecture of the network is the same as the current method , All are 4 Stage . The resolution of each stage is reduced by half . however , The resolution reduction uses In steps of 2 Of 3X3 Convolution . First step overlapping tokenizer It uses 2 individual 3x3 Convolution , The step size of each convolution is 2.

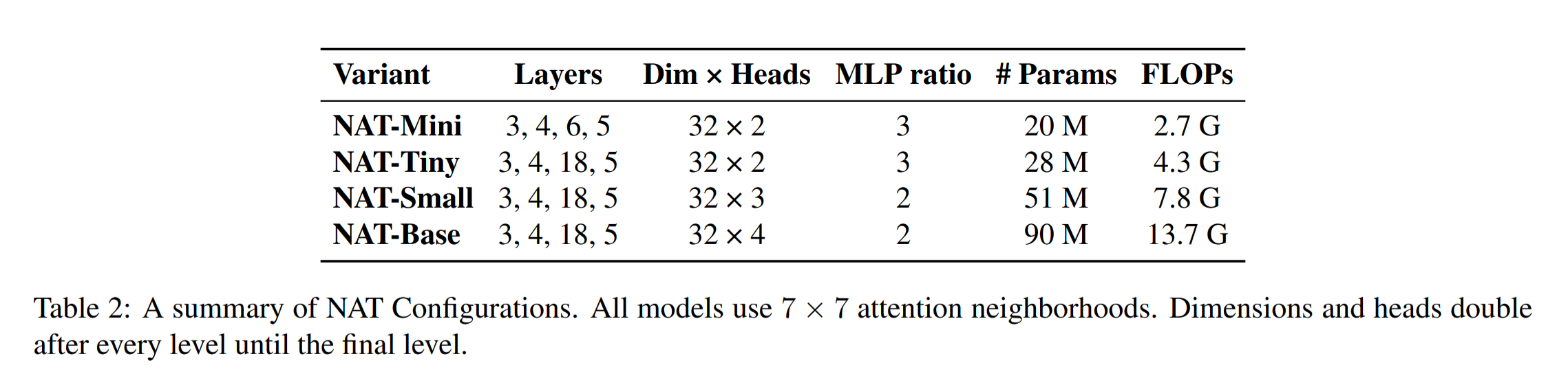
The author designed 4 It's a network structure , The neighborhood size is 7X7, As follows :
On the task of image classification ,NAT Very good performance , As shown in the following table :

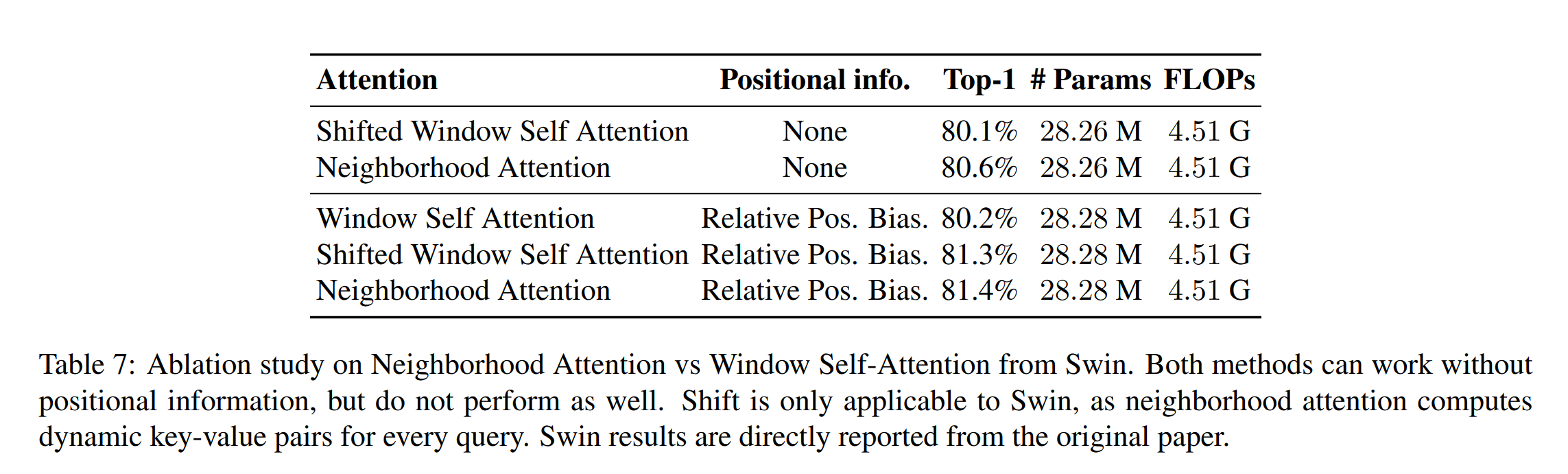
stay Ablation study Inside , The author contrasts postion embedding and attention The performance difference of calculation . however , The author's model is 81.4% , And the table above 83.2 There are differences , I don't know why .
in general , The idea of this paper is very simple , Many previous papers have also reflected this idea . But this paper is jointly done with enterprises , The difficulty should be CUDA Hardware implementation , The author wrote a lot of CUDA Code to right neighborhood The operation is accelerated .
边栏推荐
- Introduction to testcafe
- RT based_ Distributed wireless temperature monitoring system based on thread
- HDU 1522 marriage is stable
- Supervisor series: 5. Log
- Chuangyuan will join hands with 50+ cloud native enterprises to explore new models to cross the digital divide
- Paper reading notes -- crop yield prediction using deep neural networks
- Pipe /createpipe
- FPGA: use PWM wave to control LED brightness
- Easycvr Video Square snapshot adding device channel offline reason display
- Service object creation and use
猜你喜欢

What is the core value of testing?

Read the paper -- a CNN RNN framework for clip yield prediction

Win10 machine learning environment construction pycharm, anaconda, pytorch

Table image extraction based on traditional intersection method and Tesseract OCR

为什么md5不可逆,却还可能被md5免费解密网站解密
![[函数文档] torch.histc 与 paddle.histogram 与 numpy.histogram](/img/ee/ea918f79dc659369fde5394b333226.png)
[函数文档] torch.histc 与 paddle.histogram 与 numpy.histogram

Rendering process, how the code becomes a page (I)

阿里怎么用DDD来拆分微服务?

解析智能扫地机器人中蕴含的情感元素
Analyze the emotional elements contained in intelligent sweeping robot
随机推荐
What should testers know about login security?
Can plastics comply with gb/t 2408 - Determination of flammability
【内功心法】——函数栈帧的创建和销毁(C实现)
机器人教育在STEM课程中的设计研究
Program life | how to switch to software testing? (software testing learning roadmap attached)
CPU and memory usage are too high. How to modify RTSP round robin detection parameters to reduce server consumption?
CPU and memory usage are too high. How to modify RTSP round robin detection parameters to reduce server consumption?
RT_ Use of thread message queue
After easycvr is connected to the national standard equipment, how to solve the problem that the equipment video cannot be played completely?
Flink mind map
在外包公司两年了,感觉快要废了
Angr (XI) - official document (Part2)
What is the reason why the easycvr national standard protocol access equipment is online but the channel is not online?
Rendering process, how the code becomes a page (I)
Analysis of the reason why easycvr service can't be started and tips for dealing with easy disk space filling
Gan: generative advantageous nets -- paper analysis and the mathematical concepts behind it
Euler road / Euler circuit
启发国内学子学习少儿机器人编程教育
[paper notes] - low illumination image enhancement - zeroshot - rrdnet Network - 2020-icme
Activation functions sigmoid, tanh, relu in convolutional neural networks