当前位置:网站首页>AI mid-stage sequence labeling task: three data set construction process records
AI mid-stage sequence labeling task: three data set construction process records
2022-08-03 08:02:00 【Brother Mu Yao】
数据介绍
人民日报命名实体识别数据集(example.train 28046条数据和example.test 4636条数据),共3种标签:地点(LOC), 人名(PER), 组织机构(ORG)
时间识别数据集(time.train 1700条数据和time.test 300条数据),共1种标签:TIME
CLUENER细粒度实体识别数据集(cluener.train 10748条数据和cluener.test 1343条数据),共10种标签:地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
数据来源:GitHub
格式说明
原始格式:如图,每个字和label占一行,每句用空行隔开;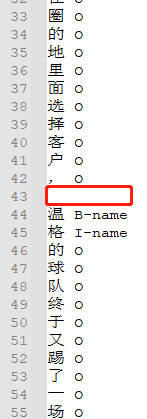
目标格式:每句一行,前面是用空格分开的字符 \t 后面是用空格分开的label,并生成一个label_map.json文件,如图(参考EasyDL).
代码实现
数据转换函数代码:
import os
def dataFucker(filepath):
new_filepath = filepath+'_new.txt'
f_new = open(new_filepath, 'w+', encoding="utf-8")
with open(filepath, 'r', encoding="utf-8") as f:
lines = f.read().split('\n\n')
for line in lines:
if not line:
continue
tokens_words = line.split('\n')
tokens, labels = [_.split(' ')[0].strip() for _ in tokens_words if _], [_.split(' ')[1].strip() for _ in tokens_words if _]
assert len(tokens) == len(labels)
new_line = ' '.join(tokens) + '\t' + ' '.join(labels) + '\n'
f_new.write(new_line)
f_new.close()
return new_filepath
数据转换入口函数:
import os
path = r"C:\xxx\data"
datasets = os.listdir(path)
for dataset in datasets:
filepath = os.path.join(path, dataset)
new_filepath = dataFucker(filepath)
print(filepath.split("\\")[-1], '---->', new_filepath.split("\\")[-1])
执行结果: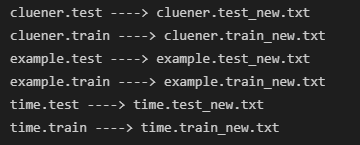
生成映射json文件代码:
import os
import json
def mapJsonFucker(filepath):
with open(filepath, 'r', encoding="utf-8") as f:
lines = f.readlines()
labels = []
for line in lines:
_labels = line.split('\t')[1].split(' ')
for each in _labels:
if each.strip() not in labels:
labels.append(each.strip())
labels.remove('O')
labels.append('O')
res = json.dumps({
key:value for value, key in enumerate(labels)}, indent=2)
with open(filepath+'_label_map.json', 'w+', encoding='utf-8') as fd:
fd.write(res)
return res
生成映射json文件入口函数:
path = r"C:\xxx\data"
datasets = [_ for _ in os.listdir(path) if 'txt' in _ and 'train' in _]
print(dataset)
for dataset in datasets:
filepath = os.path.join(path, dataset)
print(filepath)
resList = mapJsonFucker(filepath)
print(resList)
执行结果: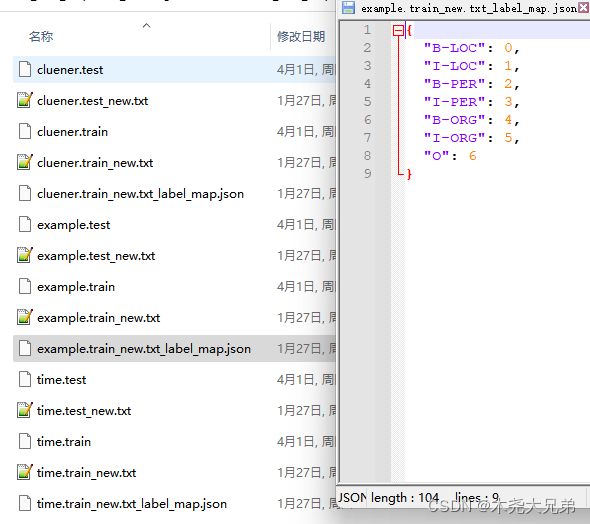
后续就可以根据自己需求处理了.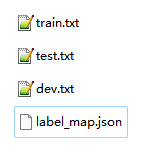
边栏推荐
猜你喜欢





随机推荐
Taro框架-微信小程序-内嵌h5页面
pyspark df secondary sorting
HCIP笔记整理 2022/7/20
第十二天&接口和协议
vs 2022无法安装 vc_runtimeMinmum_x86错误
REST学习
【着色器实现HandDrawn简笔画抖动效果_Shader效果第十二篇】
差分(前缀和的逆运算)
STL-vector容器
一文搞懂什么是@Component和@Bean注解以及如何使用
drop database出现1010
学习笔记:机器学习之逻辑回归
jolt语法
分治法求解中位数
智能客服,还有多少AI泡沫?
Docker启动mysql
从学生到职场的转变
数据库表结构文档 生成工具screw的使用
Nanny level explains Transformer
boot-SSE