当前位置:网站首页>[Python from zero to one] 5. Detailed explanation of beautiful soup basic syntax of web crawler
[Python from zero to one] 5. Detailed explanation of beautiful soup basic syntax of web crawler
2020-11-09 07:35:00 【osc_e4g3mco3】
Welcome to “Python From zero to one ”, Here I'm going to share an appointment 200 piece Python Series articles , Take everyone to study and play together , have a look Python This interesting world . All articles will be combined with cases 、 Code and author's experience , I really want to share my nearly ten years programming experience with you , I hope it will be of some help to you , There are also some shortcomings in the article .Python The overall framework of the series includes basic grammar 10 piece 、 Web crawler 30 piece 、 Visual analysis 10 piece 、 machine learning 20 piece 、 Big data analysis 20 piece 、 Image recognition 30 piece 、 Artificial intelligence 40 piece 、Python Security 20 piece 、 Other skills 10 piece . Your attention 、 Praise and forward is the greatest support for xiuzhang , Knowledge is priceless, man has love , I hope we can all be happy on the road of life 、 Grow up together .
The previous article talked about regular expression based Python Reptiles and Python Common crawler module , and Python Does the powerful network support ability and the rich expansion package also provide the related crawler package ? The answer is yes . This article focuses on BeautifulSoup technology .BeautifulSoup Is one can from HTML or XML Extracting data from a file Python library , An analysis HTML or XML File parser . This chapter will introduce BeautifulSoup technology , Includes the installation process and basic syntax , And by analyzing HTML Examples to introduce BeautifulSoup The process of parsing a web page .
This paper refers to the author CSDN The article , Links are as follows :
meanwhile , The author's new “ Na Zhang AI Safe house ” Will focus on Python And security technology , Mainly share Web penetration 、 System security 、 Artificial intelligence 、 Big data analysis 、 Image recognition 、 Malicious code detection 、CVE Reappear 、 Threat intelligence analysis, etc . Although the author is a technical white , But it will ensure that every article will be carefully written , I hope these basic articles will help you , stay Python And on the road to safety, progress with you .
List of articles
One . install BeautifulSoup
BeautifulSoup Is one can from HTML or XML Extracting data from a file Python expanded memory bank .BeautifulSoup Document navigation through appropriate Converters 、 lookup 、 Modify documents, etc . It can handle non-standard tags well and generate parse trees (Parse Tree); It provides navigation (Navigating), It can search and modify the parse tree easily and quickly .BeautifulSoup Technology is usually used to analyze the structure of web pages , Grab the corresponding Web file , For irregular HTML file , It provides a certain complement function , This saves developers time and energy . This chapter will take you into BeautifulSoup The reptiles of the sea , Here is a brief introduction BeautifulSoup The installation process of Technology .
1. setup script
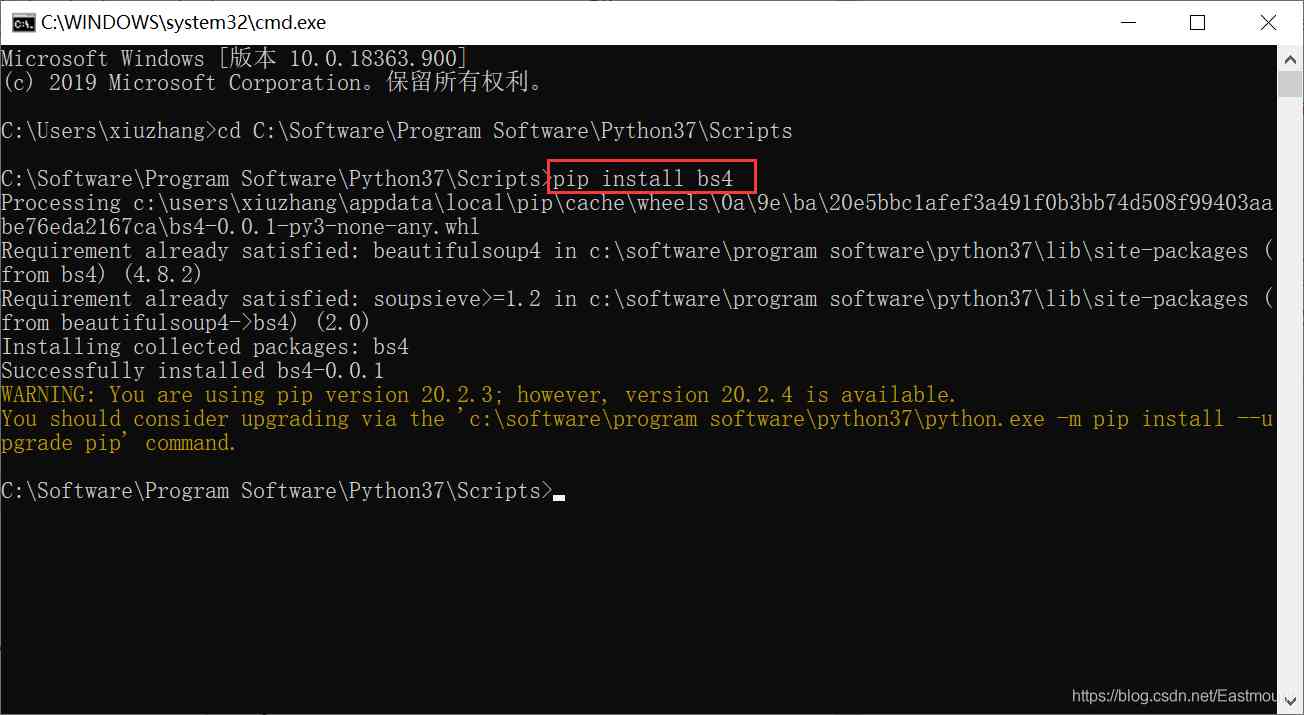
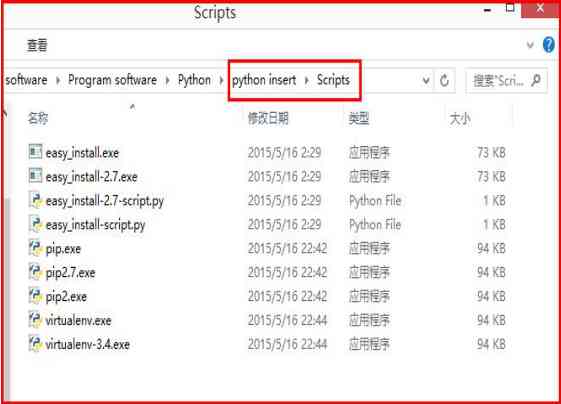
BeautifulSoup Installation is mainly through pip Order to proceed . As shown in the figure below , At the command prompt CMD In the environment , adopt cd Order to enter Python3.7 Installation directory Scripts Under the folder , Call again “pip install bs4” Command to install ,bs4 namely BeautifulSoup4. The installation command is as follows :
- cd C:\Software\Program Software\Python37\Scripts
- pip install bs4
When BeautifulSoup After the expansion pack is successfully installed , stay Python3.7 Input in “from bs4 import BeautifulSoup” Statement to import the extension package , Test the installation for success , If there is no exception, the installation is successful , As shown in the figure below .
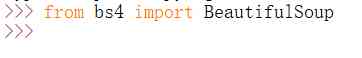
Enter the code as follows :
- from bs4 import BeautifulSoup
BeautifulSoup There are two common versions :BeautifulSoup 3 and BeautifulSoup 4( abbreviation BS4).BeautifulSoup 3 Development has been stopped , More of what is used in the project is BeautifulSoup 4, It has been transplanted to BS4 In the expansion pack . Readers are advised to install BeautifulSoup4, because BeautifulSoup3 Update stopped ; And if the reader uses Anaconda And so on , its BeautifulSoup The expansion pack is already installed , You can use it directly .
BeautifulSoup Support Python In the standard library HTML Parser , It also supports some third-party parsers , One of them is lxml, Another alternative parser is pure Python Realized html5lib,html5lib The parsing method is the same as the browser .Windows Call under the system pip or easy_install Command to install lxml, The code is as follows :
- pip install lxml
- easy_install lxml
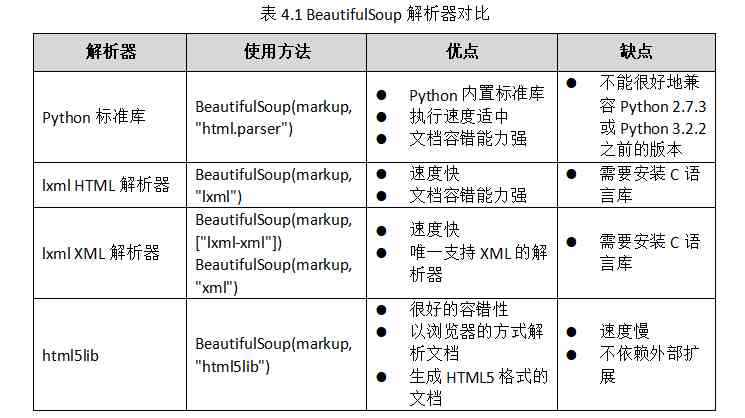
The following table lists them BeautifulSoup The main parsers in official documents and their advantages and disadvantages .
2.pip Install expansion pack usage
The previous installation procedure calls pip command , So what is it ?
pip It's a modern 、 General purpose Python Package management tools , Provide for the right to Python package (Package) Lookup 、 download 、 Install and uninstall features .Python Can pass easy_install perhaps pip Command to install various packages , among easy_insall Provides “ The fool ” Online one click installation of modules , and pip yes easy_install Improved version , Provide better tips and downloads 、 uninstall Python Package and other functions , The common usage is shown in the table below .

stay Python2 Used in older development environments pip Before the command , Need to install pip Software ( download pip-Win_1.7.exe The software is installed directly ), Call again pip Command to install the specific expansion pack , at present Python3 It's already embedded pip The tools are for direct use .
- http://pypi.python.org/pypi/pip#downloads
Python2 The old version is installed pip After the tool , It will be Python Add Scripts Catalog . stay Python2.7 in , The installed expansion pack will be in the directory Scripts Add the corresponding file under the folder , You even need to put this directory (Scripts) Add environment variables . install pip After success , Through the command “pip install bs4” install BeautifulSoup 4 Software .
The following table shows pip Common commands , One of the most commonly used commands is “install” and “uninstall”.
Usage: Basic usage
pip <command> [options] command Represents an operation command ,options Said parameters
Commands: Operation command
install Install the software
uninstall Uninstall software
freeze Output the list of installed software in a certain format
list List installed software
show Display software details
search Search software
wheel Set up as required wheel Expansion pack,
zip pack (zip) Single expansion pack , It is not recommended to use
unzip decompression (unzip) Single expansion pack , It is not recommended to use
help See help tips
General Options: Common options
-h, --help Display help
-v, --verbose More output , You can use at most 3 Time
-V, --version Display version information and exit
-q, --quiet Minimum output
--log-file <path> Record detailed output log in the form of overlay
--log <path> Record detailed output logs in a way that does not overlap .
--proxy <proxy> Specify port number
--timeout <sec> Set connection timeout ( Default 15 second )
--exists-action <action> There is default behavior in the settings , Optional parameters include :(s)witch、 (i)gnore、(w)ipe、(b)ackup
--cert <path> Set Certificate
Finally, official documents are recommended :
- https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
- https://pypi.org/project/beautifulsoup4/
Two . Quick start BeautifulSoup analysis
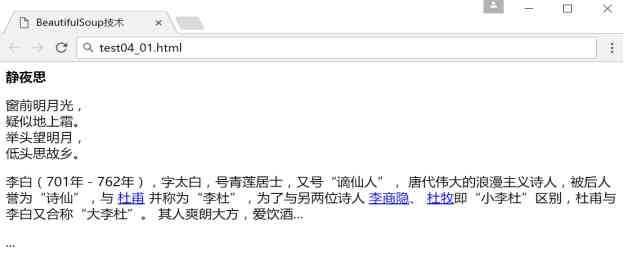
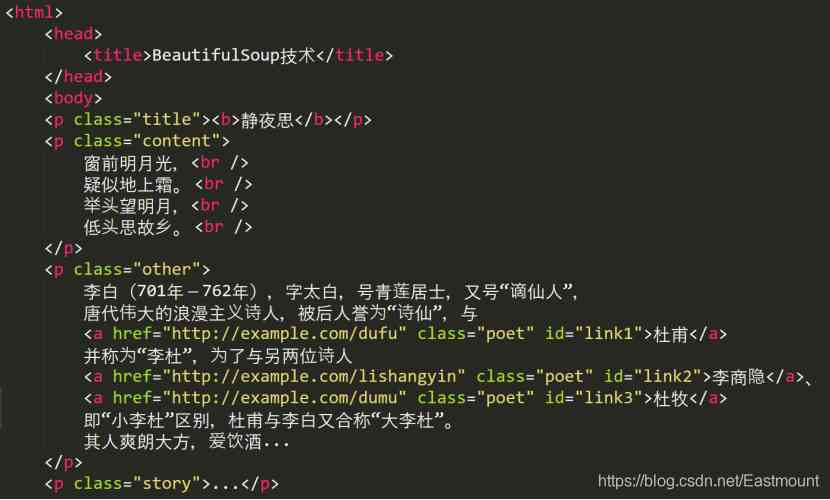
The following paragraph HTML Code (test04_01.html) It's a poem and description about Li Bai , It will be used many times as an example .HTML It is mainly written in the form of node pairs , Such as < html>< /html>、< body>< /body>、< a>< /a> etc. .
<html>
<head>
<title>BeautifulSoup technology </title>
</head>
<body>
<p class="title"><b> In the Quiet Night </b></p>
<p class="content">
The bright moon in front of the window ,<br />
Suspected frost on the ground . <br />
look at the bright moon ,<br />
Bow your head and think of your hometown . <br />
</p>
<p class="other">
Li Bai (701 year -762 year ), The words are too white , No. Qinglian householder , No “ The banished immortals ”,
The great romantic poet of Tang Dynasty , It is praised as “ Poetry fairy ”, And
<a href="http://example.com/dufu" class="poet" id="link1"> Du Fu </a>
And called “ Li Du ”, With two other poets
<a href="http://example.com/lishangyin" class="poet" id="link2"> Li shangyin </a>、
<a href="http://example.com/dumu" class="poet" id="link3"> Du Mu </a> namely “ Xiao Li Du ” difference , Du Fu and Li Bai are also called “ Big Li Du ”.
He is frank and generous , Love drinking ...</p>
<p class="story">...</p>
Open the web page through the browser, as shown in the figure below .
1.BeautifulSoup analysis HTML
The following code is passed through BeautifulSoup Analyze this paragraph HTML Webpage , Create a BeautifulSoup object , And then call BeautifulSoup Bag prettify() Function to format the output page .
# coding=utf-8
from bs4 import BeautifulSoup
#HTML Source code
html = """
<html>
<head>
<title>BeautifulSoup technology </title>
</head>
<body>
<p class="title"><b> In the Quiet Night </b></p>
<p class="content">
The bright moon in front of the window ,<br />
Suspected frost on the ground . <br />
look at the bright moon ,<br />
Bow your head and think of your hometown . <br />
</p>
<p class="other">
Li Bai (701 year -762 year ), The words are too white , No. Qinglian householder , No “ The banished immortals ”,
The great romantic poet of Tang Dynasty , It is praised as “ Poetry fairy ”, And
<a href="http://example.com/dufu" class="poet" id="link1"> Du Fu </a>
And called “ Li Du ”, With two other poets
<a href="http://example.com/lishangyin" class="poet" id="link2"> Li shangyin </a>、
<a href="http://example.com/dumu" class="poet" id="link3"> Du Mu </a> namely “ Xiao Li Du ” difference , Du Fu and Li Bai are also called “ Big Li Du ”.
He is frank and generous , Love drinking ...
</p>
<p class="story">...</p>
"""
# Output according to the structure of standard indentation format
soup = BeautifulSoup(html)
print(soup.prettify())
The output of the code is as follows , It's a web page HTML Source code .soup.prettify() take soup Content formatting output , use BeautifulSoup analysis HTML When the document , It will be HTML Document similar DOM Document tree processing .

Be careful : Previously defined HTML The source tag pair is missing the end tag , There's no label , But use prettify() The output of the function has been automatically filled with the end tag , This is a BeautifulSoup An advantage of .BeautifulSoup Even if you get a broken label , It also produces a transformation DOM Trees , And try to be consistent with the content of your original document , This approach can often help you gather data more correctly . in addition , We can also use local HTML File to create BeautifulSoup object , The code is as follows :
- soup = BeautifulSoup(open(‘test04_01.html’))
2. Simple access to web page tag information
When we have used BeautifulSoup After parsing the web page , If you want to get information between tags , How to achieve it ? Like getting tags < title> and < /title> Title Content . Below test02.py The code will teach you how to use BeautifulSoup The use of technology to get tag information , More systematic knowledge will be introduced in the third part .
# coding=utf-8
from bs4 import BeautifulSoup
# Create local file soup object
soup = BeautifulSoup(open('test04_01.html'), "html.parser")
# Get the title
title = soup.title
print(' title :', title)
This code gets HTML The title of the , The output is “< title>BeautifulSoup technology < /title>”. Again , You can get other tags , Such as HTML The head of (head).
# Get the title
head = soup.head
print(' Head :', head)
The output is “< head>< title>BeautifulSoup technology < /title>< /head>”. Another example is to get hyperlinks in web pages , By calling “soup.a” Code to get hyperlinks (< a></ a>).
# obtain a label
ta = soup.a
print(' Hyperlink content :', ta)
Output is “< a class=“poet” href=“http://example.com/dufu” id=“link1”> Du Fu < /a>”. among HTML There are three hyperlinks in , They correspond to Du Fu respectively 、 Li shangyin 、 Du Mu , and soup.a Return only the first hyperlink . that , If you want to get all the hyperlinks , How to write code to implement ? Later on find_all() Functions can be implemented .
Finally, the output of the first paragraph (< p>) Code for .
# obtain p label
tp = soup.p
print(' Paragraph content :', tp)
The output is “< p class=“title”>< b> In the Quiet Night < /b>< /p>”, among unicode() Function is used to transcode , Otherwise output Chinese garbled code . The output of the above code is shown in the figure below .

3. Locate the tag and get the content
The previous part briefly introduces BeautifulSoup label , Can get title、p、a And so on , But how to get the content corresponding to the specific tags that have been located ? The following code is to get all the hyperlink tags in the web page and the corresponding url Content .
# Find... From the document <a> All the tag links for
for a in soup.find_all('a'):
print(a)
# obtain <a> Hyperlinks for
for link in soup.find_all('a'):
print(link.get('href'))
The output result is shown in the figure below .find_all(‘a’) The function is to find all < a> label , And pass for Loop out the result ; the second for The cycle is through “link.get(‘href’)” The code gets the... In the hyperlink tag url website .

such as “< a class=“poet” href=“http://example.com/dufu” id=“link1”> Du Fu < /a>”, By calling find_all(‘a’) Function to get all the hyperlinks HTML Source code , Call again get(‘href’) Get the content of the hyperlink ,href The value of the property corresponds to :http://example.com/dufu. If you want to get text content , Call get_text() function .
for a in soup.find_all('a'):
print a.get_text()
The output is < a> and < /a> Link content between , As follows .
- Du Fu
- Li shangyin
- Du Mu
The following article will introduce the specific positioning node method in detail , Combined with practical examples to analyze and explain .
3、 ... and . Deepen understanding BeautifulSoup Reptiles
In the first part, we introduce BeautifulSoup Crawler installation process and introduction , In the second part, we learned quickly again BeautifulSoup technology , And this part will introduce in depth BeautifulSoup The grammar and usage of technology .
1.BeautifulSoup object
BeautifulSoup The complex HTML The document is converted into a tree structure , Every node is Python object ,BeautifulSoup The official document classifies all objects into the following four categories :
- Tag
- NavigableString
- BeautifulSoup
- Comment
Let's start with a detailed introduction to .
1.Tag
Tag Objects represent XML or HTML Tags in the document , Generally speaking, it is HTML Individual tags in , The object and HTML or XML The tags in the native document are the same .Tag There are many methods and properties ,BeautifulSoup Is defined as soup.Tag, among Tag by HTML The label in , such as head、title etc. , The result returns the complete tag content , Including the attributes and content of tags . for example :
<title>BeautifulSoup technology </title>
<p class="title"><b> In the Quiet Night </b></p>
<a href="http://example.com/lishangyin" class="poet" id="link2"> Li shangyin </a>
above HTML In the code ,title、p、a It's all tags , Start tag (< title>、< p>、< a>) And the end tag (< /title>、< /p>、< /a>) Add the content in between is Tag. Tag acquisition method code is as follows :

adopt BeautifulSoup Object readers can easily access tags and tag content , This is much more convenient than our regular expression crawler in the previous chapter . At the same time pay attention to , It returns the first tag of all tags that meets the requirements , such as “print soup.a” Statement returns the first hyperlink tag .
The following line of code is the type of output object , namely Tag object .
print type(soup.html)
# <class 'BeautifulSoup.Tag'>
Tag There are many methods and properties , This is explained in detail in traversing and searching document trees . Now let's introduce Tag The most important attribute in :name and attrs.
(1)name
name Property is used to get the tag name of the document tree , If you want to get head Name of label , Just use soup.head.name The code can be , For internal labels , The output value is the name of the tag itself .soup The object itself is special , its name by document, The code is as follows :

(2)attrs
attrs Attribute (attributes) Short for , Attribute is an important content of web page tag . A label (Tag) There may be many attributes , Take the example above :
<a href="http://example.com/dufu" class="poet" id="link1"> Du Fu </a>
It has two properties , One is class attribute , The corresponding value is “poet”; One is id attribute , The corresponding value is “link1”.Tag Attribute operation method and Python Dictionaries are the same , obtain p All attribute codes for tags are as follows , Get a dictionary type value , It takes the first paragraph p Properties and values of properties .
print(soup.p.attrs)
#{u'class': [u'title']}
If you need to get a property separately , Use the following two methods to get the hyperlink class Property value .
print(soup.a['class'])
#[u'poet']
print(soup.a.get('class'))
#[u'poet']
The following figure for HTML Source code , Get the first hyperlink as class=‘poet’.
BeautifulSoup Each label tag There may be many attributes , Can pass “.attrs” get attribute ,tag Properties of can be modified 、 Delete or add . Here is a simple example , The complete code is test03.py file .
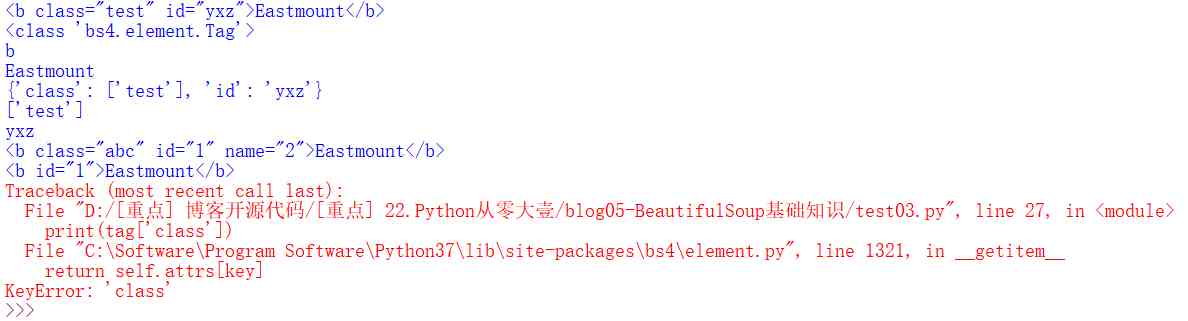
# coding=utf-8
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="test" id="yxz">Eastmount</b>',"html.parser")
tag = soup.b
print(tag)
print(type(tag))
#Name
print(tag.name)
print(tag.string)
#Attributes
print(tag.attrs)
print(tag['class'])
print(tag.get('id'))
# Modify properties Attribute added name
tag['class'] = 'abc'
tag['id'] = '1'
tag['name'] = '2'
print(tag)
# Delete attribute
del tag['class']
del tag['name']
print(tag)
print(tag['class'])
#KeyError: 'class'
The output result is shown in the figure , Including modifying properties class、id, Attribute added name, Delete attribute class、name Other results .
Be careful :HTML Defines a series of properties that can contain multiple values , The most common property that can contain multiple values is class, There are also some properties such as rel、rev、accept-charset、headers、accesskey etc. ,BeautifulSoup The return type of a multivalued property in is list, Please refer to BeautifulSoup Learn on the official website .
2.NavigableString
We talked about getting tags Name and Attributes, So if you want to get the content of the tag , How to achieve it ? You may have guessed , Use string Attribute to get the tag <> And </> Content between . such as :
print(soup.a['class'])
#[u'poet']
print(soup.a['class'].string)
# Du Fu
obtain “< a href=“http://example.com/dufu” class=“poet” id=“link1”> Du Fu < /a>” Content between , Is it much more convenient than the regular expressions introduced in the previous article .
BeautifulSoup use NavigableString Class to packaging tag String in ,NavigableString Represents a traversable string . One NavigableString String and Python Medium Unicode Same string , It also supports some features included in traversing and searching document trees . Use the following code to see NavigableString The type of .
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('test04_01.html'), "html.parser")
tag = soup.title
print(type(tag.string))
#<class 'BeautifulSoup.NavigableString'>
Be careful , The old version Python2 Need to pass through unicode() The method can directly transfer NavigableString Object conversion to Unicode character string , Then carry out the relevant operation . If the string contained in the tag cannot be edited , But it can be replaced with other strings , use replace_with() Method realization . The code is as follows :
tag.string.replace_with(" replace content ")
print(tag)
#<title> replace content </title>
replace_with() Function will “< title>BeautifulSoup technology < /title>” The content of the title in is from “BeautifulSoup technology ” replaced “ replace content ”.NavigableString Object supports traversing the document tree and searching for most of the properties defined in the document tree , And strings can't contain anything else (tag Objects can contain strings or other things tag), String does not support “.contents” or “.string ” Attribute or find() Method .
Official documents remind : In older versions Python2 in , If you want to BeautifulSoup Use outside NavigableString object , Need to call unicode() Method , Convert the normal object to Unicode character string , Otherwise, it would be BeautifulSoup The method of has been executed , The output of the object will also have the reference address of the object , So it's a waste of memory .
3.BeautifulSoup
BeautifulSoup Object represents the whole content of a document , It is usually regarded as Tag object , This object supports traversing the document tree and searching most of the methods described in the document tree , See the next section . The following code is the output soup Type of object , The output is BeautifulSoup object type .
print(type(soup))
# <class 'BeautifulSoup.BeautifulSoup'>
Be careful : because BeautifulSoup The object is not really HTML or XML The label of tag, So it doesn't have name and attribute attribute . But sometimes check it out “.name” Attributes are very convenient , so BeautifulSoup Object contains a value of “[document]” The special properties of “soup.name”. The following code is the output BeautifulSoup Object's name attribute , Its value is “[document]”.
print(soup.name)
# u'[document]'
4.Comment
Comment The object is of a special type NavigableString object , It is used to handle annotation objects . The following example code is used to read the comments , The code is as follows :
markup = "<b><!-- This is a comment code. --></b>"
soup = BeautifulSoup(markup, "html.parser")
comment = soup.b.string
print(type(comment))
# <class 'bs4.element.Comment'>
print(comment)
# This is a comment code.
The output result is shown in the figure below :

2. Traverse the document tree
After introducing these four objects , The following is a brief introduction to traversing the document tree and searching the document tree and the commonly used functions . stay BeautifulSoup in , A label (Tag) It may contain multiple strings or other tags , These are called sub tags of this tag , Let's start with the child node .
1. Child node
BeautifulSoup Pass through contents Value get tag (Tag) Child node content of , And output in the form of a list . With test04_01.html Code, for example , The code to get the content of the tag child node is as follows :
# coding=utf-8
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('test04_01.html'), "html.parser")
print(soup.head.contents)
#['\n', <title>BeautifulSoup technology </title>, '\n']
Because of the headlines < title> and < /title> There are two line breaks , So the list we get includes two newlines , If you need to extract the second element , The code is as follows :

Another way to get child nodes is children keyword , But it doesn't return a list, Can pass for Loop to get the contents of all child nodes . The method is as follows :
print(soup.head.children)
for child in soup.head.children:
print(child)
#<listiterator object at 0x00000000027335F8>
Previously introduced contents and children Property contains only the immediate child nodes of the tag , If you need to get Tag All child nodes of , Even sun node , You need to use descendants attribute , The method is as follows :
for child in soup.descendants:
print(child)
The output is shown in the following figure , be-all HTML The labels are printed out .

2. Node content
If the tag has only one child node , You need to get the content of this child node , Then use string attribute , Output the contents of child nodes , Usually returns the innermost label content . For example, the code to get the title content is as follows :
print(soup.head.string)
# None
print(soup.title.string)
# BeautifulSoup technology
When a tag contains multiple child nodes ,Tag You can't be sure string Get the content of which child node , At this point, the output is None, Like getting < head> The content of , The return value is None, Because it includes two newline elements . If you need to get the content of multiple nodes , Then use strings attribute , The sample code is as follows :
for content in soup.strings:
print(content)
But the output string may contain extra spaces or newlines , You need to use stripped_strings Methods to remove the redundant blank content , The code is as follows :
for content in soup.stripped_strings:
print(content)
The results are shown in the figure .

3. Parent node
call parent Attribute to locate the parent node , If you need to get the node's tag name, use parent.name, The code is as follows :
p = soup.p
print(p.parent)
print(p.parent.name)
#<p class="story">...</p></body>
#body
content = soup.head.title.string
print(content.parent)
print(content.parent.name)
#<title>BeautifulSoup technology </title>
#title
If you need to get all the parent nodes , Then use parents Property loop acquisition , The code is as follows :
content = soup.head.title.string
for parent in content.parents:
print(parent.name)
4. Brother node
A sibling node is a node at the same level as this node , among next_sibling Property is to get the next sibling of the node ,previous_sibling On the contrary , Take the previous sibling node of the node , If the node doesn't exist , Then return to None.
- print(soup.p.next_sibling)
- print(soup.p.prev_sibling)
Be careful : In the actual document tag Of next_sibling and previous_sibling Properties are usually strings or blanks , Because whitespace or newline can also be considered as a node , So the result may be blank or line feed . Empathy , adopt next_siblings and previous_siblings Property can get all the siblings of the current node , Then call the loop iteration output .
5. Front and back nodes
Call the property next_element You can get the next node , Call the property previous_element You can get the last node , The code example is as follows :
- print(soup.p.next_element)
- print(soup.p.previous_element)
Empathy , adopt next_siblings and previous_elements Property can get all the siblings of the current node , And call loop iteration output . Be careful , If prompted incorrectly “TypeError: an integer is required”, You need to add unicode() Function is converted to Chinese encoding output .
3. Search document tree
Search document tree the author mainly explains find_all() Method , This is one of the most commonly used methods , More of this is similar to traversing the document tree , Include parent nodes 、 Child node 、 Brother node, etc , It is recommended that readers learn by themselves from the official website . If you want to get all the tags from the web page , Use find_all() The code of the method is as follows :
urls = soup.find_all('a')
for u in urls:
print(u)
# <a class="poet" href="http://example.com/dufu" id="link1"> Du Fu </a>
# <a class="poet" href="http://example.com/lishangyin" id="link2"> Li shangyin </a>
# <a class="poet" href="http://example.com/dumu" id="link3"> Du Mu </a>
The output result is shown in the figure below :

Be careful : If you misreport “‘NoneType’ object is not callable using ‘find_all’ in BeautifulSoup”, The reason is the need to install BeautifulSoup4 Version or bs4, Because of the method find_all() It belongs to this edition . and BeautifulSoup3 The method used is as follows :
- from BeautifulSoup import BeautifulSoup
- soup.findAll(‘p’, align=“center”)
Again , This function supports passing in regular expressions as parameters ,BeautifulSoup Through regular expressions match() To match the content . In the following example, find out all of them with b Example of the tag at the beginning :
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
# br
# br
The output includes letters “b” The tag name of , Such as body、b、br、br etc. . If you want to get tags a And labels b Value , Then use the following function :
- soup.find_all([“a”, “b”])
Be careful find_all() Function can accept parameters to query the specified node , The code is as follows :
soup.find_all(id='link1')
# <a class="poet" href="http://example.com/dufu" id="link1"> Du Fu </a>
You can also accept multiple parameters , such as :
soup.find_all("a", class_="poet")
# <a class="poet" href="http://example.com/dufu" id="link1"> Du Fu </a>
# <a class="poet" href="http://example.com/lishangyin" id="link2"> Li shangyin </a>
# <a class="poet" href="http://example.com/dumu" id="link3"> Du Mu </a>
Here we are. ,BeautifulSoup The basic knowledge and usage have been described , Next, a simple example is given to illustrate BeautifulSoup Crawling network data , Here's an example from the last article , Access the home page information of the author's personal blog . meanwhile , more BeautifulSoup Technical knowledge recommends that you go to its official website to learn , The website is :
Four .BeautifulSoup Simply crawl to personal blog sites
The last article described a simple example of a regular expression crawling through a personal blog site , The following interpretation BeautifulSoup Technology crawls personal blog website content .BeautifulSoup Provides some methods and classes Python Syntax to find a transformation tree , Help you parse a tree and locate what you need . The author's personal website address is :
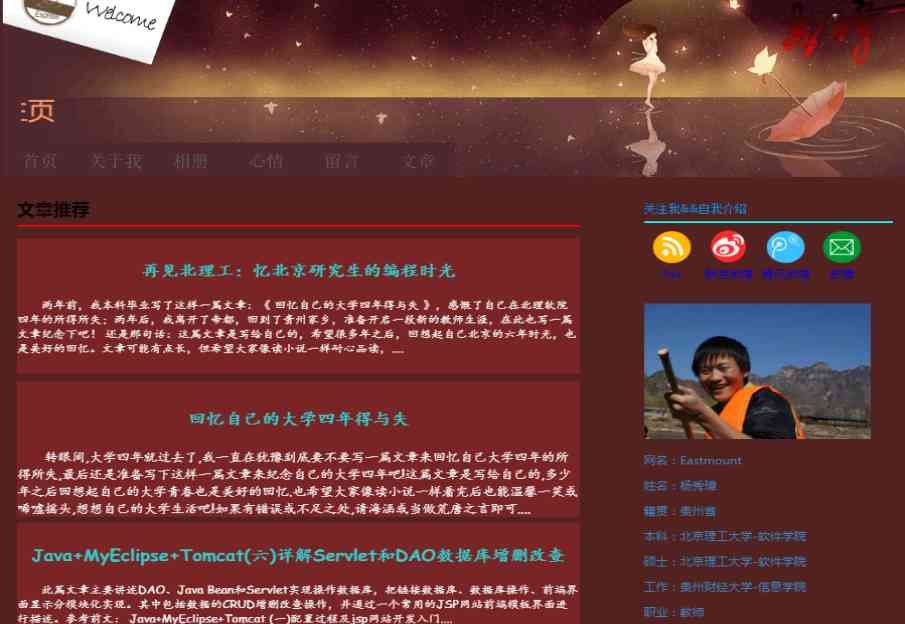
Now you need to crawl through the titles of the four articles on the front page of your blog 、 Hyperlinks and Abstracts , For example, the title is “ Goodbye, North Tech : Remember the programming time of graduate students in Beijing ”.
First , Locate the source code of these elements through the browser , Find the law between them , This is called DOM Tree document node tree analysis , Find the attribute and attribute value corresponding to the crawling node , As shown in the figure .
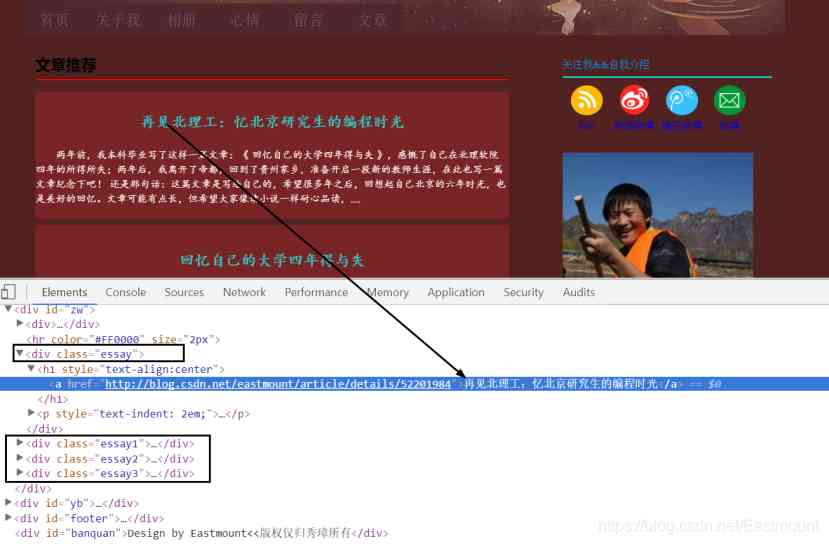
The title is at < div class=”essay”>< /div> Under the position , It includes a < h1>< /h1> Record the title , One < p>< /p> Record summary information , The nodes of the other three articles are < div class=”essay1”>< /div>、< div class=”essay2”>< /div> and < div class=”essay3”>< /div>. Now you need to get the title of the first article 、 The code for hyperlinks and summaries is as follows :
# -*- coding: utf-8 -*-
import re
import urllib.request
from bs4 import BeautifulSoup
url = "http://www.eastmountyxz.com/"
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, "html.parser")
essay0 = soup.find_all(attrs={
"class":"essay"})
for tag in essay0:
print(tag)
print('') # Line break
print(tag.a)
print(tag.find("a").get_text())
print(tag.find("a").attrs['href'])
content = tag.find("p").get_text()
print(content.replace(' ',''))
print('')
The output result is shown in the figure below , The code soup.find_all(attrs={“class”:“essay”}) Used to get nodes < div class=“essay”> The content of , Then we use the loop output , But it's time to class The type contains only one paragraph . And then locate div Hyperlinks in , adopt tag.find(“a”).get_text() Get content ,tag.find(“a”).attrs[‘href’] Get hyperlinks url, Finally get the paragraph summary .

Empathy , The code for crawling the rest of the articles is as follows , Get through a loop essay1、essay2、essay3 Content , these div The format in the layout is the same , Include a title and a summary information , The code is as follows :
# Organize output
i = 1
while i<=3:
num = "essay" + str(i)
essay = soup.find_all(attrs={
"class":num})
for tag in essay:
print(tag.find("a").get_text())
print(tag.find("a").attrs['href'])
content = tag.find("p").get_text()
print(content.replace(' ',''))
i += 1
print('')
The output is as follows :

Whole BeautifulSoup The reptiles have finished , Is it much more convenient than the previous regular expression , And crawling functions are more intelligent . The following will be combined with the case in-depth explanation BeautifulSoup Actual operation , Including crawling through movie information 、 Storage database, etc .
5、 ... and . Summary of this chapter
BeautifulSoup Is one can from HTML or XML Extract the required data from a file Python library , Here the author sees it as a technology .
- On the one hand, it has the powerful function of intelligent crawling web information , Compare the regular expression crawler above , You can appreciate its convenience and applicability ,BeautifulSoup By loading the entire web document and calling the relevant functions to locate the node of the required information , And then crawl the relevant content .
- On the other hand ,BeautifulSoup It's easy to use ,API Very human , Use something similar to XPath Analysis technology positioning label , And support CSS Selectors , The development efficiency is relatively high , Widely used in Python Data crawling domain . So the author sees it as a kind of crawler technology , Next, through a complete crawler case to deepen the reader's impression .
All code download address of this series :
I appreciate :
- [Python From zero to one ] One . Why should we learn Python And basic grammar
- [Python From zero to one ] Two . The conditional sentence of grammatical basis 、 Loop statements and functions
- [Python From zero to one ] 3、 ... and . File manipulation of syntax basis 、CSV File reading and writing and object-oriented
- [Python From zero to one ] Four . Introduction to web crawler and regular expression capture blog case
- [Python From zero to one ] 5、 ... and . Web crawler BeautifulSoup A detailed explanation of basic grammar
Last , Thank you for your attention “ Na Zhang's home ” official account , thank CSDN So many years of company , Will always insist on sharing , I hope your article can accompany me to grow up , I also hope to keep moving forward on the road of technology . If the article is helpful to you 、 Have an insight , It's the best reward for me , Let's see and cherish !2020 year 8 month 18 The official account established by Japan , Thank you again for your attention , Please help to promote it “ Na Zhang's home ”, ha-ha ~ Newly arrived , Please give me more advice .

The goddess of Thanksgiving , Thank you and think far ~

(By: Na Zhang's home Eastmount 2020-11-08 Night in Guiyang https://blog.csdn.net/Eastmount )
The references are as follows :
- Author books 《Python Network data crawling and analysis from the beginning to proficient 》
- The author blog :https://blog.csdn.net/Eastmount
版权声明
本文为[osc_1b9czlr5]所创,转载请带上原文链接,感谢
边栏推荐
- 非阻塞的无界线程安全队列 —— ConcurrentLinkedQueue
- Linked blocking queue based on linked list
- 当我们聊数据质量的时候,我们在聊些什么?
- Factory Pattern模式(简单工厂、工厂方法、抽象工厂模式)
- App crashed inexplicably. At first, it thought it was the case of the name in the header. Finally, it was found that it was the fault of the container!
- Concurrent linked queue: a non blocking unbounded thread safe queue
- 对象
- OSChina 周一乱弹 —— 程序媛的青春
- 商品管理系统——SPU检索功能
- C/C++编程笔记:指针篇!从内存理解指针,让你完全搞懂指针
猜你喜欢

For the first time open CSDN, this article is for the past self and what is happening to you
梁老师小课堂|谈谈模板方法模式
无法启动此程序,因为计算机中丢失 MSVCP120.dll。尝试安装该程序以解决此问题
GDI 及OPENGL的区别
写时复制集合 —— CopyOnWriteArrayList
Windows环境下如何进行线程Dump分析
The vowels in the inverted string of leetcode
商品管理系统——SPU检索功能
Salesforce connect & external object
操作系统之bios
随机推荐
Linked blocking queue based on linked list
Service grid is still difficult - CNCF
When we talk about data quality, what are we talking about?
Review of API knowledge
Five design patterns frequently used in development
The vowels in the inverted string of leetcode
Pipedrive如何在每天部署50+次的情况下支持质量发布?
上线1周,B.Protocal已有7000ETH资产!
B. protocal has 7000eth assets in one week!
Sublime text3 插件ColorPicker(调色板)不能使用快捷键的解决方法
自然语言处理(NLP)路线图 - kdnuggets
How does FC game console work?
第五章编程
Adding OpenGL form to MFC dialog
当我们聊数据质量的时候,我们在聊些什么?
2. Introduction to computer hardware
Android emulator error: x86 emulation currently requires hardware acceleration的解决方案
服务网格仍然很难 - cncf
APP 莫名崩溃,开始以为是 Header 中 name 大小写的锅,最后发现原来是容器的错!
Exception capture and handling in C + +