当前位置:网站首页>[Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
[Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
2020-11-09 07:35:00 【osc_1b9czlr5】
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了基于正则表达式的Python爬虫以及Python常用的爬虫模块,而Python强大的网络支持能力和丰富的扩展包是否也提供了相关的爬虫包呢?答案是肯定的。本篇文章主要讲解BeautifulSoup技术。BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,一个分析HTML或XML文件的解析器。本章将介绍BeautifulSoup技术,包括安装过程和基础语法,并通过分析HTML实例来介绍BeautifulSoup解析网页的过程。
本文参考了作者CSDN的文章,链接如下:
同时,作者新开的“娜璋AI安全之家”将专注于Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等文章。虽然作者是一名技术小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在Python和安全路上与大家一起进步。
文章目录
一.安装BeautifulSoup
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python扩展库。BeautifulSoup通过合适的转换器实现文档导航、查找、修改文档等。它可以很好的处理不规范标记并生成剖析树(Parse Tree);它提供的导航功能(Navigating),可以简单又快速地搜索剖析树以及修改剖析树。BeautifulSoup技术通常用来分析网页结构,抓取相应的Web文档,对于不规则的HTML文档,它提供了一定的补全功能,从而节省了开发者的时间和精力。本章将带领您走进BeautifulSoup爬虫的海洋,下面先简单介绍BeautifulSoup技术的安装过程。
1.安装过程
BeautifulSoup安装主要通过pip指令进行。如下图所示,在命令提示符CMD环境下,通过cd命令进入Python3.7安装目录的Scripts文件夹下,再调用“pip install bs4”命令安装,bs4即BeautifulSoup4。安装命令如下:
- cd C:\Software\Program Software\Python37\Scripts
- pip install bs4
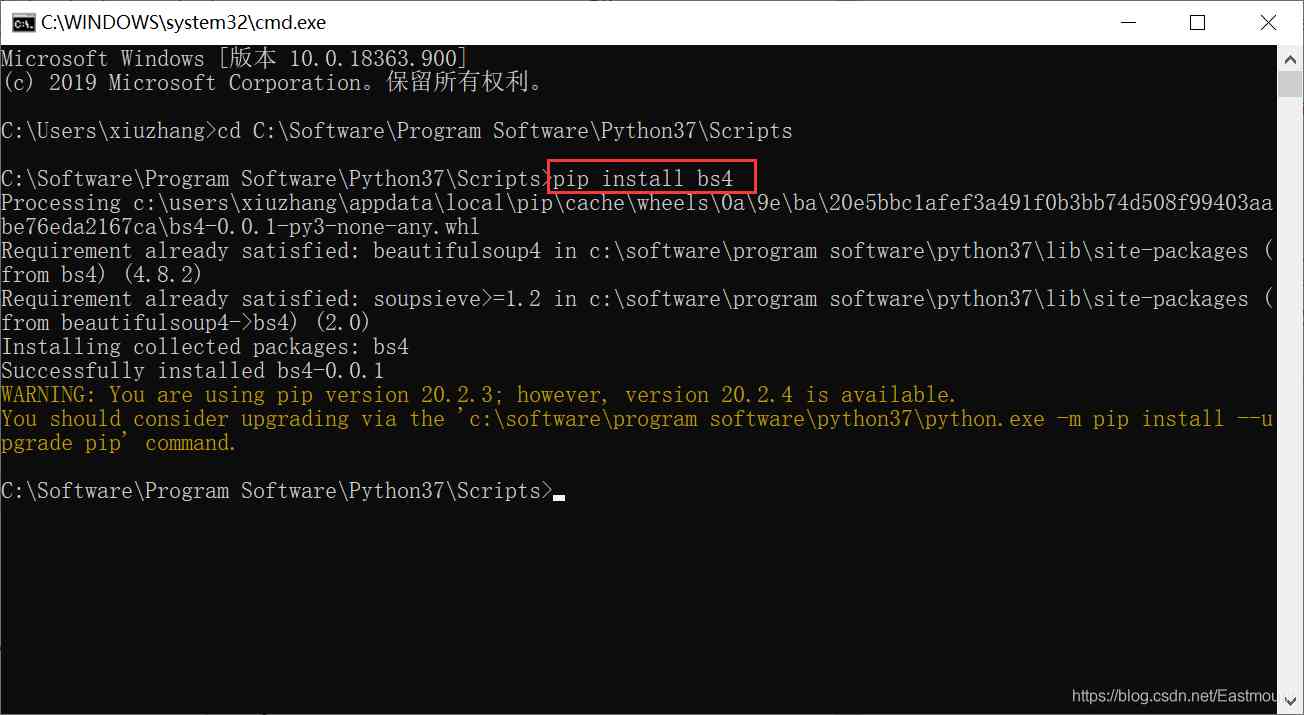
当BeautifulSoup扩展包安装成功后,在Python3.7中输入“from bs4 import BeautifulSoup”语句导入该扩展包,测试安装是否成功,如果没有异常报错即安装成功,如下图所示。
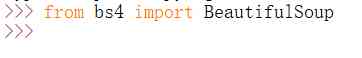
输入代码如下:
- from bs4 import BeautifulSoup
BeautifulSoup有两个常用版本:BeautifulSoup 3和BeautifulSoup 4(简称BS4)。BeautifulSoup 3目前已经停止开发,项目中使用更多的是BeautifulSoup 4,现已移植到BS4扩展包中。建议读者安装BeautifulSoup4,因为BeautifulSoup3已经停止更新;同时如果读者使用的是Anaconda等集成开发环境,它的BeautifulSoup扩展包是已经安装了的,可以直接使用。
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml,另一个可供选择的解析器是纯Python实现的html5lib,html5lib的解析方式与浏览器相同。Windows系统下调用pip或easy_install命令安装lxml,代码如下:
- pip install lxml
- easy_install lxml
下表列出了BeautifulSoup官方文档中主要的解析器和它们的优缺点。
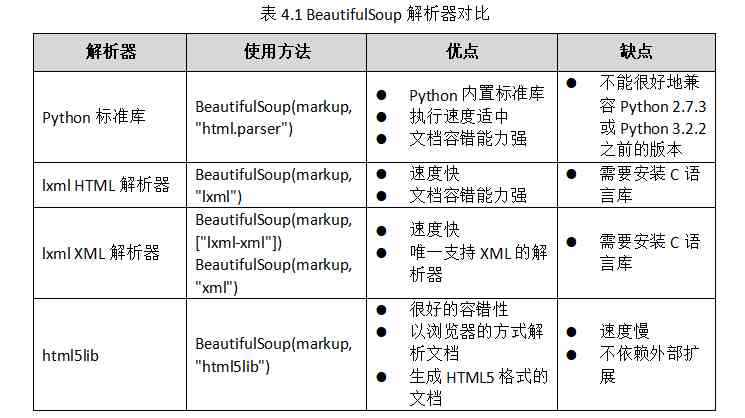
2.pip安装扩展包用法
前面的安装过程调用pip命令,那么它究竟是什么呢?
pip是一个现代的、通用的Python包管理工具,提供了对Python包(Package)的查找、下载、安装及卸载功能。Python可以通过easy_install或者pip命令安装各种各样的包,其中easy_insall提供了“傻瓜式”的在线一键安装模块的方式,而pip是easy_install的改进版,提供更好的提示信息以及下载、卸载Python包等功能,常见用法如下表所示。

在Python2旧版本开发环境中使用pip命令之前,需要安装pip软件(下载pip-Win_1.7.exe软件直接安装),再调用pip命令对具体的扩展包进行安装,目前Python3已经内嵌pip工具供大家直接使用。
- http://pypi.python.org/pypi/pip#downloads
Python2旧版本安装完pip工具后,它会在Python安装目录下添加Scripts目录。在Python2.7中,安装的扩展包会在目录Scripts文件夹下添加相应的文件,甚至需要将此目录(Scripts)加入环境变量中。安装pip成功后,通过命令“pip install bs4”安装BeautifulSoup 4软件。
下表显示了pip常用命令,其中最常用的命令是“install”和“uninstall”。
Usage: 基本用法
pip <command> [options] command表示操作命令,options表示参数
Commands: 操作命令
install 安装软件
uninstall 卸载软件
freeze 按一定格式输出已安装软件列表
list 列出已安装软件
show 显示软件详细信息
search 搜索软件
wheel 根据要求建立wheel扩展包
zip 打包(zip)单个扩展包,不推荐使用
unzip 解压(unzip)单个扩展包,不推荐使用
help 查看帮助提示
General Options: 常用选项
-h, --help 显示帮助
-v, --verbose 更多的输出,最多可以使用3次
-V, --version 显示版本信息然后退出
-q, --quiet 最少的输出
--log-file <path> 以覆盖的方式记录详细的输出日志
--log <path> 以不覆盖的方式记录详细的输出日志.
--proxy <proxy> 指定端口号
--timeout <sec> 设置连接超时时间(默认15秒)
--exists-action <action> 设置存在默认行为,可选参数包括:(s)witch、 (i)gnore、(w)ipe、(b)ackup
--cert <path> 设置证书
最后推荐官方文档:
- https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
- https://pypi.org/project/beautifulsoup4/
二.快速开始BeautifulSoup解析
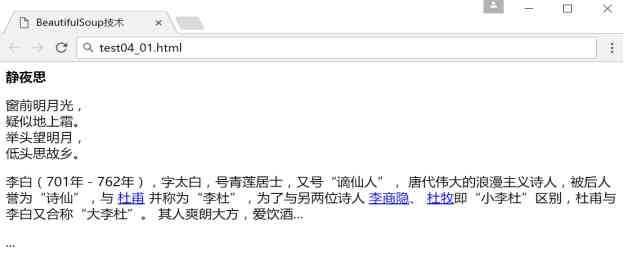
下面这段HTML代码(test04_01.html)是关于李白的一首诗和描述,它将作为例子被多次使用。HTML主要采用节点对的形式进行编写,如< html>< /html>、< body>< /body>、< a>< /a>等。
<html>
<head>
<title>BeautifulSoup技术</title>
</head>
<body>
<p class="title"><b>静夜思</b></p>
<p class="content">
窗前明月光,<br />
疑似地上霜。 <br />
举头望明月,<br />
低头思故乡。 <br />
</p>
<p class="other">
李白(701年-762年),字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
<a href="http://example.com/dufu" class="poet" id="link1">杜甫</a>
并称为“李杜”,为了与另两位诗人
<a href="http://example.com/lishangyin" class="poet" id="link2">李商隐</a>、
<a href="http://example.com/dumu" class="poet" id="link3">杜牧</a>即“小李杜”区别,杜甫与李白又合称“大李杜”。
其人爽朗大方,爱饮酒...</p>
<p class="story">...</p>
通过浏览器打开该网页显示如下图所示。
1.BeautifulSoup解析HTML
下列代码是通过BeautifulSoup解析这段HTML网页,创建一个 BeautifulSoup对象,然后调用BeautifulSoup包的prettify()函数格式化输出网页。
# coding=utf-8
from bs4 import BeautifulSoup
#HTML源码
html = """
<html>
<head>
<title>BeautifulSoup技术</title>
</head>
<body>
<p class="title"><b>静夜思</b></p>
<p class="content">
窗前明月光,<br />
疑似地上霜。 <br />
举头望明月,<br />
低头思故乡。 <br />
</p>
<p class="other">
李白(701年-762年),字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
<a href="http://example.com/dufu" class="poet" id="link1">杜甫</a>
并称为“李杜”,为了与另两位诗人
<a href="http://example.com/lishangyin" class="poet" id="link2">李商隐</a>、
<a href="http://example.com/dumu" class="poet" id="link3">杜牧</a>即“小李杜”区别,杜甫与李白又合称“大李杜”。
其人爽朗大方,爱饮酒...
</p>
<p class="story">...</p>
"""
#按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
代码输出结果如下所示,是网页的HTML源代码。soup.prettify()将soup内容格式化输出,用BeautifulSoup 解析HTML文档时,它会将HTML文档类似DOM文档树一样处理。

注意:前面定义的HTML源码标签对是缺少结束标签的,即没有和标签,但是使用prettify()函数输出的结果已经自动补齐了结束标签,这是BeautifulSoup的一个优点。BeautifulSoup即使得到了一个损坏的标签,它也产生一个转换DOM树,并尽可能和您原文档内容含义一致,这种措施通常能够帮助您更正确地搜集数据。另外,我们还可以用本地HTML文件来创建BeautifulSoup对象,代码如下所示:
- soup = BeautifulSoup(open(‘test04_01.html’))
2.简单获取网页标签信息
当我们已经使用BeautifulSoup解析了网页之后,如果您想获取某个标签之间的信息,怎么实现呢?比如获取标签< title>和< /title>标题内容。下面的test02.py代码就将教大家使用BeautifulSoup技术获取标签信息的用法,更系统的知识将在第三部分介绍。
# coding=utf-8
from bs4 import BeautifulSoup
#创建本地文件soup对象
soup = BeautifulSoup(open('test04_01.html'), "html.parser")
#获取标题
title = soup.title
print('标题:', title)
该段代码获取HTML的标题,输出结果为“< title>BeautifulSoup技术< /title>”。同样,可以获取其他标签,如HTML的头部(head)。
#获取标题
head = soup.head
print('头部:', head)
输出结果为“< head>< title>BeautifulSoup技术< /title>< /head>”。再比如获取网页中的超链接,通过调用“soup.a”代码获取超链接(< a></ a>)。
#获取a标签
ta = soup.a
print('超链接内容:', ta)
输出为“< a class=“poet” href=“http://example.com/dufu” id=“link1”>杜甫< /a>”。其中HTML中包括三个超链接,分别对应杜甫、李商隐、杜牧,而soup.a只返回第一个超链接。那么,如果想获取所有的超链接,怎么写代码实现呢?后面介绍的find_all()函数就可以实现。
最后给出输出第一个段落(< p>)的代码。
#获取p标签
tp = soup.p
print('段落内容:', tp)
输出结果为“< p class=“title”>< b>静夜思< /b>< /p>”,其中unicode()函数用于转码,否则输出中文乱码。上面代码输出内容如下图所示。

3.定位标签并获取内容
前面部分简单介绍了BeautifulSoup标签,可以获取title、p、a等标签内容,但是如何获取这些已经定位了的指定标签对应的内容呢?下面这段代码是获取网页中所有的超链接标签及对应的url内容。
#从文档中找到<a>的所有标签链接
for a in soup.find_all('a'):
print(a)
#获取<a>的超链接
for link in soup.find_all('a'):
print(link.get('href'))
输出结果如下图所示。find_all(‘a’)函数是查找所有< a>标签,并通过for循环输出结果;第二个for循环是通过“link.get(‘href’)”代码获取超链接标签中的url网址。

比如“< a class=“poet” href=“http://example.com/dufu” id=“link1”>杜甫< /a>”,通过调用find_all(‘a’)函数获取所有超链接的HTML源码,再调用get(‘href’)获取超链接的内容,href属性对应的值为:http://example.com/dufu。如果想获取文字内容,则调用get_text()函数。
for a in soup.find_all('a'):
print a.get_text()
输出结果为< a>和< /a>之间的链接内容,即如下所示。
- 杜甫
- 李商隐
- 杜牧
后面文章将详细介绍具体的定位节点方法,结合实际例子进行分析讲解。
三.深入了解BeautifulSoup爬虫
第一部分我们介绍了BeautifulSoup爬虫的安装过程及简介,第二部分我们又快速学习了BeautifulSoup技术,而这部分将深入介绍BeautifulSoup技术的语法及用法。
1.BeautifulSoup对象
BeautifulSoup将复杂的HTML文档转换成一个树形结构,每个节点都是Python对象,BeautifulSoup官方文档将所有的对象归纳为以下四种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
下面我们开始详细介绍。
1.Tag
Tag对象表示XML或HTML文档中的标签,通俗地讲就是HTML中的一个个标签,该对象与HTML或XML原生文档中的标签相同。Tag有很多方法和属性,BeautifulSoup中定义为soup.Tag,其中Tag为HTML中的标签,比如head、title等,其结果返回完整的标签内容,包括标签的属性和内容等。例如:
<title>BeautifulSoup技术</title>
<p class="title"><b>静夜思</b></p>
<a href="http://example.com/lishangyin" class="poet" id="link2">李商隐</a>
上面HTML代码中,title、p、a等都是标签,起始标签(< title>、< p>、< a>)和结束标签(< /title>、< /p>、< /a>)之间加上内容就是Tag。标签获取方法代码如下:

通过BeautifulSoup对象读者可以轻松地获取标签和标签内容,这比我们前一章的正则表达式爬虫方便很多。同时注意,它返回的内容是所有标签中的第一个符合要求的标签,比如“print soup.a”语句返回第一个超链接标签。
下面这行代码是输出该对象的类型,即Tag对象。
print type(soup.html)
# <class 'BeautifulSoup.Tag'>
Tag有很多方法和属性,在遍历文档树和搜索文档树中有详细讲解。现在介绍一下Tag中最重要的属性:name和attrs。
(1)name
name属性用于获取文档树的标签名字,如果想获取head标签的名字,只要使用soup.head.name代码即可,对于内部标签,输出的值便为标签本身的名称。soup对象本身比较特殊,它的name为document,代码如下:

(2)attrs
attrs是属性(attributes)的英文简称,属性是网页标签的重要内容。一个标签(Tag)可能有很多个属性,例如上面的例子:
<a href="http://example.com/dufu" class="poet" id="link1">杜甫</a>
它存在两个属性,一个是class属性,对应的值为“poet”;一个是id属性,对应的值为“link1”。Tag属性操作方法与Python字典相同,获取p标签的所有属性代码如下,得到一个字典类型的值,它获取的是第一个段落p的属性及属性值。
print(soup.p.attrs)
#{u'class': [u'title']}
如果需要单独获取某个属性,使用如下两种方法获取超链接的class属性值。
print(soup.a['class'])
#[u'poet']
print(soup.a.get('class'))
#[u'poet']
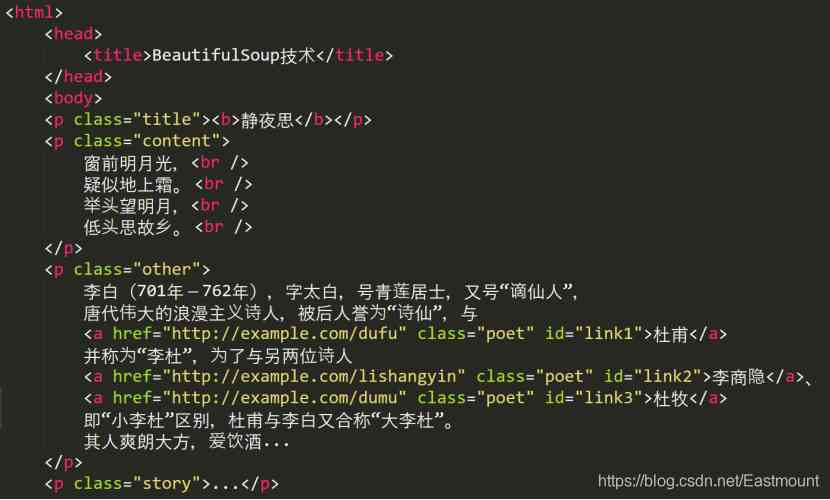
下图为HTML源代码,获取第一个超链接为class=‘poet’。
BeautifulSoup每个标签tag可能有很多个属性,可以通过“.attrs”获取属性,tag的属性可以被修改、删除或添加。下面举个简单的例子进行介绍,完整代码为test03.py文件。
# coding=utf-8
from bs4 import BeautifulSoup
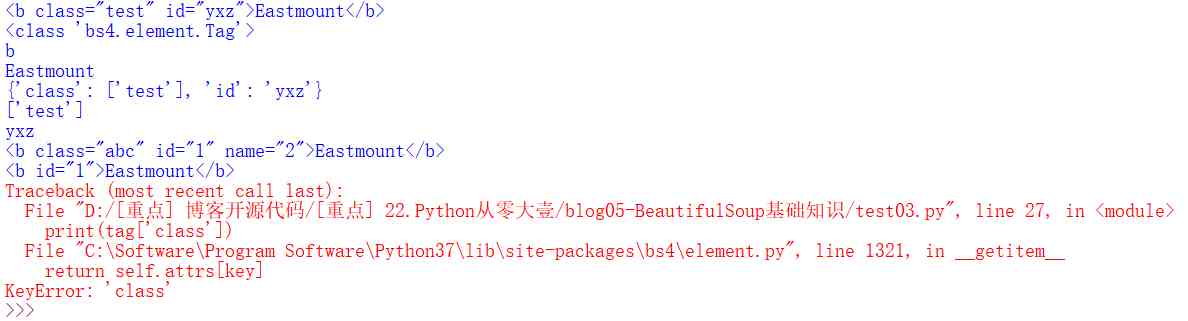
soup = BeautifulSoup('<b class="test" id="yxz">Eastmount</b>',"html.parser")
tag = soup.b
print(tag)
print(type(tag))
#Name
print(tag.name)
print(tag.string)
#Attributes
print(tag.attrs)
print(tag['class'])
print(tag.get('id'))
#修改属性 增加属性name
tag['class'] = 'abc'
tag['id'] = '1'
tag['name'] = '2'
print(tag)
#删除属性
del tag['class']
del tag['name']
print(tag)
print(tag['class'])
#KeyError: 'class'
输出结果如图所示,包括修改属性class、id,增加属性name,删除属性class、name等结果。
注意:HTML定义了一系列可以包含多个值的属性,最常见的可以包含多个值的属性是 class,还有一些属性如rel、rev、accept-charset、headers、accesskey等,BeautifulSoup中多值属性的返回类型是list,具体操作请读者在BeautifulSoup官网进行学习。
2.NavigableString
前面讲述了获取标签的Name和Attributes,那么如果想获取标签对应的内容,怎么实现呢?你可能已经猜到了,使用string属性即可获取标签<>与</>之间的内容。比如:
print(soup.a['class'])
#[u'poet']
print(soup.a['class'].string)
#杜甫
获取“< a href=“http://example.com/dufu” class=“poet” id=“link1”>杜甫< /a>”之间的内容,它是不是比前一篇文章介绍的正则表达式方便很多。
BeautifulSoup用NavigableString类来包装tag中的字符串,NavigableString表示可遍历的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且支持包含在遍历文档树和搜索文档树中的一些特性。利用下述代码可以查看NavigableString的类型。
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('test04_01.html'), "html.parser")
tag = soup.title
print(type(tag.string))
#<class 'BeautifulSoup.NavigableString'>
注意,旧版本Python2需要通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串,再进行相关的操作。如果标签中包含的字符串不能编辑,但是可以被替换成其他的字符串,用replace_with()方法实现。代码如下:
tag.string.replace_with("替换内容")
print(tag)
#<title>替换内容</title>
replace_with()函数将“< title>BeautifulSoup技术< /title>”中的标题内容由“BeautifulSoup技术”替换成了“替换内容”。NavigableString对象支持遍历文档树和搜索文档树中定义的大部分属性,而字符串不能包含其它内容(tag对象却能够包含字符串或是其它tag),字符串不支持“.contents”或“.string ”属性或find()方法。
官方文档提醒:在旧版本Python2中,如果想在BeautifulSoup之外使用NavigableString对象,需要调用unicode()方法,将该对象转换成普通的Unicode字符串,否则就算BeautifulSoup的方法已经执行结束,该对象的输出也会带有对象的引用地址,从而浪费内存。
3.BeautifulSoup
BeautifulSoup对象表示的是一个文档的全部内容,通常情况下把它当作Tag对象,该对象支持遍历文档树和搜索文档树中描述的大部分的方法,详见下一小节。下面代码是输出soup对象的类型,输出结果就是BeautifulSoup对象类型。
print(type(soup))
# <class 'BeautifulSoup.BeautifulSoup'>
注意:因为 BeautifulSoup 对象并不是真正的HTML或XML的标签tag,所以它没有name和attribute属性。但有时查看它的“.name”属性是很方便的,故BeautifulSoup对象包含了一个值为“[document]”的特殊属性“soup.name”。下述代码即是输出BeautifulSoup对象的name属性,其值为“[document]”。
print(soup.name)
# u'[document]'
4.Comment
Comment对象是一个特殊类型的NavigableString对象,它用于处理注释对象。下面这个示例代码用于读取注释内容,代码如下:
markup = "<b><!-- This is a comment code. --></b>"
soup = BeautifulSoup(markup, "html.parser")
comment = soup.b.string
print(type(comment))
# <class 'bs4.element.Comment'>
print(comment)
# This is a comment code.
输出结果如下图所示:

2.遍历文档树
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。在BeautifulSoup中,一个标签(Tag)可能包含多个字符串或其它的标签,这些称为这个标签的子标签,下面从子节点开始介绍。
1.子节点
BeautifulSoup中通过contents值获取标签(Tag)的子节点内容,并以列表形式输出。以test04_01.html代码为例,获取标签子节点内容代码如下:
# coding=utf-8
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('test04_01.html'), "html.parser")
print(soup.head.contents)
#['\n', <title>BeautifulSoup技术</title>, '\n']
由于标题间< title>和< /title>存在两个换行,所以获取的列表包括了两个换行,如个需要提取第二个元素,代码如下:

另一个获取子节点的方法是children关键字,但它返回的不是一个list,可以通过for循环来获取所有子节点内容。方法如下:
print(soup.head.children)
for child in soup.head.children:
print(child)
#<listiterator object at 0x00000000027335F8>
前面介绍的contents和children属性仅包含标签的直接子节点,如果需要获取Tag的所有子节点,甚至是孙节点,则需要使用descendants属性,方法如下:
for child in soup.descendants:
print(child)
输出如下图所示,所有的HTML标签都打印出来。

2.节点内容
如果标签只有一个子节点,需要获取该子节点的内容,则使用string属性,输出子节点的内容,通常返回最里层的标签内容。比如获取标题内容的代码如下:
print(soup.head.string)
# None
print(soup.title.string)
# BeautifulSoup技术
当标签包含多个子节点时,Tag就会无法确定string获取哪个子节点的内容,此时输出的结果就是None,比如获取< head>的内容,返回值就是None,因为包括了两个换行元素。如果需要获取多个节点内容时,则使用strings属性,示例代码如下:
for content in soup.strings:
print(content)
但是输出的字符串可能包含多余的空格或换行,这里需要使用stripped_strings方法去除多余的空白内容,代码如下:
for content in soup.stripped_strings:
print(content)
运行结果如图所示。

3.父节点
调用parent属性定位父节点,如果需要获取节点的标签名则使用parent.name,代码如下所示:
p = soup.p
print(p.parent)
print(p.parent.name)
#<p class="story">...</p></body>
#body
content = soup.head.title.string
print(content.parent)
print(content.parent.name)
#<title>BeautifulSoup技术</title>
#title
如果需要获取所有的父节点,则使用parents属性循环获取,代码如下:
content = soup.head.title.string
for parent in content.parents:
print(parent.name)
4.兄弟节点
兄弟节点是指和本节点位于同一级的节点,其中next_sibling 属性是获取该节点的下一个兄弟节点,previous_sibling 则与之相反,取该节点的上一个兄弟节点,如果节点不存在,则返回None。
- print(soup.p.next_sibling)
- print(soup.p.prev_sibling)
注意:实际文档中的tag的next_sibling 和previous_sibling 属性通常是字符串或空白,因为空白或者换行也可以被视作一个节点,所以得到的结果可能是空白或者换行。同理,通过next_siblings和previous_siblings属性可以获取当前节点的所有兄弟节点,再调用循环迭代输出。
5.前后节点
调用属性next_element可以获取下一个节点,调用属性previous_element可以获取上一个节点,代码举例如下:
- print(soup.p.next_element)
- print(soup.p.previous_element)
同理,通过next_siblings和previous_elements属性可以获取当前节点的所有兄弟节点,并调用循环迭代输出。注意,如果提示错误“TypeError: an integer is required”,则需要增加unicode()函数转换成中文编码输出。
3.搜索文档树
搜索文档树作者主要讲解find_all()方法,这是最常用的一种方法,而更多的方法与遍历文档树类似,包括父节点、子节点、兄弟节点等,推荐读者下来从官网自行学习。如果想从网页中得到所有的标签,使用find_all()方法的代码如下:
urls = soup.find_all('a')
for u in urls:
print(u)
# <a class="poet" href="http://example.com/dufu" id="link1">杜甫</a>
# <a class="poet" href="http://example.com/lishangyin" id="link2">李商隐</a>
# <a class="poet" href="http://example.com/dumu" id="link3">杜牧</a>
输出结果如下图所示:

注意:如果你报错“‘NoneType’ object is not callable using ‘find_all’ in BeautifulSoup”,其原因是需要安装BeautifulSoup4版本或bs4,因为方法find_all()是属于该版本。而BeautifulSoup3使用的方法如下所示:
- from BeautifulSoup import BeautifulSoup
- soup.findAll(‘p’, align=“center”)
同样,该函数支持传入正则表达式作为参数,BeautifulSoup会通过正则表达式的match() 来匹配内容。下面例子中找出所有以b开头的标签示例:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
# br
# br
其输出结果包括字母“b”的标签名,如body、b、br、br等。如果想获取标签a和标签b的值,则使用下面的函数:
- soup.find_all([“a”, “b”])
注意find_all()函数是可以接受参数进行指定节点查询的,代码如下:
soup.find_all(id='link1')
# <a class="poet" href="http://example.com/dufu" id="link1">杜甫</a>
也可以接受多个参数,比如:
soup.find_all("a", class_="poet")
# <a class="poet" href="http://example.com/dufu" id="link1">杜甫</a>
# <a class="poet" href="http://example.com/lishangyin" id="link2">李商隐</a>
# <a class="poet" href="http://example.com/dumu" id="link3">杜牧</a>
讲到这里,BeautifulSoup基础知识及用法已经讲述完毕,接下来通过一个简单示例讲解BeautifulSoup爬取网络数据,这里抓取的是上一篇文章的那个示例,爬取作者个人博客的首页信息。同时,更多BeautifulSoup技术知识推荐大家去其官方网站学习,网址为:
四.BeautifulSoup简单爬取个人博客网站
上一篇文章讲述了正则表达式爬取个人博客网站的简单示例,下面讲解BeautifulSoup技术爬取个人博客网站内容。BeautifulSoup提供了一些方法以及类Python语法来查找一棵转换树,帮助你解析一棵树并定位获取你所需要的内容。作者的个人网站网址为:
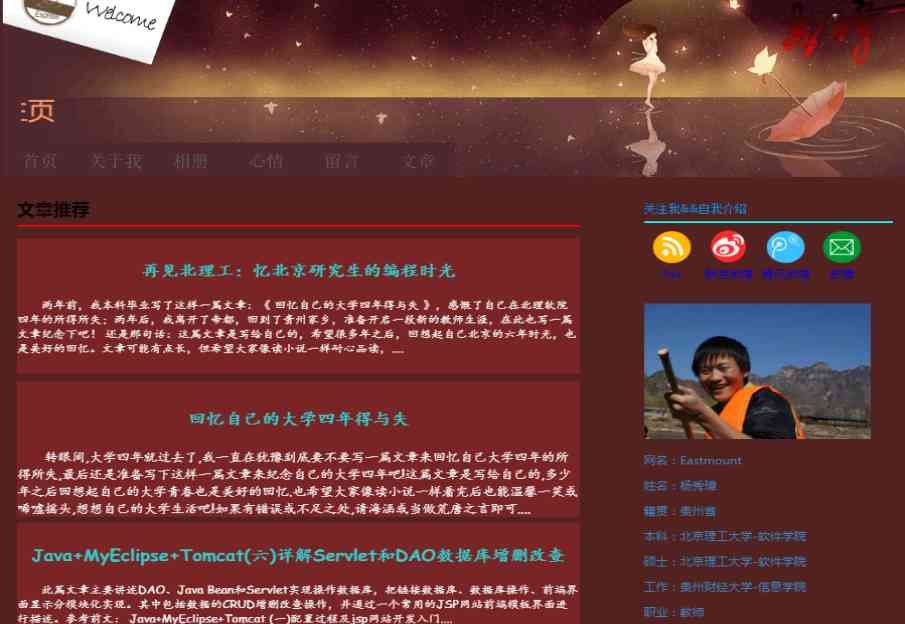
现在需要爬取博客首页中四篇文章的标题、超链接及摘要内容,比如标题为“再见北理工:忆北京研究生的编程时光”。
首先,通过浏览器定位这些元素源代码,发现它们之间的规律,这称为DOM树文档节点树分析,找到所需爬取节点对应的属性和属性值,如图所示。
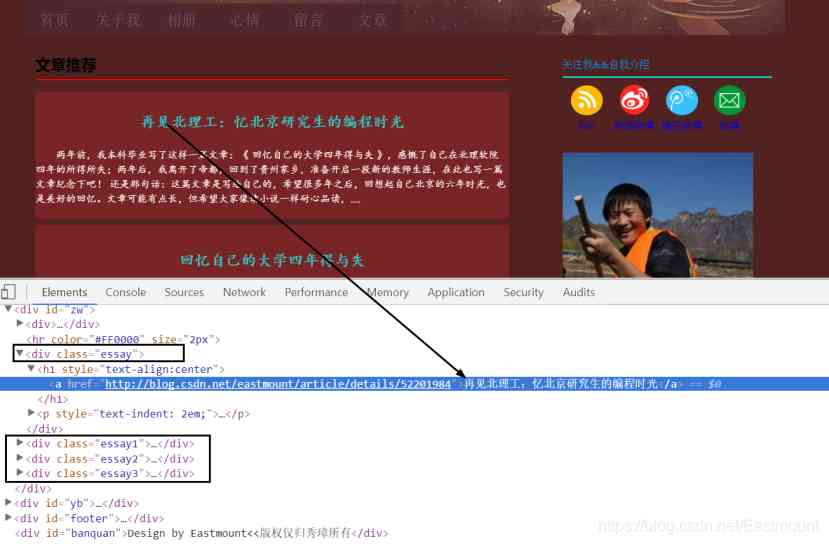
标题位于< div class=”essay”>< /div>位置下,它包括一个< h1>< /h1>记录标题,一个< p>< /p>记录摘要信息,其余三篇文章节点为< div class=”essay1”>< /div>、< div class=”essay2”>< /div>和< div class=”essay3”>< /div>。现在需要获取第一篇文章标题、超链接和摘要的代码如下:
# -*- coding: utf-8 -*-
import re
import urllib.request
from bs4 import BeautifulSoup
url = "http://www.eastmountyxz.com/"
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, "html.parser")
essay0 = soup.find_all(attrs={
"class":"essay"})
for tag in essay0:
print(tag)
print('') #换行
print(tag.a)
print(tag.find("a").get_text())
print(tag.find("a").attrs['href'])
content = tag.find("p").get_text()
print(content.replace(' ',''))
print('')
输出结果如下图所示,其中代码soup.find_all(attrs={“class”:“essay”})用于获取节点< div class=“essay”>的内容,然后采用循环输出,但该class类型只包括了一段内容。接着再定位div中的超链接,通过tag.find(“a”).get_text()获取内容,tag.find(“a”).attrs[‘href’]获取超链接url,最后获取段落摘要。

同理,爬取其余文章的代码如下,通过循环获取essay1、essay2、essay3内容,这些div布局中的格式都一样,包括一个标题和一个摘要信息,代码如下:
#整理输出
i = 1
while i<=3:
num = "essay" + str(i)
essay = soup.find_all(attrs={
"class":num})
for tag in essay:
print(tag.find("a").get_text())
print(tag.find("a").attrs['href'])
content = tag.find("p").get_text()
print(content.replace(' ',''))
i += 1
print('')
输出结果如下:

整个BeautifulSoup爬虫已经讲完了,是不是比前面的正则表达式方便很多,而且爬取的函数也更加智能。后面将结合案例深入讲解BeautifulSoup实际操作,包括爬取电影信息、存储数据库等内容。
五.本章小结
BeautifulSoup是一个可以从HTML或XML文件中提取所需数据的Python库,这里作者把它看作是一种技术。
- 一方面是它具有智能化爬取网页信息的强大功能,对比前面的正则表达式爬虫,您就能体会到它的便捷和适用性,BeautifulSoup通过载入整个网页文档并调用相关函数定位所需信息的节点,再爬取相关内容.
- 另一方面,BeautifulSoup使用起来比较简单,API非常人性化,采用类似于XPath的分析技术定位标签,并且支持CSS选择器,开发效率相对较高,被广泛应用于Python数据爬取领域。所以作者把它看作一种爬虫技术,接下来通过一个完整的爬虫案例加深读者的印象。
该系列所有代码下载地址:
前文赏析:
- [Python从零到壹] 一.为什么我们要学Python及基础语法详解
- [Python从零到壹] 二.语法基础之条件语句、循环语句和函数
- [Python从零到壹] 三.语法基础之文件操作、CSV文件读写及面向对象
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
最后,真诚地感谢您关注“娜璋之家”公众号,感谢CSDN这么多年的陪伴,会一直坚持分享,希望我的文章能陪伴你成长,也希望在技术路上不断前行。文章如果对你有帮助、有感悟,就是对我最好的回报,且看且珍惜!2020年8月18日建立的公众号,再次感谢您的关注,也请帮忙宣传下“娜璋之家”,哈哈~初来乍到,还请多多指教。

感恩女神,感恩思远~

(By:娜璋之家 Eastmount 2020-11-08 夜于贵阳 https://blog.csdn.net/Eastmount )
参考文献如下:
- 作者书籍《Python网络数据爬取及分析从入门到精通》
- 作者博客:https://blog.csdn.net/Eastmount
版权声明
本文为[osc_1b9czlr5]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4347242/blog/4708497
边栏推荐
猜你喜欢
程序员都应该知道的URI,一文帮你全面了解

Database design: paradigms and anti paradigms
OSChina 周一乱弹 —— 程序媛的青春
基于LabVIEW实现的几种滚动字幕
C++邻接矩阵
Common feature pyramid network FPN and its variants
STS安装
非阻塞的无界线程安全队列 —— ConcurrentLinkedQueue
A solution to the problem that color picker (palette) cannot use shortcut keys in sublime Text3 plug-in
Windows环境下如何进行线程Dump分析
随机推荐
leetcode之反转字符串中的元音字母
服务器性能监控神器nmon使用介绍
LeetCode-11:盛水最多的容器
On buffer overflow
python生日贺卡制作以及细节问题的解决最后把python项目发布为exe可执行程序过程
使用递增计数器的线程同步工具 —— 信号量,它的原理是什么样子的?
Android emulator error: x86 emulation currently requires hardware acceleration的解决方案
API部分的知识点复习
写时复制集合 —— CopyOnWriteArrayList
Copy on write collection -- copyonwritearraylist
App crashed inexplicably. At first, it thought it was the case of the name in the header. Finally, it was found that it was the fault of the container!
Leetcode-11: container with the most water
The vowels in the inverted string of leetcode
SaaS: another manifestation of platform commercialization capability
LeetCode-15:三数之和
Huawei HCIA notes
VIM Introduction Manual, (vs Code)
AQS 都看完了,Condition 原理可不能少!
程序员都应该知道的URI,一文帮你全面了解
Chapter 5 programming