当前位置:网站首页>自然语言处理(NLP)路线图 - kdnuggets
自然语言处理(NLP)路线图 - kdnuggets
2020-11-09 00:40:00 【解道jdon】
由于 近十年来大数据的发展 。企业现在每天都需要分析来自各种来源的大量数据。
自然语言处理(NLP)是人工智能领域的研究领域,致力于处理和使用文本和语音数据来创建智能机器并创建见解。
预处理技术
为了准备用于推理的文本数据,一些最常用的技术是:
- 标记化: 用于将输入文本分割成其组成词(标记)。这样,将我们的数据转换为数字格式变得更加容易。
- 停用词移除: 用于从我们的文本中移除所有介词(例如,“一个”,“这个”等),这些介词只能被视为我们数据中的噪声源(因为它们不带有其他附加词)我们数据中的信息性信息)。
- 词干: 最终用于去除数据中的所有词缀(例如前缀或后缀)。这样,实际上,对于我们的算法而言,将其视为实际上具有相似含义(例如,有见识的见解)的专有单词会变得容易得多。
使用标准的Python NLP库(例如NLTK 和 Spacy),所有这些预处理技术都可以轻松地应用于不同类型的文本 。
另外,为了推断语言的语法和文本结构,我们可以利用诸如词性(POS)标记和浅解析(图1)之类的技术。实际上,使用这些技术,我们可以使用单词的词法类别(基于短语语法上下文)显式标记每个单词。
建模技术
- 言语包
Bag of Words是一种用于自然语言处理和 计算机视觉的技术 ,目的是为训练分类器创建新功能(图2)。通过构建对文档中所有单词进行计数的直方图来实现此技术(不考虑单词顺序和语法规则)。
可能会限制这项技术功效的主要问题之一是在我们的课文中出现介词,代词,冠词等。实际上,这些全都可以被认为是在我们的文本中经常出现的单词,即使不一定真正了解我们文档的主要特征和主题是什么。
为了解决这种类型的问题,通常使用称为“术语频率-反文档频率”(TFIDF)的技术。TFIDF旨在通过考虑文本中每个单词在大量文本中整体出现的频率来重新调整文本中单词计数的频率。然后,使用这种技术,我们将奖励在文本中非常普遍出现但在其他文本中很少出现的单词(按比例增加频率值),同时对在文本和其他文本中频繁出现的单词(按比例缩小频率值)进行惩罚(例如介词,代词等)。
- 潜在狄利克雷分配(LDA)
潜在狄利克雷分配(LDA)是一种主题建模技术。主题建模是一个研究领域,致力于发现对文档进行聚类的方法,以便发现可以根据其内容表征其特征的潜在区分标记(图3)。因此,主题建模也可以被视为 降维技术,因为它允许我们将初始数据缩减为一组有限的簇。
潜在狄利克雷分配(LDA)是一种无监督的学习技术,用于找出可以表征不同文档并将相似文档聚类在一起的潜在主题。该算法将 被认为存在的N个主题作为输入 ,然后将不同文档分组为 N 个彼此密切相关的文档簇。
LDA与其他聚类技术(例如K均值聚类)的不同之处在于LDA是一种软聚类技术(每个文档都基于概率分布分配给聚类)。例如,可以将文档分配给群集A,因为算法确定该文档属于此类的可能性为80%,同时仍考虑到嵌入到此文档中的某些特征(其余20%)更多可能属于第二个群集B。
- 词嵌入
词嵌入是将词编码为数字向量的最常见方法之一,然后可以将其输入到我们的机器学习模型中进行推理。词嵌入旨在将我们的词可靠地转换为向量空间,以便相似的词由相似的向量表示。
如今,有为了用来创建的Word曲面嵌入三种主要的技术:Word2Vec,手套和fastText。所有这三种技术都使用浅层神经网络来创建所需的单词嵌入。
- 情绪分析
情感分析是一种NLP技术,通常用于了解某种形式的文本表达的是关于主题的正面,负面还是中立的情绪。例如,在尝试找出有关某个主题,产品或公司的一般公众意见(通过在线评论,推文等)时,这可能特别有用。
在情感分析中,文本中的情感通常表示为-1(负情感)和1(正情感)之间的值,称为极性。
情感分析可以被认为是一种无监督学习技术,因为我们通常不为数据提供手工制作的标签。为了克服这一障碍,我们使用了预先标记的词典(一本单词集),该词典用来量化不同上下文中大量单词的情感。情感分析广泛使用的词汇的一些例子是 TextBlob 和 VADER。
- Transformer
代表了最新的NLP模型,以便分析文本数据。BERT 和 GTP3是一些众所周知的Transformers模型的 示例。
在创建Transformer之前,递归神经网络(RNN)是顺序分析文本数据以进行预测的最有效方法,但是这种方法很难可靠地利用长期依赖关系,例如,我们的网络可能会难以理解前几次迭代中输入的单词可能对当前迭代有用。
借助一种称为“注意力” (Attention)的机制,成功地克服了这一限制(该机制 用于确定文本的哪些部分需要重点关注并给予更大的重视)。此外,Transformers使并行处理文本数据变得容易,而不是顺序处理(因此提高了执行速度)。
如今,借助Hugging Face库,可以轻松地在Python中实现Transfer 。
版权声明
本文为[解道jdon]所创,转载请带上原文链接,感谢
https://www.jdon.com/55276
边栏推荐
- 如何让脚本同时兼容Python2和Python3?
- Five phases of API life cycle
- Octave基本语法
- Linked list
- FC 游戏机的工作原理是怎样的?
- 云计算之路-出海记-小目标:Hello World from .NET 5.0 on AWS
- C/C++编程笔记:指针篇!从内存理解指针,让你完全搞懂指针
- centos7下安装iperf时出现 make: *** No targets specified and no makefile found. Stop.的解决方案
- Linked blocking queue based on linked list
- 华为HCIA笔记
猜你喜欢

C + + adjacency matrix
How to deploy pytorch lightning model to production
Share API on the web
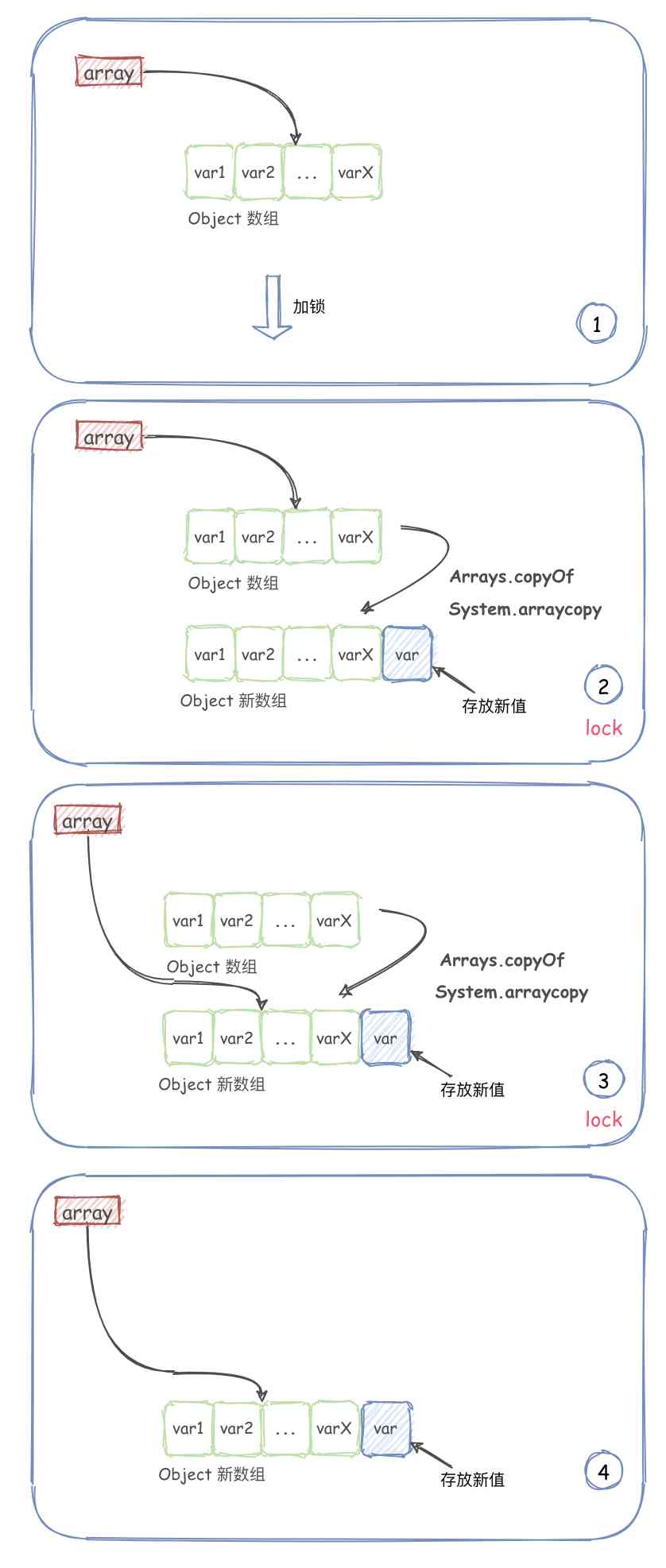
Copy on write collection -- copyonwritearraylist
14. Introduction to kubenetes
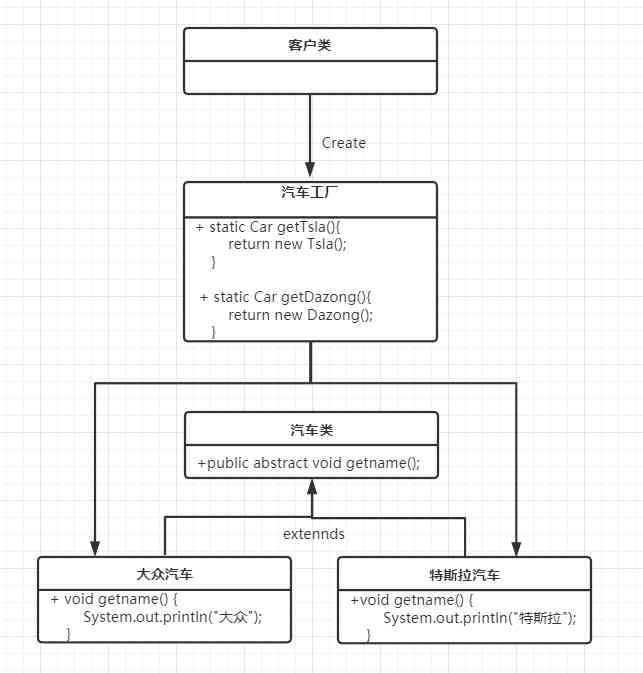
Factory pattern pattern pattern (simple factory, factory method, abstract factory pattern)
Python的特性与搭建环境
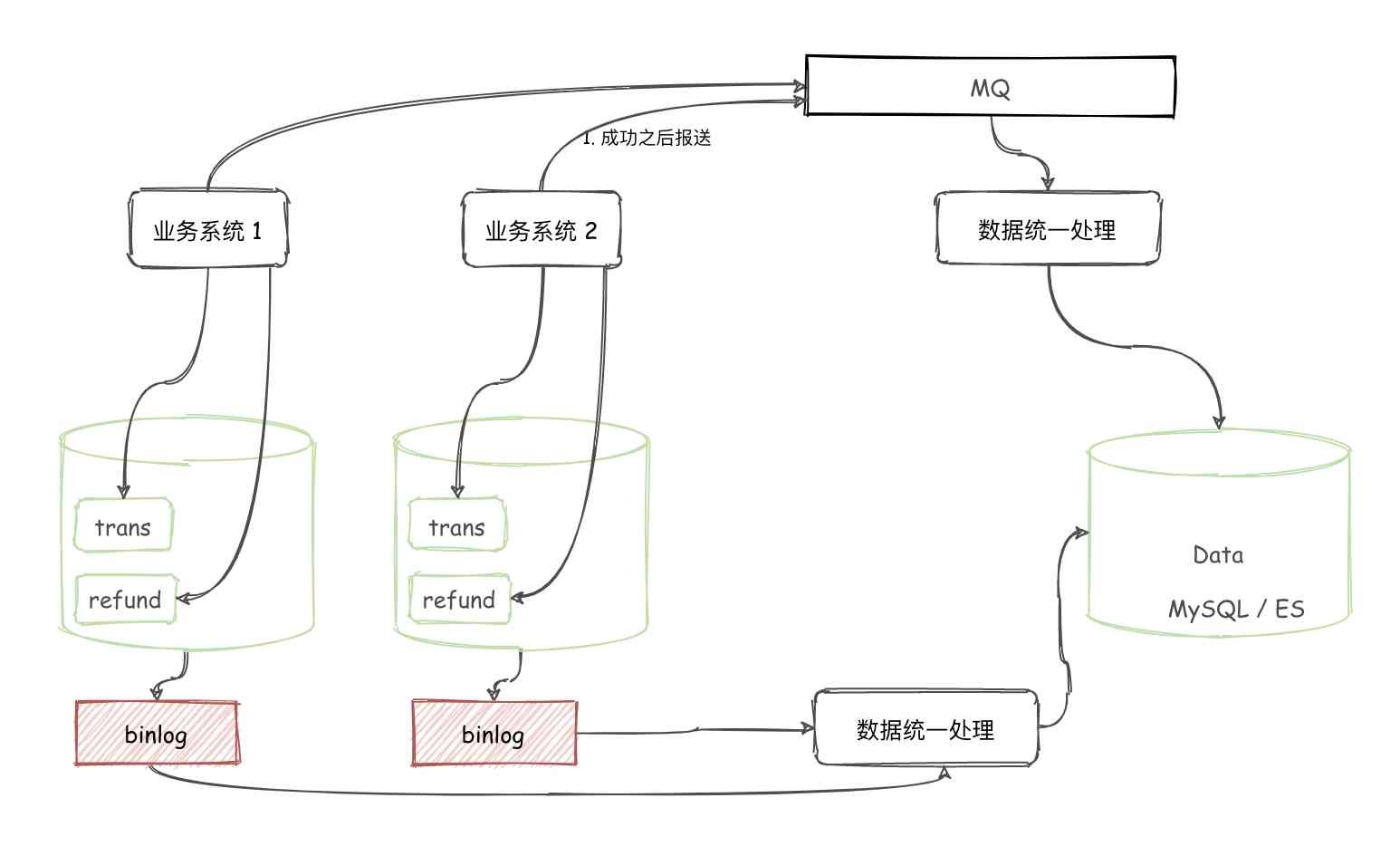
Have you ever thought about why the transaction and refund have to be split into different tables
How does semaphore, a thread synchronization tool that uses an up counter, look like?
Execution of SQL statement
随机推荐
Teacher Liang's small class
First development of STC to stm32
代码保存
How to make scripts compatible with both Python 2 and python 3?
Core knowledge of C + + 11-17 template (2) -- class template
How does semaphore, a thread synchronization tool that uses an up counter, look like?
教你如何 分析 Android ANR 问题
The road of cloud computing - going to sea - small goal: Hello world from. Net 5.0 on AWS
程序员都应该知道的URI,一文帮你全面了解
实现图片的复制
上线1周,B.Protocal已有7000ETH资产!
Using containers to store table data
Windows环境下如何进行线程Dump分析
AQS 都看完了,Condition 原理可不能少!
分库分表的几种常见玩法及如何解决跨库查询等问题
Factory pattern pattern pattern (simple factory, factory method, abstract factory pattern)
C++邻接矩阵
小议缓冲区溢出
23张图,带你入门推荐系统
Computer network application layer