当前位置:网站首页>【CVPR 2019】Semantic Image Synthesis with Spatially-Adaptive Normalization(SPADE)
【CVPR 2019】Semantic Image Synthesis with Spatially-Adaptive Normalization(SPADE)
2022-06-26 09:24:00 【_ Summer tree】
List of articles

# Spatial adaptive regularization
We propose spatially-adaptive normalization, a simplebut effective layer for synthesizing photorealistic images given an input semantic layout. we propose usingthe input layout for modulating the activations in normal-ization layers through a spatially-adaptive, learned trans-formation.
Experiments on several challenging datasetsdemonstrate the advantage of the proposed method over ex-isting approaches, regarding both visual fidelity and align-ment with input layouts. Finally, our model allows usercontrol over both semantic and style.
Introduction
In this paper, we show that the conventional net-work architecture [22, 48], which is built by stacking con-volutional, normalization, and nonlinearity layers, is at best suboptimal because their normalization layers tend to “washaway” information contained in the input semantic masks. // In this paper , We proved the traditional network architecture [22,48], It's made up of convolution layers 、 The normalized layer and the nonlinear layer are superimposed , In the best case, it is suboptimal , Because their normalized layers tend to “ Eliminate ” Information contained in the input semantic mask .
To address the issue, we proposespatially-adaptive normal-ization, a conditional normalization layer that modulates theactivations using input semantic layouts through a spatially-adaptive, learned transformation and can effectively propa-gate the semantic information throughout the network. // To solve this problem , We propose a spatial adaptive standardization , It is a conditional normalization layer , The activation of input semantic layout is adjusted through spatial adaptive learning transformation , And it can effectively spread semantic information throughout the network .
This passage is like abstract.

Figure 1: Our model allows user control over both semantic and style as synthesizing an image. The semantic (e.g., theexistence of a tree) is controlled via a label map (the top row), while the style is controlled via the reference style image (theleftmost column). Please visit our website for interactive image synthesis demos. // chart 1: Our model allows users to control the semantics and style of synthetic images . semantics ( for example , The existence of trees ) Is mapped by tags ( The top row ) Controlled , And the style is by referring to the style image ( The leftmost column ) Controlled . Please visit our website for interactive image synthesis demonstration .
our goal is to design a generator forstyle and semantics disentanglement. We focus on provid-ing the semantic information in the context of modulatingnormalized activations. We use semantic maps in differentscales, which enables coarse-to-fine generation. The readeris encouraged to review their work for more details. // Our goal is to design a generator for style and semantic decomposition . We focus on providing semantic information in the context of regulating canonical activation . We use semantic mapping at different scales , This makes coarse to fine generation possible . Readers are encouraged to review their work for more details .
3. Semantic Image Synthesis
Our goal is to learn a mapping function , It can split an input mask Convert to realistic images
Spatially-adaptive denormalization.
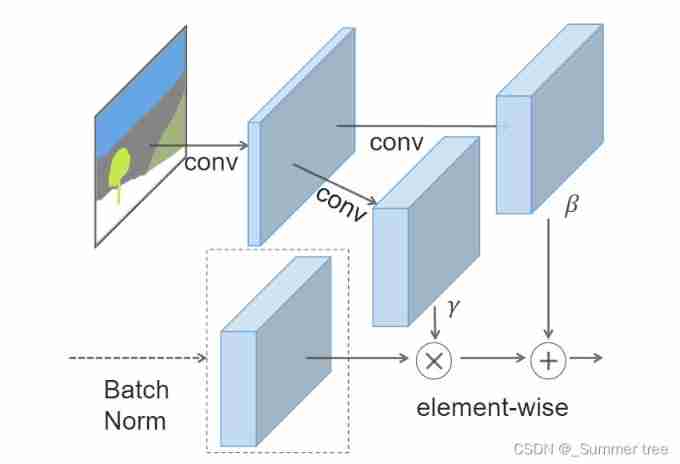
Figure 2: In the SPADE, the mask is first projected onto anembedding space and then convolved to produce the modu-lation parametersγandβ. Unlike prior conditional normal-ization methods,γandβare not vectors, but tensors withspatial dimensions. The producedγandβare multipliedand added to the normalized activation element-wise // chart 2: stay SPADE in , The mask is first projected into the embedding space , Then convolution generates modulation parameters γ and β. Different from the prior conditional normalization method ,γ and β It's not a vector , It's a tensor with a spatial dimension . The generated γ and β Multiply and add to the normalized active elements .
The activation value at site(n∈N,c∈Ci,y∈Hi,x∈Wi)is

\gamma and \beta are thelearned modulation parameters of the normalization layer/
In contrast to the BatchNorm [21], they depend on the in-put segmentation mask and vary with respect to the location(y,x).


Figure 3: Comparing results given uniform segmentationmaps: while the SPADE generator produces plausible tex-tures, the pix2pixHD generator [48] produces two identicaloutputs due to the loss of the semantic information after thenormalization layer.
SPADE generator.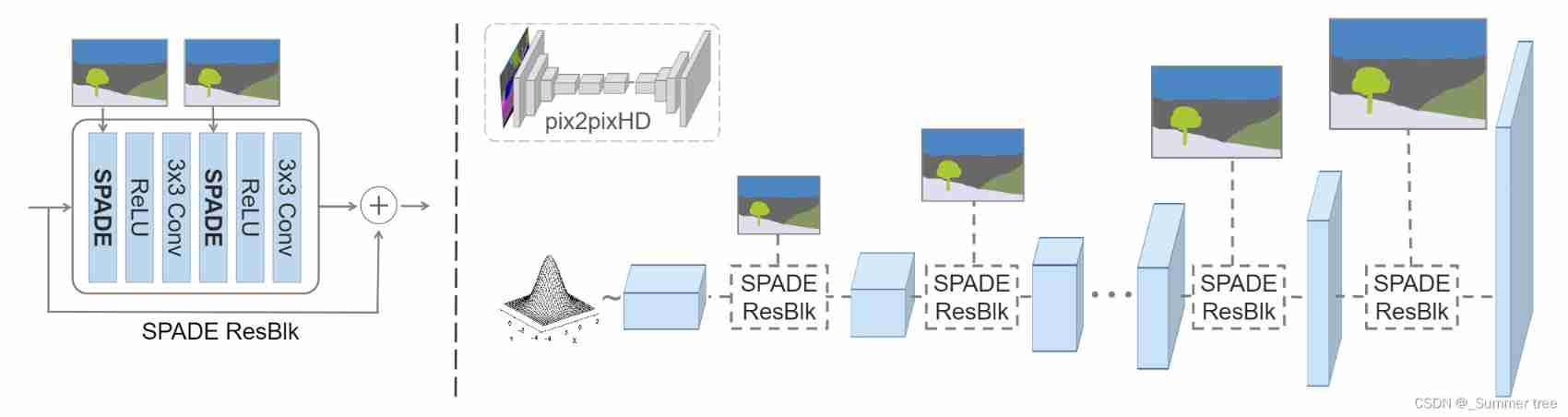
Figure 4: In the SPADE generator, each normalization layer uses the segmentation mask to modulate the layer activations.(left)Structure of one residual block with the SPADE.(right)The generator contains a series of the SPADE residual blockswith upsampling layers. Our architecture achieves better performance with a smaller number of parameters by removing thedownsampling layers of leading image-to-image translation networks such as the pix2pixHD model [48].
conclusion
We propose spatial adaptive normalization , Layout with input semantics , Affine transformation is performed in the normalization layer . The proposed normalization leads to the first semantic image synthesis model , The model can be generated including indoor 、 Outside 、 Realistic output of various scenes including landscape and street scenes . We further demonstrate its application in multimodal synthesis and guided image synthesis .
边栏推荐
- Phpcms applet plug-in version 4.0 was officially launched
- Execution process at runtime
- 【Sensors 2021】Relation-Based Deep Attention Network with Hybrid Memory for One-Shot Person Re-Id
- Catalogue gradué de revues scientifiques et technologiques de haute qualité dans le domaine de l'informatique
- Thinkphp5 manual error reporting
- kubernetes集群部署(v1.23.5)
- Jetson TX2 installing the SciPy Library
- The first techo day Tencent technology open day, 628
- "One week's solution to analog electricity" - power circuit
- Bbox format conversion (detectron2 function library)
猜你喜欢

《單片機原理及應用》——概述

The most complete and simple nanny tutorial: deep learning environment configuration anaconda+pychart+cuda+cudnn+tensorflow+pytorch

板端电源硬件调试BUG
Cancellation and unbinding of qiniu cloud account

Phpcms applet plug-in version 4.0 was officially launched

Router bridging settings

There is a strong demand for enterprise level data integration services. How to find a breakthrough for optimization?

Super data processing operator helps you finish data processing quickly

《一周搞定模电》—集成运算放大器

Bbox format conversion (detectron2 function library)
随机推荐
Self taught neural network series - 9 convolutional neural network CNN
"One week's work on digital power" -- encoder and decoder
Self taught programming series - 2 file path and text reading and writing
Statistics of various target quantities of annotations (XML annotation format)
Self taught machine learning series - 1 basic framework of machine learning
正则表达的学习
集合对象复制
PHP does not allow images to be uploaded together with data (no longer uploading images before uploading data)
行为树的基本概念及进阶
全面解读!Golang中泛型的使用
《一周搞定模电》-光耦等元器件
Cancellation and unbinding of qiniu cloud account
Application of hidden list menu and window transformation in selenium
Pycharm occasionally encounters low disk space
编辑类型信息
Unity WebGL发布无法运行问题
Nacos注册表结构和海量服务注册与并发读写原理 源码分析
51 single chip microcomputer ROM and ram
Regular expression
Phpcms V9 remove the phpsso module