当前位置:网站首页>There is a strong demand for enterprise level data integration services. How to find a breakthrough for optimization?
There is a strong demand for enterprise level data integration services. How to find a breakthrough for optimization?
2022-06-26 09:19:00 【Merrill Lynch data tempodata】
Data Lake 、 Data warehouse 、 The lake and the warehouse are integrated 、 Data center …… People who pay attention to big data , In the near future, these keywords must often brush the screen , This undoubtedly reflects the present Enterprise data integration services There's a lot of demand .
Small T The observed , With the continuous expansion of their business, many enterprises , The amount and type of data required by the daily operation of each department also increases , At the same time, it will continue to produce data , In the face of massive data that is constantly updated , If the enterprise data development team does not do a good job in unified coordination and management , Then everyone under big data will feel like a blind man touching an elephant , Each sees only a part of big data, not a whole , As a result, the coordination efficiency between departments is getting lower and lower .
therefore , In the planning of the overall digital transformation of the enterprise , Data integration The necessity is self-evident . Data integration just as the name suggests , It refers to the process of re centralizing the data in various business data systems that are originally scattered in the enterprise , It serves as the basis for various data projects , It is to connect the user's original data and data governance 、 Key steps of data analysis , It is also a link that is prone to problems in the implementation of traditional data mining analysis projects .
From the perspective of improving the overall data analysis project implementation and development efficiency and development quality , How can we find a breakthrough to optimize the data integration process ?
Data synchronization efficiency , Key factors affecting the quality of data integration
Data integration requirements for most enterprises , Data integration can be basically divided into two categories: offline data synchronization and real-time data synchronization .
One of the most common is offline data synchronization , The application scenario can be simply summarized as : One data source corresponds to one data destination . The data destination can be a data warehouse , Synchronize the data of the relational database into the data warehouse , It forms a data integration .
and Real time data synchronization The data changes of the source database tables can be synchronized to the target database in real time , Realize real-time data correspondence between the target database and the source database .
But no matter which type of data integration , In the traditional data integration process realized by coding , As long as the amount of data reaches a certain level , The problem of low data synchronization efficiency will appear . This is because in the enterprise data mining analysis project , Data often exists in the independent data system of each department , These small systems are disconnected from each other and form “ data silos ” , When it is necessary to transfer data, it is also necessary to transfer technicians separately according to specific needs , Not only the processing cost is high , Long processing time , The data computing pressure brought by massive data often causes problems in the data migration process , Impact on the overall data quality of the project .
Aiming at the low efficiency of data synchronization , stay Tempo DF in , We go through 3 Three aspects of functional design to help enterprises optimize data synchronization :
Speed
High performance computing engine ensures efficient migration of massive data
During the implementation of enterprise level massive data integration and migration requirements , The most important issue is the fast and stable data migration .
In terms of data migration speed ,TempoDF The product has been verified in the cluster environment MySQL to Hive The migration speed can reach 190000 strip /s、 Unstructured files FTP to HDFS Migration reachable 150~160M/s. At this stage, all the projects that have been implemented have realized the stable operation of the process , It can fully meet the requirements of enterprise data warehouse 、 Data migration requirements of the data Lake project .
Simple and convenient
Unified arrangement 、 Dispatch 、 Control processes to reduce operation and maintenance costs
To improve the efficiency of data synchronization , In addition to improving the speed of data migration , We can also accelerate project completion time by simplifying and merging related work tasks .
Tempo DF Job scheduling capability and scheduling in 、 Operation and maintenance functions , All migration tasks can be conveniently and centrally carried out , The granularity can be detailed to every structure / The migration of unstructured data is set according to the actual needs .
At the same time, it supports application process publishing and management , It is convenient for the administrator to maximize the process execution efficiency according to the actual situation . When a synchronization task has a problem , Only relevant business data processes are terminated , Other migration tasks are running normally . After the problem is corrected, it can be supplemented again . Make data migration more relevant to the actual business .
intelligence
Easily configure data migration tasks
Because the data integration work often involves the data of multiple business systems , In the traditional processing flow , The coding workload involved is often very large . and Tempo DF Designer tools in , The complex data migration development process can be simplified into a drag and drop operation , Low code intelligent operation helps technicians save working time , Improve work efficiency .
adopt TempoDF With the help of , When data development engineers handle data table migration tasks , No additional coding work is required , Just configure the data source in the designer 、 Data target , And quickly confirm the data type mapping between the two heterogeneous libraries , You can easily complete the task . At the same time, data processing during migration can be configured 、 Resource parameters 、 Flow parameters and dirty data contents . Implement structured 、 Full migration of unstructured data 、 The incremental migration .
Traditional enterprise digital upgrading and transformation process , Often confined to a single business , It ignores the related data of multiple businesses within the enterprise , Lack of deep understanding of data , As a result, the enterprise has obviously invested a lot of costs , But it is difficult to give full play to the valuable value of data assets .
So in the era of digital economy , If enterprises want to truly realize digital transformation , We must pay attention to the implementation of data integration , By connecting global data , Build a standard data asset system after purification and processing , Meet the growing demand of enterprise business for data .
Merrill Lynch data Tempo DF The platform is such a solution that can provide mature massive data integration , Products that complete the first step of massive data analysis and decision-making . From then on, the development and implementation personnel do not have to worry about the underlying data interruption exception every day , Quickly realize the efficient flow of massive data , Directly improve project delivery efficiency 、 Solve the problem of enterprise massive data integration , Lay a solid foundation for users' subsequent data analysis .
If you want to experience a more efficient and convenient data integration implementation , Welcome to Merrill Lynch data products website Apply for probation ~
边栏推荐
- [qnx hypervisor 2.2 user manual]12.1 terminology (I)
- Principe et application du micro - ordinateur à puce unique - Aperçu
- Detectron2 draw confusion matrix, PR curve and confidence curve
- 报错ImportError: numpy.core.multiarray failed to import
- 3大问题!Redis缓存异常及处理方案总结
- Principle and application of single chip microcomputer -- Overview
- Unity 接入图灵机器人
- Behavior tree file description
- 《一周搞定数电》——编码器和译码器
- thinkphp5手动报错
猜你喜欢

Notes on setting qccheckbox style

Pycharm occasionally encounters low disk space
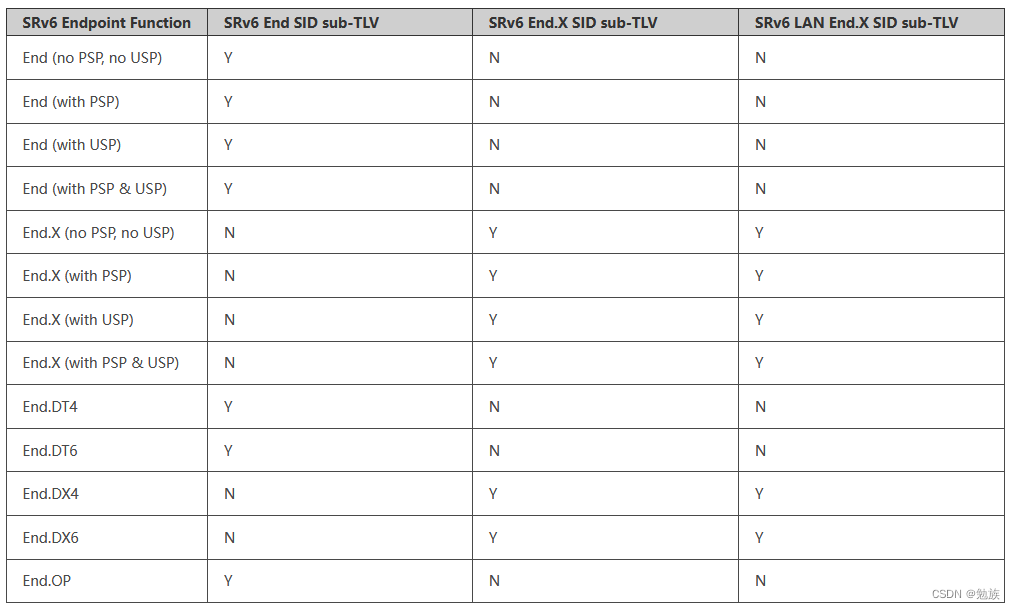
Srv6---is-is extension

How to convert wechat applet into Baidu applet
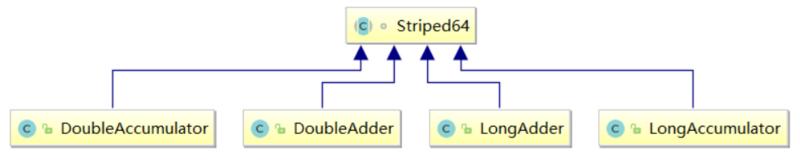
What is optimistic lock and what is pessimistic lock
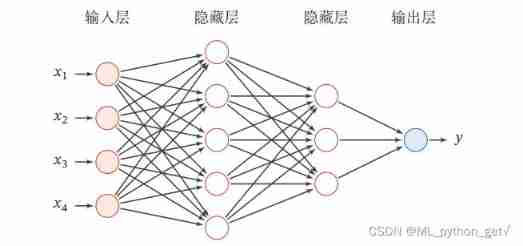
Self learning neural network series - 8 feedforward neural networks

《單片機原理及應用》——概述

Phpcms applet plug-in version 4.0 was officially launched

Nacos注册表结构和海量服务注册与并发读写原理 源码分析

Basic concept and advanced level of behavior tree
随机推荐
简析ROS计算图级
PD fast magnetization mobile power supply scheme
Phpcms V9 mobile phone access computer station one-to-one jump to the corresponding mobile phone station page plug-in
phpcms v9后台文章列表增加一键推送到百度功能
《一周搞定数电》——编码器和译码器
xsync同步脚本的创建及使用(以Debian10集群为例)
教程1:Hello Behaviac
"One week's work on Analog Electronics" - diodes
行为树 文件说明
Practice is the fastest way to become a network engineer
Particles and sound effect system in games104 music 12 game engine
Practice of production control | dilemma on assembly rack
Phpcms V9 adds the reading amount field in the background, and the reading amount can be modified at will
Param in the paper
《一周搞定数电》-逻辑门
MySQL cannot be found in the service (not uninstalled)
Self learning neural network series - 7 feedforward neural network pre knowledge
[IVI] 15.1.2 system stability optimization (lmkd Ⅱ) psi pressure stall information
Understanding of swing transformer
Real time data analysis tool