当前位置:网站首页>RepOptimizer: 其实是RepVGG2
RepOptimizer: 其实是RepVGG2
2022-06-25 21:59:00 【Tom Hardy】
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达

作者丨zzk
来源丨GiantPandaCV
前言
在神经网络结构设计中,我们经常会引入一些先验知识,比如ResNet的残差结构。然而我们还是用常规的优化器去训练网络。
在本工作中,我们提出将先验信息用于修改梯度数值,称为梯度重参数化,对应的优化器称为RepOptimizer。我们着重关注VGG式的直筒模型,训练得到RepOptVGG模型,他有着高训练效率,简单直接的结构和极快的推理速度。
官方仓库:RepOptimizer
论文链接:Re-parameterizing Your Optimizers rather than Architectures
与RepVGG的区别
RepVGG加入了结构先验(如1x1,identity分支),并使用常规优化器训练。而RepOptVGG则是将这种先验知识加入到优化器实现中
尽管RepVGG在推理阶段可以把各分支融合,成为一个直筒模型。但是其训练过程中有着多条分支,需要更多显存和训练时间。而RepOptVGG可是 真-直筒模型,从训练过程中就是一个VGG结构
我们通过定制优化器,实现了结构重参数化和梯度重参数化的等价变换,这种变换是通用的,可以拓展到更多模型
 将结构先验知识引入优化器
将结构先验知识引入优化器 我们注意到一个现象,在特殊情况下,每个分支包含一个线性可训练参数,加一个常量缩放值,只要该缩放值设置合理,则模型性能依旧会很高。我们将这个网络块称为Constant-Scale Linear Addition(CSLA)
我们先从一个简单的CSLA示例入手,考虑一个输入,经过2个卷积分支+线性缩放,并加到一个输出中:

我们考虑等价变换到一个分支内,那等价变换对应2个规则:
初始化规则
融合的权重需为:
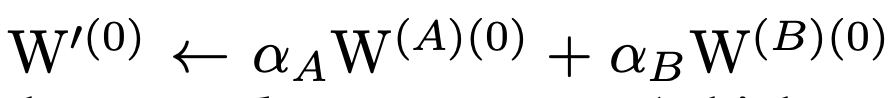
更新规则
针对融合后的权重,其更新规则为: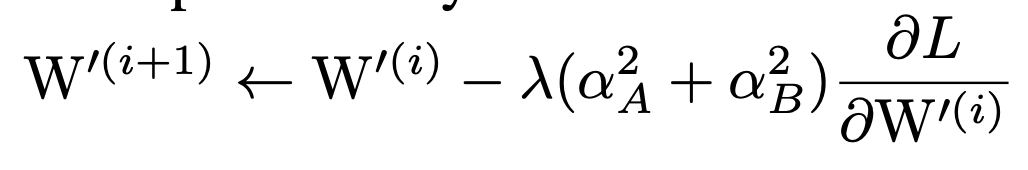 这部分公式可以参考附录A中,里面有详细的推导
这部分公式可以参考附录A中,里面有详细的推导
一个简单的示例代码为:
import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
conv1 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv2 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv1.weight.data = torch.nn.Parameter(torch.tensor(np_w1))
conv2.weight.data = torch.nn.Parameter(torch.tensor(np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = alpha1 * conv1(torch_x) + alpha2 * conv2(torch_x)
loss = out.sum()
loss.backward()
torch_w1_updated = conv1.weight.detach().numpy() - conv1.weight.grad.numpy() * lr
torch_w2_updated = conv2.weight.detach().numpy() - conv2.weight.grad.numpy() * lr
print(torch_w1_updated + torch_w2_updated)import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
fused_conv = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
fused_conv.weight.data = torch.nn.Parameter(torch.tensor(alpha1 * np_w1 + alpha2 * np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = fused_conv(torch_x)
loss = out.sum()
loss.backward()
torch_fused_w_updated = fused_conv.weight.detach().numpy() - (alpha1**2 + alpha2**2) * fused_conv.weight.grad.numpy() * lr
print(torch_fused_w_updated)在RepOptVGG中,对应的CSLA块则是将RepVGG块中的3x3卷积,1x1卷积,bn层替换为带可学习缩放参数的3x3卷积,1x1卷积
进一步拓展到多分支中,假设s,t分别是3x3卷积,1x1卷积的缩放系数,那么对应的更新规则为:

第一条公式对应输入通道==输出通道,此时一共有3个分支,分别是identity,conv3x3, conv1x1
第二条公式对应输入通道!=输出通道,此时只有conv3x3, conv1x1两个分支
第三条公式对应其他情况
需要注意的是CSLA没有BN这种训练期间非线性算子(training-time nonlinearity),也没有非顺序性(non sequential)可训练参数,CSLA在这里只是一个描述RepOptimizer的间接工具。
那么剩下一个问题,即如何确定这个缩放系数
HyperSearch
受DARTS启发,我们将CSLA中的常数缩放系数,替换成可训练参数。在一个小数据集(如CIFAR100)上进行训练,在小数据上训练完毕后,我们将这些可训练参数固定为常数。
具体的训练设置可参考论文
实验结果

实验效果看上去非常不错,训练中没有多分支,可训练的batchsize也能增大,模型吞吐量也提升不少。
在之前RepVGG中,不少人吐槽量化困难,那么在RepOptVGG下,这种直筒模型对于量化十分友好: 代码简单走读
代码简单走读
我们主要看 repoptvgg.py 这个文件,核心类是 RepVGGOptimizer
在reinitialize 方法中,它做的就是repvgg的工作,将1x1卷积权重和identity分支给融到3x3卷积中:
if len(scales) == 2:
conv3x3.weight.data = conv3x3.weight * scales[1].view(-1, 1, 1, 1) \
+ F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[0].view(-1, 1, 1, 1)
else:
assert len(scales) == 3
assert in_channels == out_channels
identity = torch.from_numpy(np.eye(out_channels, dtype=np.float32).reshape(out_channels, out_channels, 1, 1))
conv3x3.weight.data = conv3x3.weight * scales[2].view(-1, 1, 1, 1) + F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[1].view(-1, 1, 1, 1)
if use_identity_scales: # You may initialize the imaginary CSLA block with the trained identity_scale values. Makes almost no difference.
identity_scale_weight = scales[0]
conv3x3.weight.data += F.pad(identity * identity_scale_weight.view(-1, 1, 1, 1), [1, 1, 1, 1])
else:
conv3x3.weight.data += F.pad(identity, [1, 1, 1, 1])然后我们再看下GradientMask生成逻辑,如果只有conv3x3和conv1x1两个分支,根据前面的CSLA等价变换规则,conv3x3的mask对应为:
mask = torch.ones_like(para) * (scales[1] ** 2).view(-1, 1, 1, 1)而conv1x1的mask,需要乘上对应缩放系数的平方,并加到conv3x3中间:
mask[:, :, 1:2, 1:2] += torch.ones(para.shape[0], para.shape[1], 1, 1) * (scales[0] ** 2).view(-1, 1, 1, 1)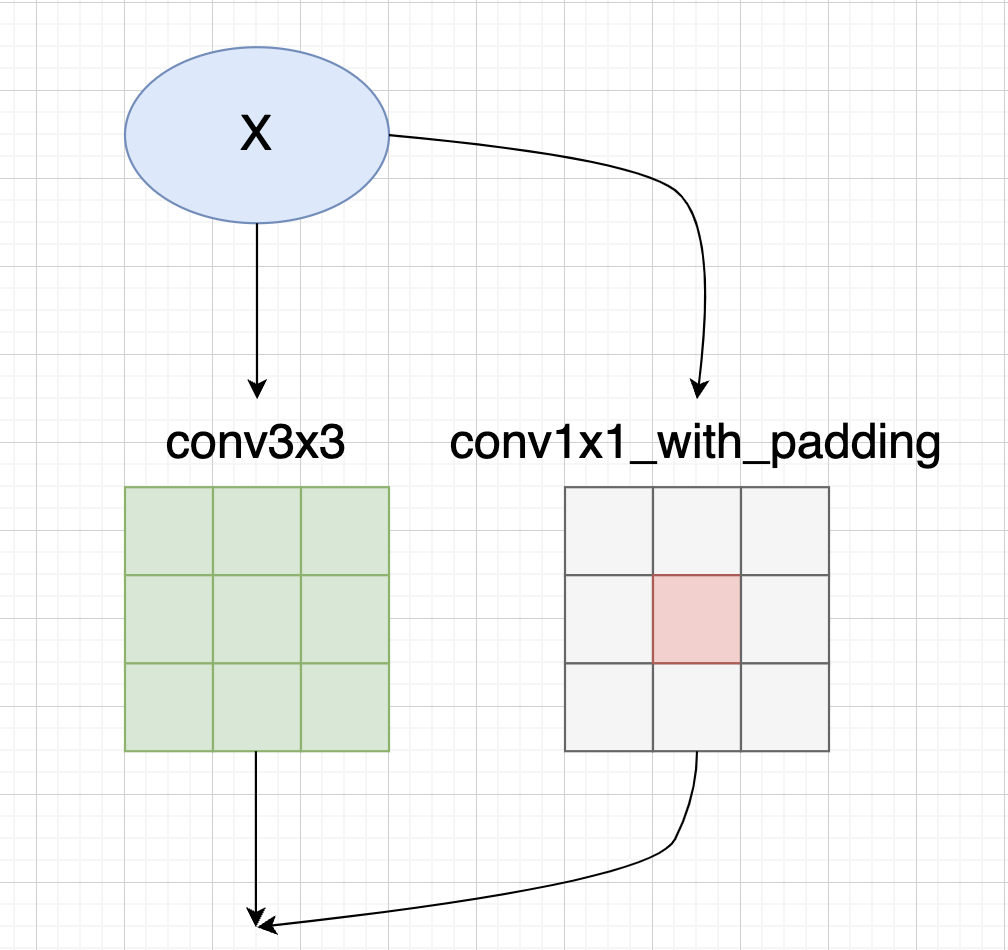 如果还有Identity分支,我们则需要在对角线上加上1.0(Identity分支没有可学习缩放系数)
如果还有Identity分支,我们则需要在对角线上加上1.0(Identity分支没有可学习缩放系数)
mask[ids, ids, 1:2, 1:2] += 1.0如果有不明白Identity分支为什么对应的是对角线,可以参考下笔者的图解RepVGG
总结
这篇文章出来有段时间了,但是好像没有很多人关注。在我看来这是个实用性很高的工作,解决了上一代RepVGG留下的小坑,真正实现了训练时完全直筒的模型,并且对量化,剪枝友好,十分适合实际部署。
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~
边栏推荐
- Huawei cloud SRE deterministic operation and maintenance special issue (the first issue)
- 电路模块分析练习6(开关)
- 电路模块分析练习5(电源)
- MySQL数据库常用函数和查询
- Equivalence class, boundary value, application method and application scenario of scenario method
- Xampp重启后,MySQL服务就启动不了。
- [modulebuilder] GP service realizes the intersection selection of two layers in SDE
- CDN加速是什么
- 元宇宙标准论坛成立
- Which PHP open source works deserve attention
猜你喜欢
Why is BeanUtils not recommended?
Utilisation de la classe Ping d'Unity
![[modulebuilder] GP service realizes the intersection selection of two layers in SDE](/img/4a/899a3c2a0505d2ec2eaae97a3948c9.png)
[modulebuilder] GP service realizes the intersection selection of two layers in SDE

多模态数据也能进行MAE?伯克利&谷歌提出M3AE,在图像和文本数据上进行MAE!最优掩蔽率可达75%,显著高于BERT的15%...

C language (I)
如何用jmeter做接口测试

问题记录与思考
Why is the frame rate calculated by opencv wrong?
[eosio] eos/wax signature error is_ Canonical (c): signature is not canonical

Circuit module analysis exercise 5 (power supply)

随机推荐
[opencv450 samples] inpaint restores the selected region in the image using the region neighborhood
C language (I)
1281_FreeRTOS_vTaskDelayUntil实现分析
UE4_UE5结合offline voice recognition插件做语音识别功能
Unity technical manual - particle foundation main module attributes - upper
Idea FAQ collection
Idea common plug-ins
Fegin client entry test
异或运算符简单逻辑运算 a^=b
不荒唐的茶小程序-规则改动
STM32 development board + smart cloud aiot+ home monitoring and control system
[modulebuilder] GP service realizes the intersection selection of two layers in SDE
[eosio] eos/wax signature error is_ Canonical (c): signature is not canonical
How to use JMeter for interface testing
Oracle - getting started
Unity技术手册 - GetKey和GetAxis和GetButton
APP-新功能上线
Sword finger offer 46 Translate numbers to strings (DP)
ES6 const constants and array deconstruction
ES6 --- 数值扩展、对象拓展