当前位置:网站首页>多表的查询
多表的查询
2022-08-02 07:24:00 【embelfe_segge】
目录
② 如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表
?3.可以给表起别名,在SELECT和WHERE中使用表的别名
#查询员工id,员工姓名及其管理者的id和姓名 —— 自连接
?表连接的约束条件可以有三种方式:WHERE, ON, USING
一、为什么需要多表查询?
??查询一个员工名为“Abel”的人在哪个城市工作?
1.先查询出他的全部信息
SELECT *
FROM employees
WHERE last_name = 'Abel';

2.得知他在80号部门时,查询80号部门的信息
SELECT *
FROM departments
WHERE department_id = 80;
 3.由结果可知城市id为2055
3.由结果可知城市id为2055
SELECT *
FROM locations
WHERE location_id = 2500;

二、如何实现多表查询
1.出现笛卡尔积(交叉连接)的错误
笛卡尔乘积是一个数学运算。
假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能 组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。
组合的个数即为两个集合中元素个数的乘积数
①错误的实现方式
每个员工都与每个部门匹配了一遍
SELECT employee_id,department_name
FROM employees,departments; #查询出2889条记录
SELECT employee_id,department_name
FROM employees CROSS JOIN departments;
②错误的原因
- 省略多个表的连接条件(或关联条件)
- 连接条件(或关联条件)无效
- 所有表中的所有行互相连接

2.多表查询的正确方式 —— 需要有连接条件
①两个表的连接条件
为了避免笛卡尔积, 可以在 WHERE 加入有效的连接条件。
SELECT employee_id,department_name
FROM employees,departments
WHERE employees.department_id = departments.department_id; #106条 (不包含NULL)
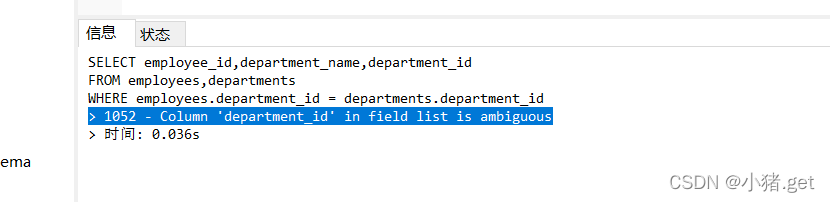
② 如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表
SELECT employee_id,department_name,department_id
FROM employees,departments
WHERE employees.department_id = departments.department_id; #106条 (不包含NULL)
department_id在employees和departments表中都存在,未指明在哪个表中时:
SELECT employee_id,department_name,employees.department_id
FROM employees,departments
WHERE employees.department_id = departments.department_id; #106条 (不包含NULL)
从sql优化的角度,建议多表查询时,每个字段前都指明其所在的表
SELECT employees.employee_id,departments.department_name,department_id FROM employees,departments WHERE employees.department_id = departments.department_id; #106条 (不包含NULL)
3.可以给表起别名,在SELECT和WHERE中使用表的别名
SELECT emp.employee_id,dept.department_name,dept.department_id
FROM employees emp,departments dept
WHERE emp.department_id = dept.department_id; #106条 (不包含NULL)
??注意
如果给表起了别名,一旦在SELECT或WHERE中使用表的别名的话,则必须使用表的别名,而不能再使用表的原名
三、多表查询的分类
1.等值连接&非等值连接
非等值连接的例子
SELECT *
FROM job_grades;
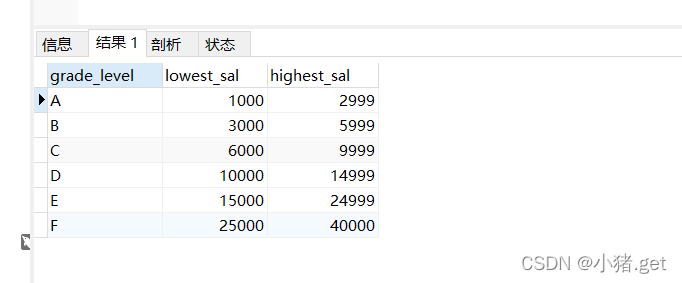 非等值连接
非等值连接
SELECT last_name,salary,grade_level
FROM employees e,job_grades j
#WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal
WHERE e.salary >= j.lowest_sal AND e.salary <= j.highest_sal;
2.自连接&非自连接
#查询员工id,员工姓名及其管理者的id和姓名 —— 自连接
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name
FROM employees emp,employees mgr
WHERE emp.manager_id = mgr.employee_id;
3.内连接&外连接
①内连接
合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
SELECT employee_id,department_name
FROM employees,departments
WHERE employees.department_id = departments.department_id; #106条 (不包含NULL)
②外连接
两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的 行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
外连接的分类:左外连接,右外连接,满外连接
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
查询_所有的_员工的employee_id,department_name信息

SQL92语法实现外连接 :使用 +
MySQL不支持SQL92语法中外连接的写法
SELECT employee_id,department_name
FROM employees e,departments d
WHERE e.department_id = d.department_id(+);
SQL99语法实现多表的查询
使用JOIN … ON 的方式实现多表的查询。这种方式也能解决外连接的问题,且MySQL支持
Ⅰ.SQL99语法实现内连接
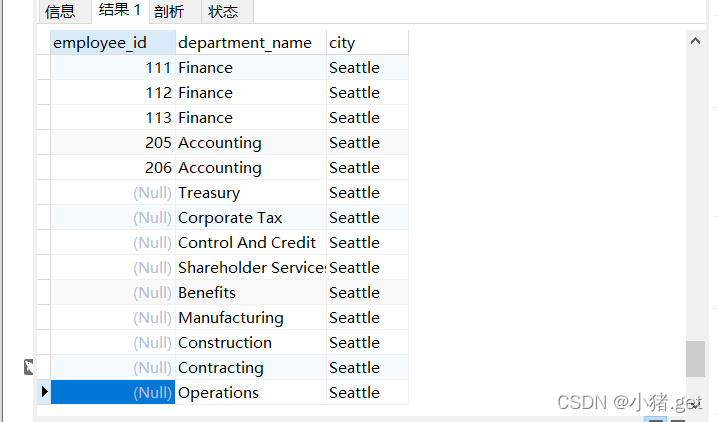
SELECT employee_id,department_name,city
FROM employees e JOIN departments d
ON e.department_id = d.department_id
JOIN locations l
ON d.location_id = l.location_id;
Ⅱ.SQL99语法实现外连接
左外连接:
SELECT employee_id,department_name,city
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id;
右外连接:
SELECT employee_id,department_name,city
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id;
满外连接:
MySQL不支持FULL OUTER JOIN
SELECT employee_id,department_name,city
FROM employees e FULL OUTER JOIN departments d
ON e.department_id = d.department_id;
Ⅲ.使用SQL99实现7种JOIN操作
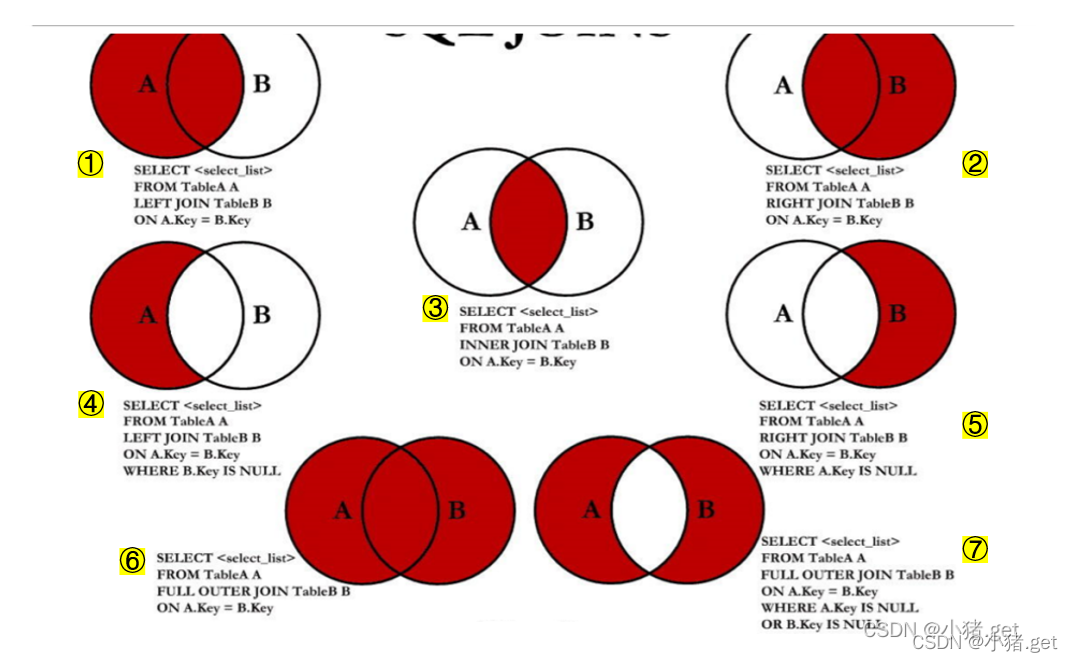
·图③的实现 :内连接
SELECT employee_id,department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
·图①的实现 :左外连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id;
·图②的实现 :右外连接
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id;
·图④的实现
在①的基础上抹除相同的部分
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE D.department_id IS NULL;
·图⑤的实现
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
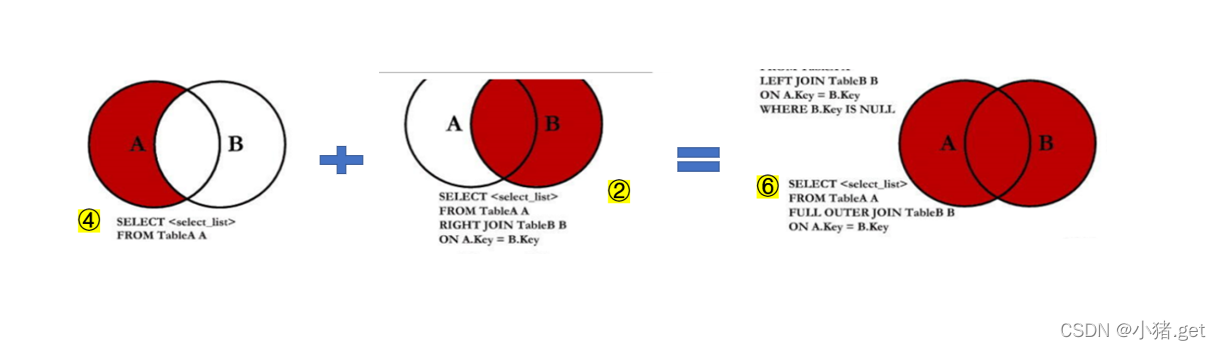
·图⑥的实现:满外连接
方式(1):① UNION ALL ⑤

SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
方式(2):④ UNION ALL ②
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE D.department_id IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id;
·图⑦的实现
④ UNION ALL ⑤: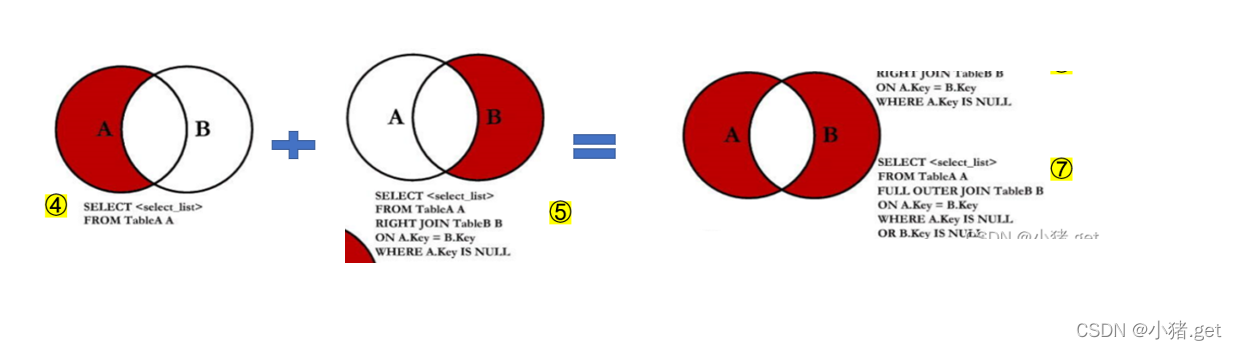
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE D.department_id IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
Ⅳ.补充:UNION和UNION ALL的使用
1.合并查询结果
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
2.UNION 操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。

3…UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。

注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据 不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
四、SQL99语法的新特性
1.自然连接
SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 用来表示自然连接。我们可以把 自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中 所有相同的字段 ,然后进行等值 连接 。

在 SQL99 中你可以写成:
SELECT employee_id,last_name,department_name
FROM employees e NATURAL JOIN departments d;
2.USING连接
当我们进行连接的时候,SQL99还支持使用 USING 指定数据表里的 同名字段进行等值连接。但是只能配合JOIN一起使用。比如:

你能看出与自然连接 NATURAL JOIN 不同的是,USING 指定了具体的相同的字段名称,你需要在 USING 的括号 () 中填入要指定的同名字段。同时使用 JOIN…USING 可以简化 JOIN ON 的等值连接。它与下 面的 SQL 查询结果是相同的:
SELECT employee_id,last_name,department_name
FROM employees e ,departments d
WHERE e.department_id = d.department_id;
表连接的约束条件可以有三种方式:WHERE, ON, USING
WHERE:适用于所有关联查询
ON :只能和JOIN一起使用,只能写关联条件。虽然关联条件可以并到WHERE中和其他条件一起 写,但分开写可读性更好。
USING:只能和JOIN一起使用,而且要求两个关联字段在关联表中名称一致,而且只能表示关联字 段值相等
五、相关的表
1.employees表

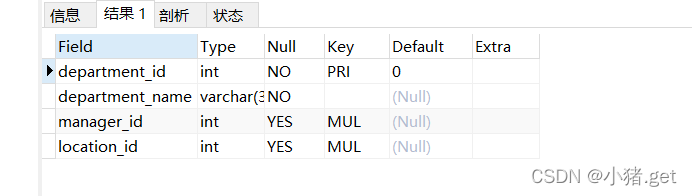
2.departments表
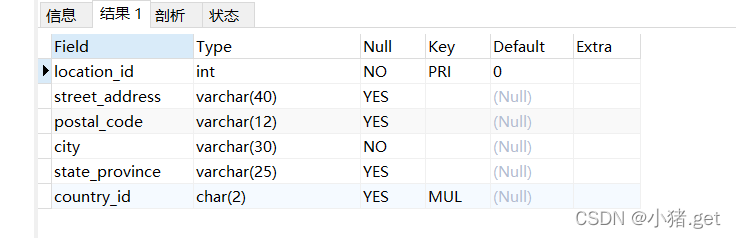
 3.locations表
3.locations表
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
边栏推荐
- sql创建表格 如图 运行完提示invalid table name 是什么原因
- 用户身份标识与账号体系实践
- spark架构
- 类型“DropDownList”的控件“ContentPlaceHolder1_ddlDepartment”必须放在具有 runat=server 的窗体标记内。
- 论文理解:“Cross-Scale Residual Network: A GeneralFramework for Image Super-Resolution,Denoising, and “
- Appium 滑动问题
- MySQL - slow query log
- 读入、输出优化
- MySQL-数据库设计规范
- Xilinx Constraint Study Notes - Timing Constraints
猜你喜欢







随机推荐
Link with Game Glitch
MySQL常见索引类型
Inverter insulation detection detection function and software implementation
替换ptmalloc,使用tcmalloc和jemalloc
gdalinfo: error while loading shared libraries: libgdal.so.30: cannot open shared object file: No su
典型的一次IO的两个阶段是什么?阻塞、非阻塞、同步、异步
View zombie processes
pnpm install出现:ERR_PNPM_PEER_DEP_ISSUES Unmet peer dependencies
OC-Category
设置工作模式与环境(中):建造二级引导器
OC-error prompt
PanGu-Coder:函数级的代码生成模型
mysql如何从某一行检索到最后
MySQL - Detailed Explanation of Database Transactions
Modify apt-get source to domestic mirror source
LeetCode 2360. The longest cycle in a graph
MySQL - low level settings
Appium 滑动问题
MySQL - based
MySQL - Index Optimization and Query Optimization