当前位置:网站首页>Merge and migrate data from small data volume, sub database and sub table Mysql to tidb
Merge and migrate data from small data volume, sub database and sub table Mysql to tidb
2022-07-03 06:04:00 【Tianxiang shop】
If you want to put more upstream MySQL The database instance is merged and migrated to the same downstream TiDB In the database , And the amount of data is small , You can use DM Use the tool to merge and migrate databases and tables . In this article “ Small data volume ” Usually refers to TiB Below grade . This article introduces the operation steps of merge and migration with examples 、 matters needing attention 、 Troubleshooting, etc . This document applies to :
- TiB Consolidation and migration of sub database and sub table data within level
- be based on MySQL binlog The incremental 、 Continue to merge and migrate by database and table
To migrate the sum of sub tables 1 TiB The above data , be DM The tool takes a long time , May refer to From the big data volume sub database sub table MySQL Merge and migrate data to TiDB.
This article takes a simple scenario as an example , The two data sources in the example MySQL The database and table data of the instance are migrated to the downstream TiDB colony . The schematic diagram is as follows .

data source MySQL example 1 and example 2 The following table structure is used , It is planned that store_01 and store_02 in sale The first table is merged and imported downstream store.sale surface
| Schema | Tables |
|---|---|
| store_01 | sale_01, sale_02 |
| store_02 | sale_01, sale_02 |
The structure of the migration target library is as follows :
| Schema | Tables |
|---|---|
| store | sale |
Prerequisite
Split table data conflict check
If database and table merging are involved in the migration , Data from multiple sub tables may cause data conflicts of primary keys or unique indexes . So before migration , It is necessary to check the business characteristics of each sub table data . Please refer to Conflict handling of cross table data in primary key or unique index
In this example :sale_01 and sale_02 The same table structure is as follows :
CREATE TABLE `sale_01` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `sid` bigint(20) NOT NULL, `pid` bigint(20) NOT NULL, `comment` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `sid` (`sid`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
among id List as primary key ,sid List as fragment key , With global uniqueness .id Columns have self incrementing properties , The repetition of multiple sub table ranges will cause data conflicts .sid It can ensure that the unique index is satisfied globally , Therefore, you can follow the reference Remove the primary key attribute of the auto increment primary key The operations described in bypass id Column . Create downstream sale Remove on table id Unique key attribute of the column
CREATE TABLE `sale` ( `id` bigint(20) NOT NULL, `sid` bigint(20) NOT NULL, `pid` bigint(20) NOT NULL, `comment` varchar(255) DEFAULT NULL, INDEX (`id`), UNIQUE KEY `sid` (`sid`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
The first 1 Step : create data source
newly build source1.yaml file , Write the following :
# Unique name , Do not repeat . source-id: "mysql-01" # DM-worker Whether to use the global transaction identifier (GTID) Pull binlog. The premise of use is upstream MySQL Enabled GTID Pattern . If there is master-slave automatic switching in the upstream , Must be used GTID Pattern . enable-gtid: true from: host: "${host}" # for example :172.16.10.81 user: "root" password: "${password}" # Clear text password is supported but not recommended , It is recommended to use dmctl encrypt Encrypt the plaintext password and use port: 3306
Execute the following command in the terminal , Use tiup dmctl Load the data source configuration into DM In the cluster :
tiup dmctl --master-addr ${advertise-addr} operate-source create source1.yaml
The parameters in this command are described as follows :
| Parameters | describe |
|---|---|
| --master-addr | dmctl Any of the clusters to be connected DM-master Node {advertise-addr}, for example :172.16.10.71:8261 |
| operate-source create | towards DM The cluster loads the data source |
Repeat the above operations until all data sources are added .
The first 2 Step : Create migration tasks
newly build task1.yaml file , Write the following :
name: "shard_merge" # Task mode , May be set as # full: Only full data migration # incremental: binlog Real time synchronization # all: Total quantity + binlog transfer task-mode: all # Database and table consolidation tasks need to be configured shard-mode. Pessimistic coordination mode is used by default "pessimistic", After in-depth understanding of the principles and limitations of optimistic coordination mode , It can also be set to optimistic coordination mode "optimistic" # Details are available :https://docs.pingcap.com/zh/tidb/dev/feature-shard-merge/ shard-mode: "pessimistic" meta-schema: "dm_meta" # Will be created in the downstream database schema Used to store metadata ignore-checking-items: ["auto_increment_ID"] # In this example, there is a self incrementing primary key in the upstream , Therefore, this check item needs to be ignored target-database: host: "${host}" # for example :192.168.0.1 port: 4000 user: "root" password: "${password}" # Clear text password is supported but not recommended , It is recommended to use dmctl encrypt Encrypt the plaintext password and use mysql-instances: - source-id: "mysql-01" # data source ID, namely source1.yaml Medium source-id route-rules: ["sale-route-rule"] # Applied to this data source table route The rules filter-rules: ["store-filter-rule", "sale-filter-rule"] # Applied to this data source binlog event filter The rules block-allow-list: "log-bak-ignored" # Applied to this data source Block & Allow Lists The rules - source-id: "mysql-02" route-rules: ["sale-route-rule"] filter-rules: ["store-filter-rule", "sale-filter-rule"] block-allow-list: "log-bak-ignored" # Split table consolidation configuration routes: sale-route-rule: schema-pattern: "store_*" table-pattern: "sale_*" target-schema: "store" target-table: "sale" # Filter section DDL event filters: sale-filter-rule: schema-pattern: "store_*" table-pattern: "sale_*" events: ["truncate table", "drop table", "delete"] action: Ignore store-filter-rule: schema-pattern: "store_*" events: ["drop database"] action: Ignore # Black and white list block-allow-list: log-bak-ignored: do-dbs: ["store_*"]
The above is the minimum task configuration for performing migration . More configuration items about tasks , You can refer to DM Introduction to the complete configuration file of the task
If you want to know about routes,filters Wait for more usage , Please refer to :
- Table routing
- Block & Allow Table Lists
- How to filter binlog event
- How to use SQL Expression filtering DML
The first 3 Step : Start the task
Before you start the data migration task , It is recommended to use check-task Command to check whether the configuration conforms to DM Configuration requirements for , To reduce the probability of error reporting in the later stage .
tiup dmctl --master-addr ${advertise-addr} check-task task.yaml
Use tiup dmctl Execute the following command to start the data migration task .
tiup dmctl --master-addr ${advertise-addr} start-task task.yaml
The parameters in this command are described as follows :
| Parameters | describe |
|---|---|
| --master-addr | dmctl Any of the clusters to be connected DM-master Node {advertise-addr}, for example :172.16.10.71:8261 |
| start-task | The command is used to create a data migration task |
If the task fails to start , You can change the configuration according to the prompt of the returned result start-task task.yaml Command to restart the task . Please refer to Faults and handling methods as well as common problem
The first 4 Step : View task status
If you need to know DM Whether there are running migration tasks and task status in the cluster , You can use tiup dmctl perform query-status Command to query :
tiup dmctl --master-addr ${advertise-addr} query-status ${task-name}
Detailed interpretation of query results , Please refer to State of the query
The first 5 Step : Monitor tasks and view logs ( Optional )
You can go through Grafana Or log to view the historical status of the migration task and various internal operation indicators .
adopt Grafana see
If you use TiUP Deploy DM When the cluster , Deployed correctly Prometheus、Alertmanager And Grafana, Use the IP And Port access Grafana, choice DM Of dashboard see DM Relevant monitoring items .
Through the log view
DM At run time ,DM-worker, DM-master And dmctl Will output relevant information through the log , It contains information about the migration task . The log directory of each component is as follows :
- DM-master Log directory : adopt DM-master Process parameters
--log-fileSet up . If you use TiUP Deploy DM, The log directory is located in/dm-deploy/dm-master-8261/log/. - DM-worker Log directory : adopt DM-worker Process parameters
--log-fileSet up . If you use TiUP Deploy DM, The log directory is located in/dm-deploy/dm-worker-8262/log/.
- DM-master Log directory : adopt DM-master Process parameters
边栏推荐
- [trivia of two-dimensional array application] | [simple version] [detailed steps + code]
- pytorch 多分类中的损失函数
- Skywalking8.7 source code analysis (II): Custom agent, service loading, witness component version identification, transform workflow
- 从 Amazon Aurora 迁移数据到 TiDB
- 1. 两数之和
- Solve the 1251 client does not support authentication protocol error of Navicat for MySQL connection MySQL 8.0.11
- Virtual memory technology sharing
- Clickhouse learning notes (2): execution plan, table creation optimization, syntax optimization rules, query optimization, data consistency
- Multithreading and high concurrency (7) -- from reentrantlock to AQS source code (20000 words, one understanding AQS)
- Alibaba cloud OOS file upload
猜你喜欢

QT read write excel -- qxlsx insert chart 5
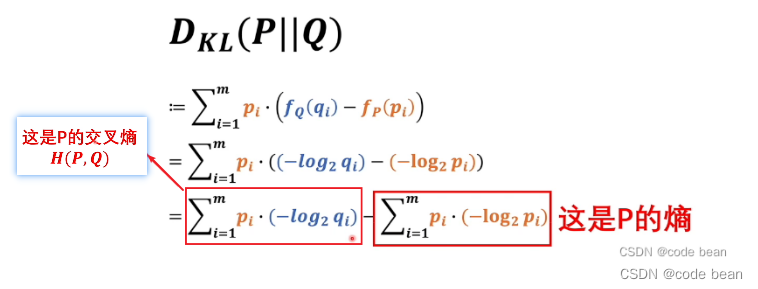
Maximum likelihood estimation, divergence, cross entropy
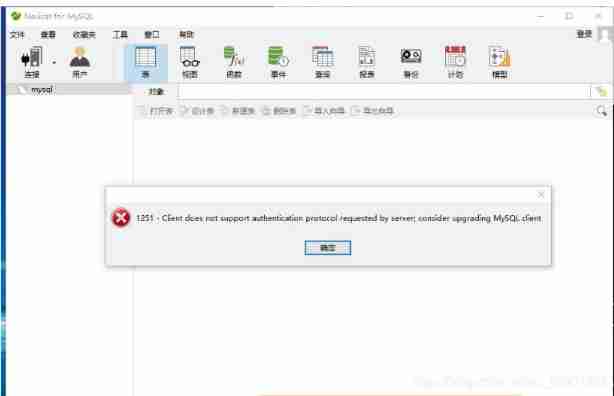
Solve the 1251 client does not support authentication protocol error of Navicat for MySQL connection MySQL 8.0.11

从小数据量 MySQL 迁移数据到 TiDB

卷积神经网络CNN中的卷积操作详解
![Ensemble, série shuishu] jour 9](/img/39/c1ba1bac82b0ed110f36423263ffd0.png)
Ensemble, série shuishu] jour 9

PHP notes are super detailed!!!

Clickhouse learning notes (I): Clickhouse installation, data type, table engine, SQL operation

CKA certification notes - CKA certification experience post
Oauth2.0 - using JWT to replace token and JWT content enhancement
随机推荐
[teacher Zhao Yuqiang] use the catalog database of Oracle
Kubernetes notes (IX) kubernetes application encapsulation and expansion
为什么网站打开速度慢?
Ensemble, série shuishu] jour 9
Understand the first prediction stage of yolov1
[teacher Zhao Yuqiang] redis's slow query log
[trivia of two-dimensional array application] | [simple version] [detailed steps + code]
Installation of CAD plug-ins and automatic loading of DLL and ARX
[teacher Zhao Yuqiang] MySQL high availability architecture: MHA
Ext4 vs XFS -- which file system should you use
智牛股--03
Together, Shangshui Shuo series] day 9
Core principles and source code analysis of disruptor
[set theory] relational closure (reflexive closure | symmetric closure | transitive closure)
Leetcode problem solving summary, constantly updating!
pytorch 搭建神经网络最简版
[explain in depth the creation and destruction of function stack frames] | detailed analysis + graphic analysis
[teacher Zhao Yuqiang] kubernetes' probe
Multithreading and high concurrency (7) -- from reentrantlock to AQS source code (20000 words, one understanding AQS)
深度学习,从一维特性输入到多维特征输入引发的思考