当前位置:网站首页>【GCN-CTR】DC-GNN: Decoupled GNN for Improving and Accelerating Large-Scale E-commerce Retrieval WWW22
【GCN-CTR】DC-GNN: Decoupled GNN for Improving and Accelerating Large-Scale E-commerce Retrieval WWW22
2022-07-25 13:09:00 【chad_ lee】
《DC-GNN: Decoupled Graph Neural Networks for Improving and Accelerating Large-Scale E-commerce Retrieval》(WWW’22)
In the industrial scene , Tens of billions of nodes and hundreds of billions of edges are directly end-to-end GNN-based CTR Model overhead is too high , The article puts the whole GNN The framework is decoupled into three stages : Preliminary training 、 polymerization 、CTR.
But in fact, the article moves the computational cost forward , The computational cost of graph convolution is converted into the computational cost of mining graph .
Graphs and datasets
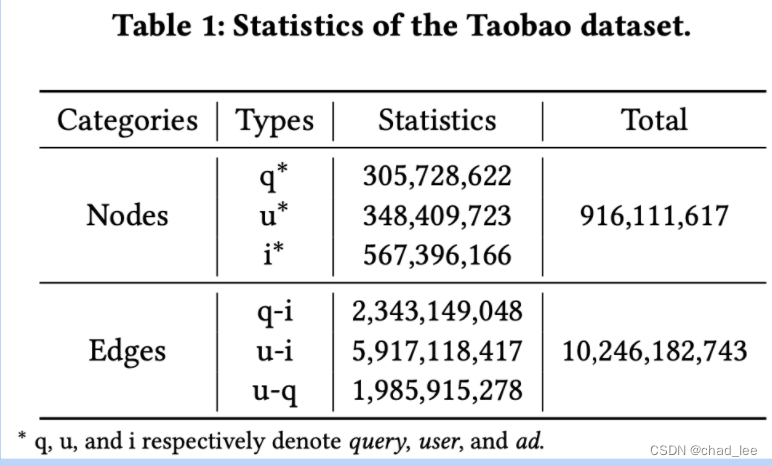
use Taobao near 7 Days of records as a data set , There are three types of nodes :user、query and item, Each node has rich node attributes : equipment 、 Age etc. .
There are three kinds of edges :query Search for item、 User browsing item、 Users to search query.
altogether 9 Billion nodes 、100 Hundred million sides .
Method

Preliminary training
Every node First use RW Generate Three Subgraph of this node , Then use GNN encoder Convolutional coding of nodes , Get the embedding, Then two pre training tasks :
Link Prediction
L l i n k = ∑ ( q , i p ) ∈ E ( − log σ ( f s ( q , i p ) ) − ∑ k log ( 1 − σ ( f s ( q , i n k ) ) ) ) \mathcal{L}_{l i n k}=\sum_{\left(q, i_{p}\right) \in \mathcal{E}}\left(-\log \sigma\left(f_{s}\left(q, i_{p}\right)\right)-\sum_{k} \log \left(1-\sigma\left(f_{s}\left(q, i_{n}^{k}\right)\right)\right)\right) Llink=(q,ip)∈E∑(−logσ(fs(q,ip))−k∑log(1−σ(fs(q,ink))))
The case with edge connection is a positive example , Then collect k individual Negative example , Negative examples use difficult negative sample mining :

One is choice K-hop As a negative sample ,K Can control the degree of difficulty ; One is to keep the graph structure unchanged , Replace a positive sample with a globally collected negative sample .
The article believes that these two practices can be strengthened GNN Pay more attention to the attribute learning of nodes , avoid GNN Over reliance on graph structural features , So as to alleviate over-smoothing.
Multi-view graph contrastive learning
From the second and third subgraphs embedding, Contrast learning , The same node is in two views embedding It's a case in point , Different nodes are negative . Here we only consider the calculation between nodes of the same kind InfoNCE loss, Therefore, there will be three comparative learning loss.
be-all loss Add up to total loss:
L q u e r y = ∑ q 1 ∈ v q − log exp ( w f s ( q 1 , q 2 ) ) ∑ v ∈ exp ( w f s ( q 1 , v 2 ) ) L u s e r = ∑ u 1 ∈ v u , v u ∈ V − log exp ( w f s ( u 1 , u 2 ) ) ∑ v exp ( w f s ( u 1 , v 2 ) ) L a d = ∑ i 1 ∈ v i , v i ∈ V − log exp ( w f s ( i 1 , i 2 ) ) ∑ v exp ( w f s ( i 1 , v 2 ) ) L contra = L query + L user + L a d L total = L link + λ 1 L contra + λ 2 ∥ θ ∥ 2 2 \begin{aligned} \mathcal{L}_{q u e r y}&=\sum_{q_{1} \in v_{q}}-\log \frac{\exp \left(w f_{s}\left(q_{1}, q_{2}\right)\right)}{\sum_{v} \in \exp \left(w f_{s}\left(q_{1}, v_{2}\right)\right)}\\ \mathcal{L}_{u s e r} &=\sum_{\substack{u_{1} \in v_{u}, v_{u} \in \mathcal{V}}}-\log \frac{\exp \left(w f_{s}\left(u_{1}, u_{2}\right)\right)}{\sum_{v} \exp \left(w f_{s}\left(u_{1}, v_{2}\right)\right)} \\ \mathcal{L}_{a d} &=\sum_{\substack{i_{1} \in v_{i}, v_{i} \in \mathcal{V}}}-\log \frac{\exp \left(w f_{s}\left(i_{1}, i_{2}\right)\right)}{\sum_{v} \exp \left(w f_{s}\left(i_{1}, v_{2}\right)\right)}\\ \mathcal{L}_{\text {contra }}&=\mathcal{L}_{\text {query }}+\mathcal{L}_{\text {user }}+\mathcal{L}_{a d} \\ \mathcal{L}_{\text {total }}&=\mathcal{L}_{\text {link }}+\lambda_{1} \mathcal{L}_{\text {contra }}+\lambda_{2}\|\theta\|_{2}^{2} \end{aligned} LqueryLuserLadLcontra Ltotal =q1∈vq∑−log∑v∈exp(wfs(q1,v2))exp(wfs(q1,q2))=u1∈vu,vu∈V∑−log∑vexp(wfs(u1,v2))exp(wfs(u1,u2))=i1∈vi,vi∈V∑−log∑vexp(wfs(i1,v2))exp(wfs(i1,i2))=Lquery +Luser +Lad=Llink +λ1Lcontra +λ2∥θ∥22
Deep Aggregation
In the first stage, each node already has one embedding $X 了 , then Sample again , For each node , Sample three subgraphs of different classes , such as target node yes user, Sample three subgraphs for this node , Each subgraph shows target node outside , Each contains only user、query、item node .
Then on the basis of existing subgraphs , and SIGN Same as that one , Directly join the vectors of convolution of different orders [ X , A X , A 2 X , A 3 X ] \left[X, A X, A^{2} X, A^{3} X\right] [X,AX,A2X,A3X] As input to the model . But there are misleading things here , Should be 1+3*3=10 Join the two vectors together , Because there are three subgraphs , Each subgraph has a third-order matrix , So it should actually be :
[ X , A 1 X , A 1 2 X , A 1 3 X , A 2 X , A 2 2 X , A 2 3 X , A 3 X , A 3 2 X , A 3 3 X ] \left[X, A_1X, A_1^{2} X, A_1^{3} X,A_2X, A_2^{2} X, A_2^{3} X,A_3X, A_3^{2} X, A_3^{3} X\right] [X,A1X,A12X,A13X,A2X,A22X,A23X,A3X,A32X,A33X]
CTR Prediction
chart 1.3, The spliced vectors are sent into the twin towers , Conduct CTR forecast . Negative samples are exposed samples that are not clicked :
L C T R = ∑ ( − log σ ( f s ( ( q , u ) , i c l k ) ) − ∑ k log ( 1 − σ ( f s ( ( q , u ) , i p v k ) ) ) ) \mathcal{L}_{C T R}=\sum\left(-\log \sigma\left(f_{s}\left((q, u), i_{c l k}\right)\right)-\sum_{k} \log \left(1-\sigma\left(f_{s}\left((q, u), i_{p v}^{k}\right)\right)\right)\right) LCTR=∑(−logσ(fs((q,u),iclk))−k∑log(1−σ(fs((q,u),ipvk))))
experiment

DC-GNN-Pf and DC-GNN-Pt It means skipping Deep Aggregation, Direct use pretrain Output embedding Input CTR, then fix perhaps fine-tuning embedding.
边栏推荐
- Cv2.resize function reports an error: error: (-215:assertion failed) func= 0 in function ‘cv::hal::resize‘
- Seven lines of code made station B crash for three hours, but "a scheming 0"
- go : gin 自定义日志输出格式
- 程序员成长第二十七篇:如何评估需求优先级?
- Docekr学习 - MySQL8主从复制搭建部署
- 使用vsftpd服务传输文件(匿名用户认证、本地用户认证、虚拟用户认证)
- Cyberspace Security penetration attack and defense 9 (PKI)
- 【AI4Code】《GraphCodeBERT: Pre-Training Code Representations With DataFlow》 ICLR 2021
- Use of Spirng @conditional conditional conditional annotation
- State mode
猜你喜欢

How to use causal inference and experiments to drive user growth| July 28 tf67
G027-OP-INS-RHEL-04 RedHat OpenStack 创建自定义的QCOW2格式镜像

Convolutional neural network model -- alexnet network structure and code implementation

Vim技巧:永远显示行号

Zero basic learning canoe panel (13) -- trackbar

Chapter5 : Deep Learning and Computational Chemistry

【视频】马尔可夫链原理可视化解释与R语言区制转换MRS实例|数据分享

2022 年中回顾 | 大模型技术最新进展 澜舟科技

485 communication (detailed explanation)

【问题解决】org.apache.ibatis.exceptions.PersistenceException: Error building SqlSession.1 字节的 UTF-8 序列的字
随机推荐
零基础学习CANoe Panel(16)—— Clock Control/Panel Control/Start Stop Control/Tab Control
Docekr learning - MySQL 8 master-slave replication setup deployment
【运维、实施精品】月薪10k+的技术岗位面试技巧
迁移PaloAlto HA高可用防火墙到Panorama
Common operations for Yum and VIM
AtCoder Beginner Contest 261E // 按位思考 + dp
ECCV 2022 | climb to the top semantickitti! Semantic segmentation of LIDAR point cloud based on two-dimensional prior assistance
业务可视化-让你的流程图'Run'起来(3.分支选择&跨语言分布式运行节点)
clickhouse笔记03-- Grafana 接入ClickHouse
程序员成长第二十七篇:如何评估需求优先级?
Zero basic learning canoe panel (14) -- led control and LCD control
【AI4Code】《GraphCodeBERT: Pre-Training Code Representations With DataFlow》 ICLR 2021
web安全入门-UDP测试与防御
[problem solving] org.apache.ibatis.exceptions PersistenceException: Error building SqlSession. 1-byte word of UTF-8 sequence
Azure Devops(十四) 使用Azure的私有Nuget仓库
Use of Spirng @conditional conditional conditional annotation
Substance Designer 2021软件安装包下载及安装教程
[Video] visual interpretation of Markov chain principle and Mrs example of R language region conversion | data sharing
[machine learning] experimental notes - emotion recognition
go : gin 自定义日志输出格式