当前位置:网站首页>End to end object detection with transformers (Detr) paper reading and understanding
End to end object detection with transformers (Detr) paper reading and understanding
2022-07-02 19:20:00 【liiiiiiiiiiiiike】
Thesis title :End-to-End Object Detection with Transformers
Thesis link :DETR
Abstract :
Come up with a new way , Target detection is directly regarded as a set prediction problem ( In fact, no matter proposal,anchor,window centers Methods are essentially set prediction methods , Use a lot of prior knowledge to intervene manually , for example NMS); and DETR Is pure end-to-end, The whole training does not need human intervention in advance .DETR The training steps are :(1)CNN by backbone De extraction feature (2)Transformer encoder Learn the overall characteristics (3)transformer decoder Generate forecast box (100)(4) Forecast box and GT Do the matching Highlights of the article . When reasoning, you don't need to (4), After the prediction box is generated, it is output through threshold judgment .
brief introduction
DETR Adopt a method based on transformer The encoder - Decoder structure , The self attention mechanism is used to show the interaction between all elements in the coding sequence , The advantage of this is that the redundant boxes generated in target detection can be deleted !!,DETR Predict all goals at once , And through the set loss function for end-to-end training , This function performs bipartite graph matching between the predicted results and the real results .( For example, produce 100 box ,GT by 10, Calculate, predict and GT most match Of 10 box , We think it is a positive sample , rest 90 All negative samples , There is no need for NMS)
Related work
DETR Work is based on :(1) Bipartite graph matching loss for set prediction (2)transformer encoder-decoder (3) Parallel decoding and target detection .
(1) Set prediction
At present, most detectors need post-processing NMS To and from redundant boxes . However, post-processing is not required for direct set prediction , Global reasoning model to simulate the interaction between all prediction elements , Redundancy can be avoided . For set prediction of constant sets ,MLP Just ok 了 ( violence : Every one counts as a match ), But the cost is high . Usually the solution is to design a loss based on Hungarian algorithm , To find a bipartite match between the real value and the predicted value .
(2)Transformer structure
Attention mechanism can gather information from the whole input sequence . One of the main advantages of self attention based models : Is its global computing and perfect memory .( Feel the field !)
(3) object detection
Most target detection is mainly proposal,anchor,window center To predict , But there are many redundant boxes , Here we have to use NMS. and DETR Can be removed NMS So as to achieve end-to-end.
DETR Model
In the target detection model , There are two factors that are critical to direct aggregate forecasting :
(1) Set forecast loss , It enforces predictions and GT The only match between
(2) Predict a set of objects at once and model the relationship between them
Set forecast loss
In a decoder In the process ,DETR Recommend N Prediction set of results ,N Similar to assigning pictures N Boxes . One of the main difficulties in training is to predict the object according to the real value ( Category , Location , size ) Score . The paper sets the prediction objectives and GT The best bipartite match between , Then optimize the loss of specific target bounding box .
- The first step is to get the only bipartite matching cost , In order to find a bipartite match between the prediction box and the real box ( similar :3 One worker ,A fit 1 Mission ,B fit 2 Mission ,C fit 3 Mission , How to allocate the minimum cost ), Looking for a N The arrangement of elements minimizes the overhead .( That is, the optimal allocation )
Previous work , hungarian algorithm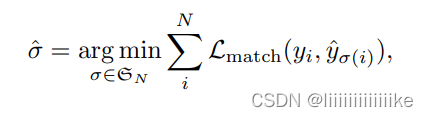
The paper : Every element in the truth set i Can be seen as yi =( ci,bi ),ci Is the target class label ( Note that it may be ∅);bi It's a vector [0, 1]^4, Defined b-box The center coordinate of and its height and width relative to the size of the image .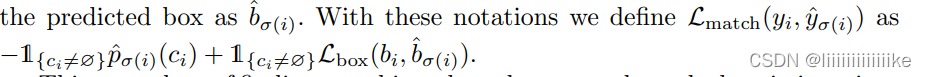
- The second step is to calculate the loss function , That is, the Hungarian loss of all matching pairs in the previous step . Our definition of loss is similar to that of general target detector , That is, the negative log likelihood of class prediction and the detection frame loss defined later Lbox The linear combination of :

3. Bounding box loss :
Rate the bounding box . Unlike many detectors that make bounding box predictions through some initial guesses , Let's do the bounding box prediction directly . Although this method simplifies the implementation , But it raises a problem of relative scaling loss . Most commonly used L1 Losses have different scales for small and large bounding boxes , Even if their relative errors are similar . To alleviate the problem , We use L1 Loss and scale invariant generalized IoU A linear combination of losses .
DETR frame
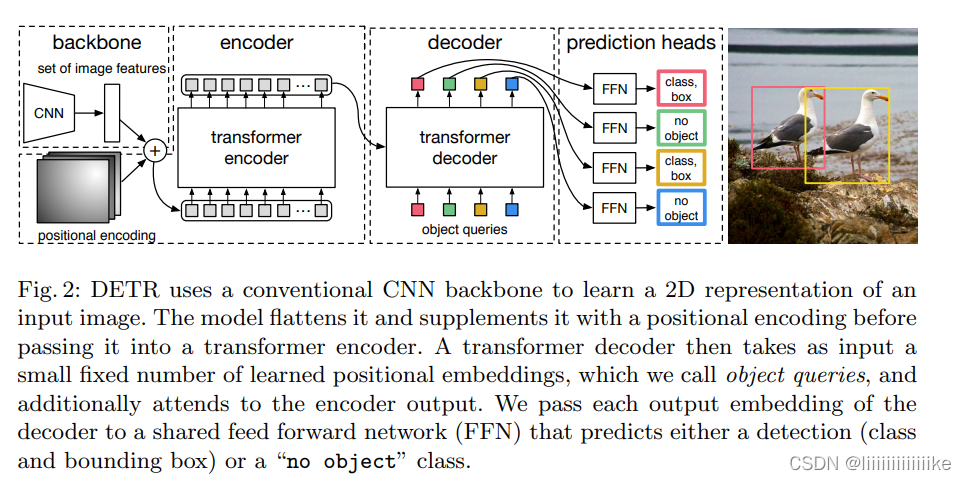
backbone:
Initial image :H * W *3, After traditional CNN Generate a low resolution feature map (H/32, W/32,2048)
Transformer encoder:
The first use of 1*1 conv Reduce dimension into (H/32, W/32,256), Draw the feature map into a sequence , Convenient as transformer The input of , Each encoder has a standard structure , It consists of a multi head self attention module and a FFN(MLP) form . because transformer Architecture is order insensitive , We use fixed position coding to supplement it , And add it to the input of each attention layer .
Transformer decoder:
The decoder follows transformer The standard architecture of , Convert to dimension d Of N Embedded . With primordial Transformer Difference is that , Each decoder decodes in parallel N Objects . Because the decoder is constant , therefore N Input embedding must be different to produce different results , These input embeddings are learned location codes , Become object queries. Follow encoder equally , Add it to decoder in . And then through FFN, Decode them independently into box coordinates and class labels , The resulting N Forecast . Use self attention and encoder-decoder, The model uses the pairwise relationship between all objects for global reasoning , At the same time, the whole image can be used as the context !!
FFN:
The final prediction is made by a Relu、3 Layer of MLP And a linear projection layer .FFN Predict the normalized center coordinates of the input image 、 The height and width of the box , The linear layer uses softmax Function prediction class label . Due to the prediction of a containing fixed size N A collection of bounding boxes , among N Usually more than in the image GT The quantity is much larger , Therefore, an additional special class tag is used to indicate that no target is detected at this location .
In the process of training , Auxiliary coding loss is very helpful in decoder , Especially in helping the model output the correct number of objects of each class , Add prediction after each encoder layer FFS And Hungary lost . All predictions FFN All share parameters .
边栏推荐
- 2022编译原理期末考试 回忆版
- [100 cases of JVM tuning practice] 03 -- four cases of JVM heap tuning
- ORA-01455: converting column overflows integer datatype
- 数字滚动带动画
- Advanced performance test series "24. Execute SQL script through JDBC"
- "Patient's family, please come here" reading notes
- STM32G0 USB DFU 升级校验出错-2
- Web2.0的巨头纷纷布局VC,Tiger DAO VC或成抵达Web3捷径
- What is 9D movie like? (+ common sense of dimension space)
- Excel如何进行隔行复制粘贴
猜你喜欢
数据降维——因子分析
yolov3 训练自己的数据集之生成train.txt
Data dimensionality reduction factor analysis

云呐|为什么要用固定资产管理系统,怎么启用固定资产管理系统
Compile oglpg-9th-edition source code with clion
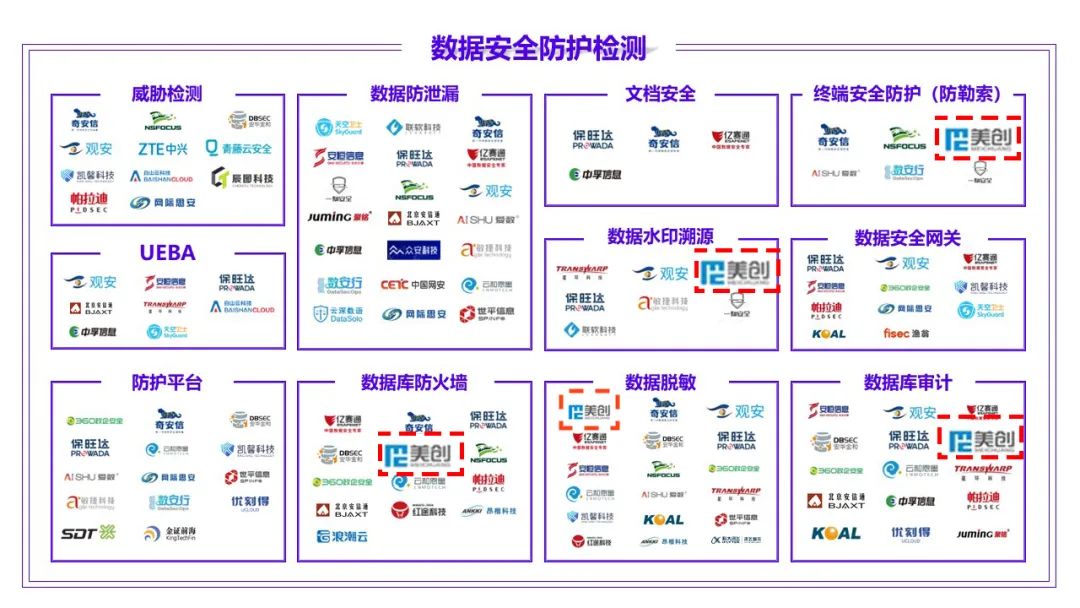
According to the atlas of data security products and services issued by the China Academy of information technology, meichuang technology has achieved full coverage of four major sectors

机器学习笔记 - 时间序列预测研究:法国香槟的月销量
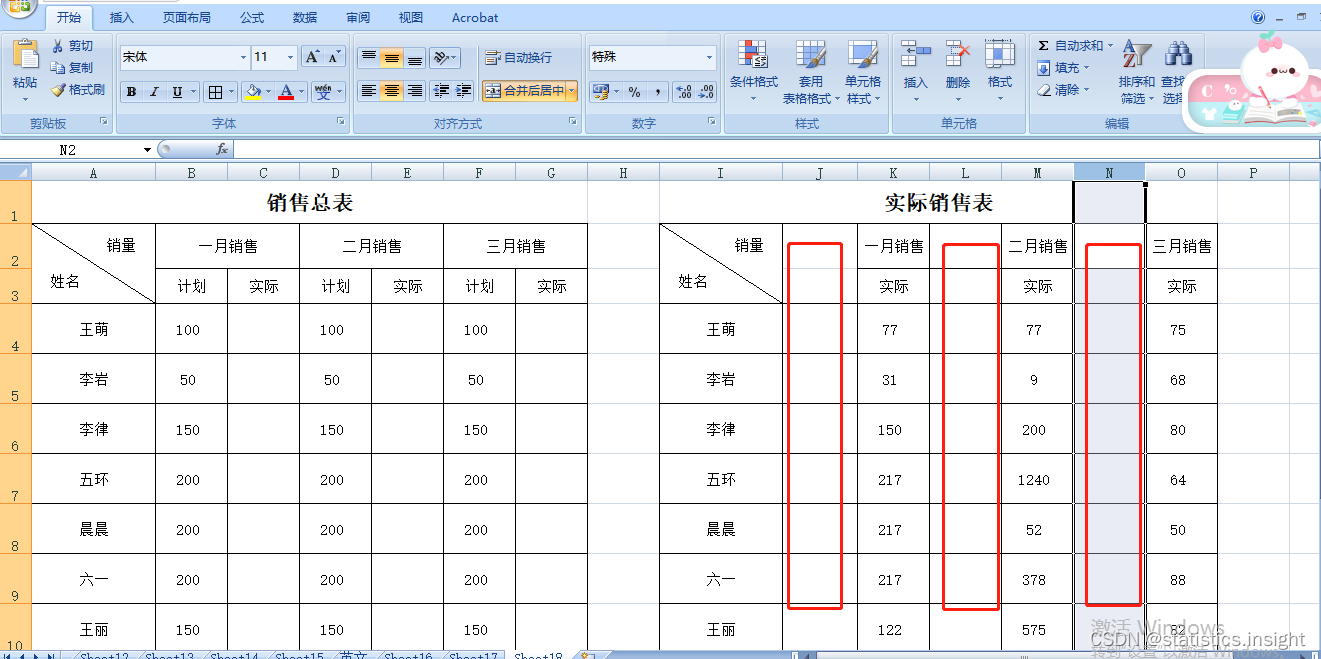
How to copy and paste interlaced in Excel

How to play when you travel to Bangkok for the first time? Please keep this money saving strategy

线程应用实例
随机推荐
使用 Cheat Engine 修改 Kingdom Rush 中的金钱、生命、星
Masa framework - DDD design (1)
Imitation Jingdong magnifying glass effect (pink teacher version)
ICDE 2023|TKDE Poster Session(CFP)
Emmet basic syntax
Juypter notebook modify the default open folder and default browser
According to the atlas of data security products and services issued by the China Academy of information technology, meichuang technology has achieved full coverage of four major sectors
【测试开发】软件测试—概念篇
Date tool class (updated from time to time)
End-to-End Object Detection with Transformers(DETR)论文阅读与理解
学习八股文的知识点~~1
Page title component
数据降维——因子分析
高级性能测试系列《24. 通过jdbc执行sql脚本》
How to copy and paste interlaced in Excel
Excel finds the same value in a column, deletes the row or replaces it with a blank value
机器学习笔记 - 时间序列预测研究:法国香槟的月销量
R language dplyr package Na_ The if function converts the control in the vector value into the missing value Na, and converts the specified content into the missing value Na according to the mapping r
页面标题组件
【测试开发】一文带你了解什么是软件测试