当前位置:网站首页>Distribution gaussienne, régression linéaire, régression logistique
Distribution gaussienne, régression linéaire, régression logistique
2022-06-27 06:07:00 【Les mangues sont très brillantes】
Distribution gaussienneGaussian distribution/Distribution normaleNormal distribution
1.Une présence étendue
2020Année11Mois24Jour,Lancement réussi de la sonde Chang'e 5.Son orbite est critique,Une courbe peut être calculée à partir des trois lois de Kepler,Mais la courbe n'est qu'une piste idéale,Il y a une erreur dans l'orbite réelle,Comment le résoudre??Cette question a hanté la communauté scientifique pendant des années,Jusqu'à ce que Gauss publie《Théorie du Mouvement céleste》Il n'y a que des solutions concrètes.Le livre présente une méthode:Méthode des moindres carrés,À condition que l'erreur de mesure soit conforme à la distribution normale.
“Gao Fu Shuai”,La taille des hommes adultes d'un pays correspond à la distribution gaussienne;“Double11”,Le volume des ventes du produit est également conforme à la distribution gaussienne;“CET-4/6”,Les résultats des examens des étudiants sont également conformes à la distribution gaussienne;“Isolement épidémique14Oh, mon Dieu.”,14Le ciel est calculé à partir de la distribution gaussienne……Derrière tant d'événements très différents, il y a des ombres gaussiennes.
Shanghai a choisi au hasard1000Hommes,Notez la taille de chacun,Diviser les données en50Intervalles,Tracer un histogramme de fréquence,J'ai trouvé la taille174cmLe plus grand nombre,Les extrémités gauche et droite sont particulièrement courtes/Les grands sont rarement.Élargir les données10X/100X/10000X,Dessinez la section plus fine.Une courbe lisse peut être tracée —— Distribution gaussienne/Distribution normale.
2.Distribution gaussienne
Distribution normale/Courbe de distribution gaussienneComme un pic.,Il y a des hauts et des bas, des hauts et des bas,(Hauteur moyenne,Bas des deux côtés,Symétrie des deux côtés). Déterminé par deux paramètres :Moyenneμ( Moyenne des données représentatives )、Écart typeσ( Représente le degré de dispersion des données ,Plus l'écart type est grand, Certaines valeurs sont loin de la moyenne , Plus discrète , Plus le pic est lent ;Plus l'écart type est faible, La valeur est proche de la moyenne , Plus l'agglomération , Plus la montagne est raide .)
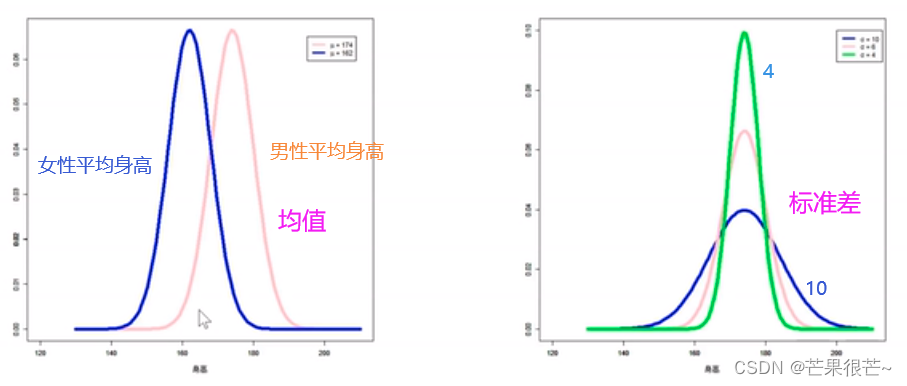
Exemple: Du chocolat Dev VSPommes, L'emballage de Dev montre 43g, Mais il y a une petite erreur par rapport à la réalité , Son poids satisfait à la valeur moyenne de 43gLa distribution gaussienne de, L'écart type est très faible . Peser chaque pomme , Son poids répond également à la distribution gaussienne , Supposons que le poids moyen soit 250g, Alors la pomme Poids réel autour de la moyenne 250gDistribution symétrique gauche - droite, Par rapport à Defoe , L'écart type est très élevé .

3.3σ-Lignes directrices

(μ-σ,μ+σ)Section, La probabilité qu'un événement tombe est 68.2%;(μ-2σ,μ+2σ), La probabilité que l'événement tombe est 95.4%;(μ-3σ,μ+3σ), La probabilité que l'événement tombe est 99.73%;Certains pensent 3σ- Les règles ne sont pas assez strictes , Il y a six Sigma Gérer les normes de qualité , C'est - à - dire que l'intervalle est étendu à (μ-6σ,μ+6σ), La probabilité de tomber est 99.9998%, La probabilité de tomber en dehors de l'intervalle n'est que de deux parties par milliard .
4. Galton nailboard Experiment — “Chapitre 9” L'ordinateur quantique est sorti



“Chapitre 9” Une nouvelle percée dans l'informatique quantique en Chine , Résoudre les algorithmes mathématiques Gauss Bose Sampling La vitesse de 200Secondes, Et les superordinateurs actuels utilisent 6Milliards d'années.
L'appareil d'échantillonnage Bose n'est pas seulement le choix de la gauche et de la droite dans l'expérience de Galton nailboard , Mais ils interagissent , Et plus d'un photon à la fois , Peut - être un grand nombre de photons , Cela peut entraîner des problèmes de temps .
Régression linéaire — Méthode des moindres carrés
Tracer le flux quotidien moyen de personnes dans les cafés du centre commercial (Argumentsx) Et le revenu journalier moyen ( Variables prévues , Variable attendue y) Un diagramme de dispersion des données .
Régression linéaire:AvecUne ligne droite Pour ajuster la relation entre les variables indépendantes et dépendantes (Équation linéairey=kx+b)
Comment obtenir cette ligne ?—— Méthode des moindres carrés. Estimation obtenue par régression linéaire , Plus l'estimation est proche de la valeur réelle, mieux c'est. , Représente une estimation plus précise .

Régression logiquelogistics regression = Régression linéaire+sigmoidFonctions
Un algorithme d'exploration des données ,À quoi bon?? Utilisé pour résoudre les problèmes de classification secondaire . Pas de régression logique “Retour” Tricher en deux mots !!!
Questions de classification: Problèmes liés à la détermination de la catégorie de données .Ii) Questions de classification: Il n'y a que deux catégories d'objectifs pour les problèmes de classification
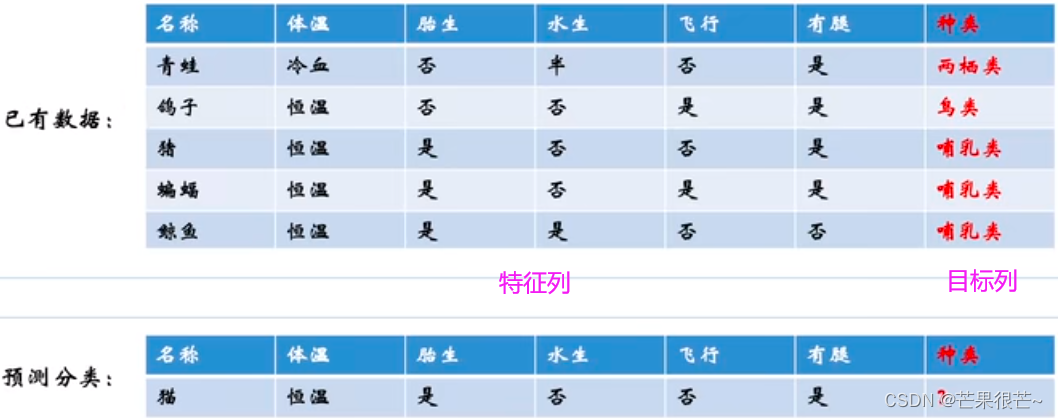
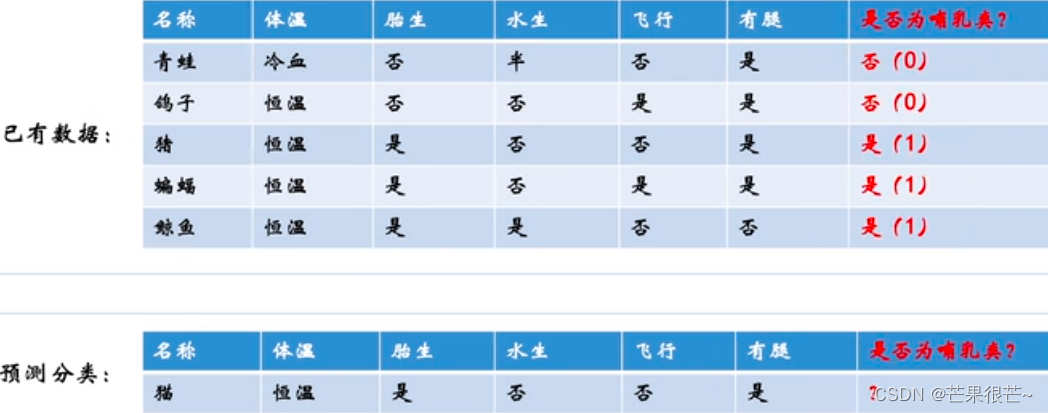
La différence entre régression et classification? Résultats continus du modèle de régression ,La sortie du modèle de classification est discrète.

En prenant la valeur de la fonction de régression linéaire comme sigmoidEntrée de la fonction


Comment résoudre
Plus la fonction de perte est petite, Le meilleur modèle de régression !


La solution n'a pas besoin d'être calculée manuellement , Le Code peut gérer !DisponiblesparkCadre
边栏推荐
- [FPGA] realize the data output of checkerboard horizontal and vertical gray scale diagram based on bt1120 timing design
- 30 SCM common problems and solutions!
- Dev++ 环境设置C语言关键字显示颜色
- The form verifies the variables bound to the V-model, and the solution to invalid verification
- Proxy reflect usage details
- [FPGA] UART serial port_ V1.1
- Proxy-Reflect使用详解
- What's new in redis4.0 - active memory defragmentation
- Add widget on qlistwidgetitem
- Program ape learning Tiktok short video production
猜你喜欢

IAR Systems全面支持芯驰科技9系列芯片

Assembly language - Wang Shuang Chapter 13 int instruction - Notes

My opinion on test team construction

【QT小作】使用结构体数据生成读写配置文件代码

函数栈帧的形成与释放

使用 WordPress快速个人建站指南

Implementation of easyexcel's function of merging cells with the same content and dynamic title

汇编语言-王爽 第8章 数据处理的两个基本问题-笔记

426-二叉树(513.找树左下角的值、112. 路径总和、106.从中序与后序遍历序列构造二叉树、654. 最大二叉树)

使用CSDN 开发云搭建导航网站
随机推荐
Jump details of item -h5 list, and realize the function of not refreshing when backing up, and refreshing when modifying data (record scroll bar)
Using domain name forwarding mqtt protocol, pit avoidance Guide
项目-h5列表跳转详情,实现后退不刷新,修改数据则刷新的功能(记录滚动条)
openresty使用文档
QT using Valgrind to analyze memory leaks
[FPGA] realize the data output of checkerboard horizontal and vertical gray scale diagram based on bt1120 timing design
JVM class loading mechanism
【Cocos Creator 3.5.1】this.node.getPosition(this._curPos)的使用
爬虫学习5---反反爬之识别图片验证码(ddddocr和pytesseract实测效果)
程序猿学习抖音短视频制作
Leetcode99 week race record
【Cocos Creator 3.5.1】event.getButton()的使用
Dual position relay dls-34a dc0.5a 220VDC
Asp. Net core6 websocket simple case
JVM garbage collection mechanism
Redis4.0新特性-主动内存碎片整理
Proxy-Reflect使用详解
【合辑】点云基础知识及点云催化剂软件功能介绍
思维的技术:如何破解工作生活中的两难冲突?
【QT小作】使用结构体数据生成读写配置文件代码