当前位置:网站首页>全文检索引擎Solr系列—–全文检索基本原理
全文检索引擎Solr系列—–全文检索基本原理
2022-07-03 13:53:00 【星哥玩云】
场景:小时候我们都使用过新华字典,妈妈叫你翻开第38页,找到“坑爹”所在的位置,此时你会怎么查呢?毫无疑问,你的眼睛会从38页的第一个字开始从头至尾地扫描,直到找到“坑爹”二字为止。这种搜索方法叫做顺序扫描法。对于少量的数据,使用顺序扫描是够用的。但是妈妈叫你查出坑爹的“坑”字在哪一页时,你要是从第一页的第一个字逐个的扫描下去,那你真的是被坑了。此时你就需要用到索引。索引记录了“坑”字在哪一页,你只需在索引中找到“坑”字,然后找到对应的页码,答案就出来了。因为在索引中查找“坑”字是非常快的,因为你知道它的偏旁,因此也就可迅速定位到这个字。
那么新华字典的目录(索引表)是怎么编写而成的呢?首先对于新华字典这本书来说,除去目录后,这本书就是一堆没有结构的数据集。但是聪明的人类善于思考总结,发现每个字都会对应到一个页码,比如“坑”字就在第38页,“爹”字在第90页。于是他们就从中提取这些信息,构造成一个有结构的数据。类似数据库中的表结构:
word page_no
---------------
坑 38
爹 90
... ...这样就形成了一个完整的目录(索引库),查找的时候就非常方便了。对于全文检索也是类似的原理,它可以归结为两个过程:1.索引创建(Indexing)2. 搜索索引(Search)。那么索引到底是如何创建的呢?索引里面存放的又是什么东西呢?搜索的的时候又是如何去查找索引的呢?带着这一系列问题继续往下看。
索引
Solr/Lucene采用的是一种反向索引,所谓反向索引:就是从关键字到文档的映射过程,保存这种映射这种信息的索引称为反向索引
- 左边保存的是字符串序列
- 右边是字符串的文档(Document)编号链表,称为倒排表(Posting List)
字段串列表和文档编号链表两者构成了一个字典。现在想搜索”lucene”,那么索引直接告诉我们,包含有”lucene”的文档有:2,3,10,35,92,而无需在整个文档库中逐个查找。如果是想搜既包含”lucene”又包含”solr”的文档,那么与之对应的两个倒排表去交集即可获得:3、10、35、92。
索引创建
假设有如下两个原始文档: 文档一:Students should be allowed to go out with their friends, but not allowed to drink beer. 文档二:My friend Jerry went to school to see his students but found them drunk which is not allowed. 创建过程大概分为如下步骤:
一:把原始文档交给分词组件(Tokenizer) 分词组件(Tokenizer)会做以下几件事情(这个过程称为:Tokenize),处理得到的结果是词汇单元(Token)
- 将文档分成一个一个单独的单词
- 去除标点符号
- 去除停词(stop word)
- 所谓停词(Stop word)就是一种语言中没有具体含义,因而大多数情况下不会作为搜索的关键词,这样一来创建索引时能减少索引的大小。英语中停词(Stop word)如:”the”、”a”、”this”,中文有:”的,得”等。不同语种的分词组件(Tokenizer),都有自己的停词(stop word)集合。经过分词(Tokenizer)后得到的结果称为词汇单元(Token)。上例子中,便得到以下词汇单元(Token): "Students","allowed","go","their","friends","allowed","drink","beer","My","friend","Jerry","went","school","see","his","students","found","them","drunk","allowed"
二:词汇单元(Token)传给语言处理组件(Linguistic Processor) 语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些语言相关的处理。对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
- 变为小写(Lowercase)。
- 将单词缩减为词根形式,如”cars”到”car”等。这种操作称为:stemming。
- 将单词转变为词根形式,如”drove”到”drive”等。这种操作称为:lemmatization。
语言处理组件(linguistic processor)处理得到的结果称为词(Term),例子中经过语言处理后得到的词(Term)如下:
"student","allow","go","their","friend","allow","drink","beer","my","friend","jerry","go","school","see","his","student","find","them","drink","allow"。经过语言处理后,搜索drive时drove也能被搜索出来。Stemming 和 lemmatization的异同:
- 相同之处:
- Stemming和lemmatization都要使词汇成为词根形式。
- 两者的方式不同:
- Stemming采用的是”缩减”的方式:”cars”到”car”,”driving”到”drive”。
- Lemmatization采用的是”转变”的方式:”drove”到”drove”,”driving”到”drive”。
- 两者的算法不同:
- Stemming主要是采取某种固定的算法来做这种缩减,如去除”s”,去除”ing”加”e”,将”ational”变为”ate”,将”tional”变为”tion”。
- Lemmatization主要是采用事先约定的格式保存某种字典中。比如字典中有”driving”到”drive”,”drove”到”drive”,”am, is, are”到”be”的映射,做转变时,按照字典中约定的方式转换就可以了。
- Stemming和lemmatization不是互斥关系,是有交集的,有的词利用这两种方式都能达到相同的转换。
三:得到的词(Term)传递给索引组件(Indexer) 1.利用得到的词(Term)创建一个字典
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2
jerry 2
go 2
school 2
see 2
his 2
student 2
find 2
them 2
drink 2
allow 2
2.对字典按字母顺序排序:
Term Document ID
allow 1
allow 1
allow 2
beer 1
drink 1
drink 2
find 2
friend 1
friend 2
go 1
go 2
his 2
jerry 2
my 2
school 2
see 2
student 1
student 2
their 1
them 2
- 合并相同的词(Term)成为文档倒排(Posting List)链表
- Document Frequency:文档频次,表示多少文档出现过此词(Term)
- Frequency:词频,表示某个文档中该词(Term)出现过几次
对词(Term) “allow”来讲,总共有两篇文档包含此词(Term),词(Term)后面的文档链表总共有两个,第一个表示包含”allow”的第一篇文档,即1号文档,此文档中,”allow”出现了2次,第二个表示包含”allow”的第二个文档,是2号文档,此文档中,”allow”出现了1次
至此索引创建完成,搜索”drive”时,”driving”,”drove”,”driven”也能够被搜到。因为在索引中,”driving”,”drove”,”driven”都会经过语言处理而变成”drive”,在搜索时,如果您输入”driving”,输入的查询语句同样经过分词组件和语言处理组件处理的步骤,变为查询”drive”,从而可以搜索到想要的文档。
搜索步骤
搜索”microsoft job”,用户的目的是希望在微软找一份工作,如果搜出来的结果是:”Microsoft does a good job at software industry…”,这就与用户的期望偏离太远了。如何进行合理有效的搜索,搜索出用户最想要得结果呢?搜索主要有如下步骤:
一:对查询内容进行词法分析、语法分析、语言处理
- 词法分析:区分查询内容中单词和关键字,比如:english and janpan,”and”就是关键字,”english”和”janpan”是普通单词。
- 根据查询语法的语法规则形成一棵树
- 语言处理,和创建索引时处理方式是一样的。比如:leaned–>lean,driven–>drive
二:搜索索引,得到符合语法树的文档集合三:根据查询语句与文档的相关性,对结果进行排序
我们把查询语句也看作是一个文档,对文档与文档之间的相关性(relevance)进行打分(scoring),分数高比较越相关,排名就越靠前。当然还可以人工影响打分,比如百度搜索,就不一定完全按照相关性来排名的。
如何评判文档之间的相关性?一个文档由多个(或者一个)词(Term)组成,比如:”solr”, “toturial”,不同的词可能重要性不一样,比如solr就比toturial重要,如果一个文档出现了10次toturial,但只出现了一次solr,而另一文档solr出现了4次,toturial出现一次,那么后者很有可能就是我们想要的搜的结果。这就引申出权重(Term weight)的概念。
权重表示该词在文档中的重要程度,越重要的词当然权重越高,因此在计算文档相关性时影响力就更大。通过词之间的权重得到文档相关性的过程叫做空间向量模型算法(Vector Space Model)
影响一个词在文档中的重要性主要有两个方面:
- Term Frequencey(tf),Term在此文档中出现的频率,ft越大表示越重要
- Document Frequency(df),表示有多少文档中出现过这个Trem,df越大表示越不重要 物以希为贵,大家都有的东西,自然就不那么贵重了,只有你专有的东西表示这个东西很珍贵,权重的公式:
空间向量模型
文档中词的权重看作一个向量
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}把欲要查询的语句看作一个简单的文档,也用向量表示:
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}把搜索出的文档向量及查询向量放入N维度的空间中,每个词表示一维:
夹角越小,表示越相似,相关性越大
边栏推荐
- FPGA test method takes mentor tool as an example
- Uio-66-cooh loaded bendamostine | hydroxyapatite (HA) coated MIL-53 (FE) nanoparticles | baicalin loaded manganese based metal organic skeleton material
- Metal organic framework (MOFs) antitumor drug carrier | pcn-223 loaded with metronidazole | uio-66 loaded with ciprofloxacin hydrochloride( 必贝特医药冲刺科创板:年营收97万亏损1.37亿 拟募资20亿
- 别再问自己适不适合做软件测试了
- 叶酸修饰的金属-有机骨架(ZIF-8)载黄芩苷|金属有机骨架复合磁性材料([email protected])|制备路线
- QT learning 19 standard dialog box in QT (top)
- Leetcode(4)——尋找兩個正序數組的中比特數
- Configure stylelint
- Leetcode (4) - - trouver la médiane de deux tableaux ordonnés positifs
猜你喜欢
Scroll detection of the navigation bar enables the navigation bar to slide and fix with no content
Print. JS -- web page file printing
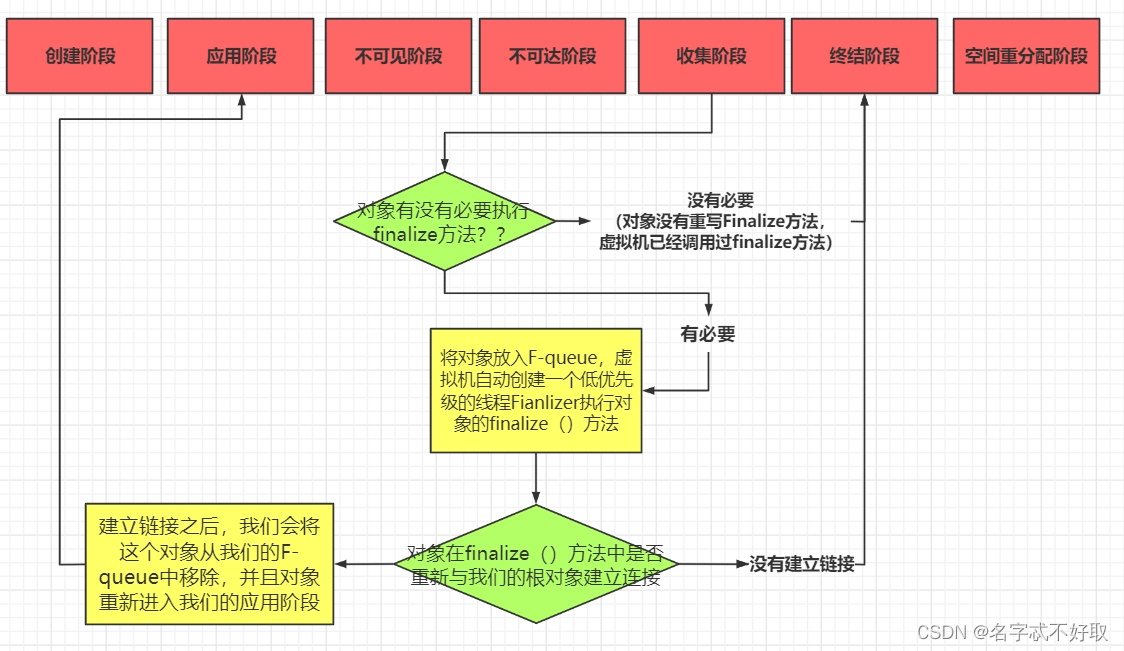
jvm-对象生命周期

QT learning 25 layout manager (4)
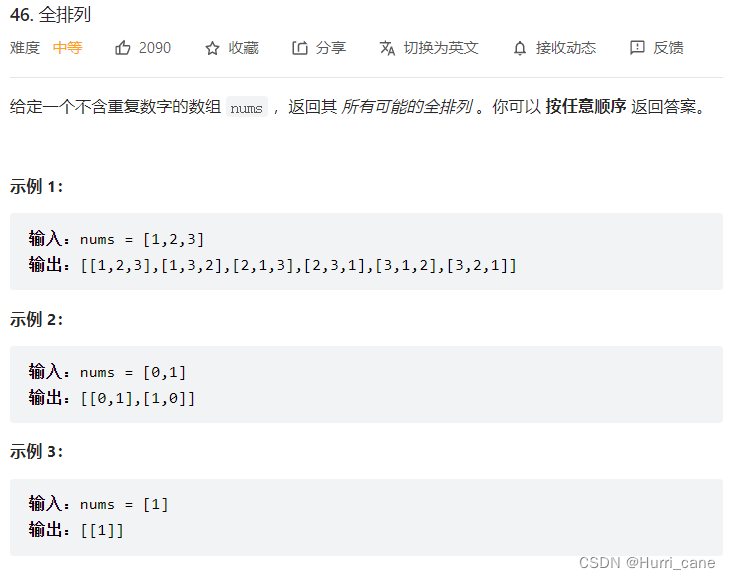
关于回溯问题中的排列问题的思考(LeetCode46题与47题)
Thinking about the arrangement problem in the backtracking problem (leetcode questions 46 and 47)

QT learning 24 layout manager (III)

可编程逻辑器件软件测试

Redis: operation command of string type data

7-9 find a small ball with a balance
随机推荐
Onmenusharetimeline custom shared content is invalid, and the title and icon are not displayed
“又土又穷”的草根高校,凭什么被称为“东北小清华”?
Redis:字符串類型數據的操作命令
Formation of mil-100 (FE) coated small molecule aspirin [email protected] (FE) | glycyrrhetinic acid modified metal organ
Uniapp skills - dom display and hiding
GRPC的四种数据流以及案例
Scroll detection of the navigation bar enables the navigation bar to slide and fix with no content
Although not necessarily the best, it must be the hardest!
JS general form submission 1-onsubmit
Rasp implementation of PHP
FPGA测试方法以Mentor工具为例
Exercise 10-1 judge the three digits that meet the conditions
信创产业现状、分析与预测
2021年区域赛ICPC沈阳站J-Luggage Lock(代码简洁)
QT learning 22 layout manager (I)
JS input number and standard digit number are compared. The problem of adding 0 to 0
好看、好用、强大的手写笔记软件综合评测:Notability、GoodNotes、MarginNote、随手写、Notes Writers、CollaNote、CollaNote、Prodrafts、Noteshelf、FlowUs、OneNote、苹果备忘录
JVM runtime data area
Exercise 6-6 use a function to output an integer in reverse order
Failure of vector insertion element iterator in STL