当前位置:网站首页>Analysis of PostgreSQL storage structure
Analysis of PostgreSQL storage structure
2022-06-28 15:18:00 【Inspur Yunxi database】
Introduction
PostgreSQL Database is a powerful open source database , More and more companies are using PostgreSQL. The storage system is PostgreSQL The lowest level module of , It accesses physical data down through the operating system interface , Provide the interface and function of storage operation for the upper module . This article through to PostgreSQL The storage structure of , Help you understand how this powerful relational database stores data .
- Data directory -
PostgreSQL After installation, you must use initdb The program initializes the data store on the disk , Generate template database and corresponding directory 、 file information .
initdb -D /usr/local/pgsql/data
The initialization directory contains data files 、 Parameter file 、 Control documents 、 Database operation log and WAL Log files, etc , The purpose of the directories and sub files in the following figure will not be described here .

By default ,PostgreSQL All data in is stored in its data directory , This data directory usually uses environment variables PGDATA To quote , For a specific database , stay PGDATA/base There is a subdirectory in the , The name of the subdirectory is the database in the system table pg_database Inside OID, The data of each table is stored in an independent file under its database directory , The file is in the form of filenode Name No , To avoid some file systems that do not support large files ,PostgreSQL Limit the table file size to no more than 1GB( Default 1GB, Compile time via ./configure --with-segsize= x modify ) therefore , When the table file exceeds 1GB when , Will create another file with a suffix relfilenode.1,relfilenode.2…… And so on .
The physical location of the table file is :$PGDATA/BASE/DATABASE_OID/PG_CLASS.RELFILENODE
-- view the database test Of OID
#select oid,datname from pg_database where datname='test';


-- See the table t1 Of filenode
#select pg_relation_filepath('t1');

![]()

- Data file structure -
stay PG in , The smallest management unit in both disk storage and memory is the block , Data blocks stored on disk are called Page, Data blocks in memory are called Buffer, Tables and indexes are called Relation, The lines are called Tuple. The reading and writing of data is based on Page Is the smallest unit , Every Page The default size is 8kB, When compiling the source code, you can use ./configure --with-blocksize=BLOCKSIZE Set other sizes , Cannot be changed thereafter . Each table file consists of multiple BLCKSZ Byte size Page form , Every Page Contains a number of Tuple.
The shared buffer pool in memory caches block block ( Default 1000 individual ), If... In buffer pool block Block is dirty , Need to brush back to the disk , The details of buffer pool will not be repeated here , If necessary, it can be explained in another article .
Page structure
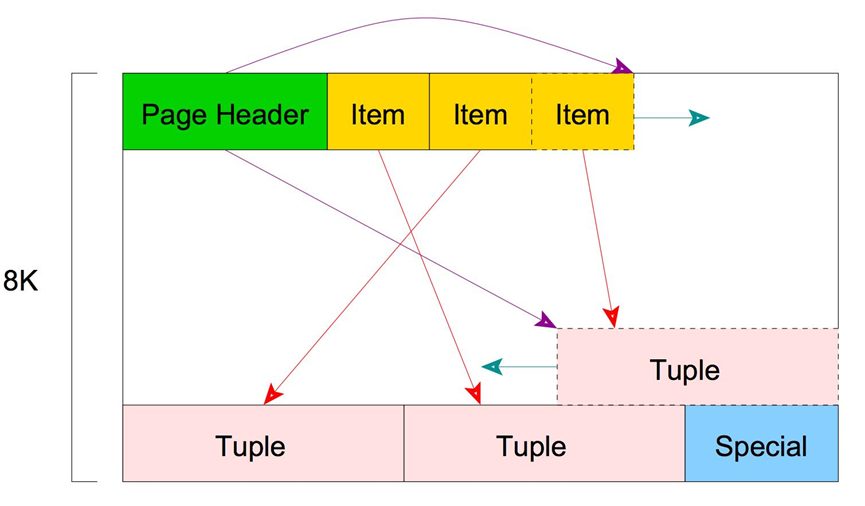
Page The structure consists of five parts :
PageHeaderData -- stay page Head ,24 Byte length , Record page Metadata information .
pg_lsn, Storage page When the latest changes are made ,WAL The log lsn Information .
pg_checksum, Storage page Check value .
pd_flags, Sign a
pg_lower, The offset to the beginning of the free space .
pg_upper, Offset to the end of free space .
pd_pagesize_version, Page size and layout version number information
pd_prune_xid, The page was not deleted at the earliest XMAX, If not, it is 0.
ItemIdData -- stay page header after , A record ( Offset , length ) Array of pairs , Point to the actual tuple term , Every 4 byte .![]()

Free space -- Unallocated space ( Free space ). The new item pointer is allocated from the beginning of this area , The new item is assigned from its end .
Items -- Used to store row data Tuple.
Special space-- Index access mode related data . Different index access methods store different data . Empty in normal table .
Tuple
Tuples in a page can be subdivided into “ Ordinary data tuples and TOAST Tuples ”.
TOAST (The Oversized-Attribute Storage Technique, Super large attribute storage technology ) It is mainly used to store variable length data , When the data size of the tuple to be inserted is greater than about 2KB ( That is, the of the page 1/4) When , It will start automatically TOAST Technology to store the tuple .TOAST Slightly more complex than ordinary tuples , This is mainly for the description of ordinary tuple files .

Tuples can be divided into three parts , Namely : Heap tuple header (23 byte )、NULL Value bitmap and Data stored by users .

Pageinspect Expand
PostgreSQL In the source directory contrib Many extended functions are provided under ,pageinspect The function provided by the extension module allows you to observe the contents of the database page from a low level , This is useful for debugging purposes .
install
#cd $PGSRC/contrib/pageinspect
#make
#sudo make install
Easy to use
#psql -d test
test=#create extension pageinspect; -- For the first time, you need to create Extension
-- Create test table
drop table if exists t1;
create table t1 (id int, name varchar(20));
insert into t1 values(1,'aaa');
-- see page header&item
SELECT * FROM page_header(get_raw_page('t1', 0));

select * from heap_page_items(get_raw_page('t1',0));

-- Update a row of data
update t1 set name='bbb' where id=1;

see heap_page_items(), Found one more item, as a result of PG Updating data does not modify the original tuple, Instead, insert a new tuple, And mark the original tuple.t_xmax= new tuple The business of id.
边栏推荐
- After QQ was stolen, a large number of users "died"
- 笔试面试算法经典–最长回文子串
- 石油化工行业供应链系统驱动管理模式创新升级,强化企业内部管理
- [JS] Fibonacci sequence implementation (recursion and loop)
- Leetcode 48. Rotate image (yes, resolved)
- Does Frankfurt currently support SQL?
- 如何从零搭建10万级 QPS 大流量、高并发优惠券系统
- Is PMP really useful?
- 新零售线下店逆势起飞,通膨乌云下的消费热情
- web Worker 轮询请求
猜你喜欢

3. caller service call - dapr
PostgreSQL 存储结构浅析

石油化工行业供应链系统驱动管理模式创新升级,强化企业内部管理

【黑马早报】腾讯回应大批用户QQ号被盗;薇娅丈夫公司被罚19万;中国恒大被申请清盘;关晓彤奶茶店回应被加盟商起诉...

Flutter简单实现多语言国际化

教育行业SaaS应用管理平台解决方案:助力企业实现经营、管理一体化

环保产品“绿色溢价”高?低碳生活方式离人们还有多远

With 120billion yuan, she will ring the bell for IPO again

论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
Yiwen teaches you to quickly generate MySQL database diagram

随机推荐
Fleet | background Discovery issue 3: Status Management
Oracle11g database uses expdp to back up data every week and upload it to the backup server
Vector explanation + topic
SAP MTS/ATO/MTO/ETO专题之九:M+M模式前后台操作,策略用50,提前准备原材料和半成品
[JS] Fibonacci sequence implementation (recursion and loop)
Flutter简单实现多语言国际化
With 120billion yuan, she will ring the bell for IPO again
Not being a meta universe now is like not buying a house 20 years ago!
Experiment 6 8255 parallel interface experiment [microcomputer principle] [experiment]
[C language] nextday problem
Facebook! Adaptive gradient defeats manual parameter adjustment
Could you tell me whether the batch addition of Oracle such as insert all was not blocked?
5000倍回报,南非报业投资腾讯赚了一个省
Spark SQL generate JSON
halcon 基础总结(一)裁切图片并旋转图像
C#/VB. Net to convert PDF to excel
华为能成“口红一哥”,或者“带货女王”吗?
Halcon basic summary (I) cutting pictures and rotating images
Calculator (force buckle)
R语言ggplot2可视化:使用patchwork包(直接使用加号+)将两个ggplot2可视化结果横向组合起来形成单个可视化结果图